library(tidyverse)
library(sf)
library(jpstat)12: 重力モデル
はじめに
今回の演習では、重力モデルについて学びます。 重力モデルは、人々の移動の発生頻度と距離との関係を分析する、最もプリミティブなモデルの1つです。
今回は、佐賀市と久留米市への通勤者数のデータを使って、通勤者数と距離の関係を分析することで、両市の特徴について議論します。
重力モデル
地域\(i\)から地域\(j\)への通勤者数は、
- 地域\(i\)に就業者(仕事に就いている人)が多いほど、
- 地域\(j\)の従業者(そこで働いている人)が多いほど、
- 地域\(i\)と地域\(j\)が近いほど
多くなりそうです。
1と2は地域の大きさ、3は地域間の距離が、それぞれ影響していることを示唆しています。
ところで、大きさと距離でその間の関係性が決まる物理法則に、万有引力の法則があります。
万有引力の法則
質量\(M\)の物体と質量\(m\)の物体の間に働く万有引力の大きさ\(F\)は、物体間の距離が\(d\)のとき、 \[ F=G\frac{Mm}{d^2} \] です(\(G\)は万有引力定数)。
質量≒大きさと距離が重要な要素になっています。 これからヒントを得て、地域間の社会移動を説明する重力モデルが着想されます。
(古典的)重力モデル
地域\(i\)のから地域\(j\)への移動量\(t_{ij}\)は、それぞれの地域の魅力度を\(R_i\)、\(S_j\)、地域間の距離を\(d_{ij}\)としたとき、 \[ t_{ij}=k\frac{R_iS_j}{d_{ij}^2} \] と推定されます(\(k\)は比例定数)。
(古典的)重力モデルでは、地域間の移動量は、地域の魅力\(R_i\)と\(S_j\)に正比例し、距離\(d_{ij}\)の2乗に反比例しています。 しかし、正比例・2乗に反比例というのは、万有引力の法則に倣ったに過ぎません。 実際の移動に当てはめるには、地域の魅力や距離が移動量に与える影響は、移動の種類などによって異なると考えた方が良さそうです。 そこで、(古典的)重力モデルを拡張した(修正)重力モデルが提案されました。
(修正)重力モデル
地域\(i\)のから地域\(j\)への移動量\(t_{ij}\)は、それぞれの地域の魅力度を\(R_i\)、\(S_j\)、地域間の距離を\(d_{ij}\)としたとき、 \[ t_{ij}=k\frac{R_i^\alpha S_j^\beta}{d_{ij}^\gamma} \] と推定されます(\(k\)は比例定数、\(\alpha\)、\(\beta\)、\(\gamma\)はパラメータ)。
現在では「重力モデル」というと、(修正)重力モデルのことを指すことが多いです。
重力モデルは、万有引力の法則に倣ったとても単純なモデルですが、現実の移動によく当てはまることが、多くの実証研究によって示されています。
距離・移動モデル
今回の演習では、重力モデルを簡略化した以下のモデルを考えます。
地域\(i\)から地域\(j\)への通勤者数\(t_{ij}\)は、地域\(i\)の就業者数を\(R_i\)、地域\(j\)の従業者数を\(S_j\)、地域間の距離を\(d_{ij}\)とするとき、 \[ t_{ij}=k\frac{R_iS_j}{d_{ij}^\alpha} \] に従うものとします。さらに、次のように変形します。 \[ \begin{align} \frac{t_{ij}}{R_i}&=k\frac{S_j}{d_{ij}^\alpha}\\ f_{ij}&=\frac{\beta}{d_{ij}^\alpha} \end{align} \] ここで、\(f_{ij}\)は地域\(i\)の就業者のうち地域\(j\)への通勤者の比率を表しています。 このようなモデルを距離・移動モデルと呼ぶことがあります。
さて、この式の両辺の対数をとると、 \[ \log(f_{ij})=\log(\beta)-\alpha\log(d_{ij}) \] となります。
\(\log(f_{ij})=Y\)、\(\log(\beta)=b\)、\(-\alpha=a\)、\(\log(d_{ij})=X\)とおくと、上式は
\[ Y=aX+b \] という一次式であることがわかります。つまり、線形(単)回帰分析によってパラメータ\(a\)、\(b\)を求めることができます。 \(a\)と\(b\)が分かれば、元のパラメータは、\(\alpha=-a\)、\(\beta=\exp(b)\)として求めることができます。
準備
パッケージ
今回の演習では、以下のパッケージを使用します。 library関数を使ってロードしてください。
データの入手
空間データの入手
国土数値情報から、 福岡県、佐賀県、長崎県、熊本県、大分県の「行政区域データ」と「市町村役場等及び公的集会施設データ」 をダウンロードしてください。
合計10個のZIPファイルのダウンロードが完了したら、それぞれダウンロードフォルダで展開し、できた10個のフォルダを全てプロジェクトのdataフォルダに移動してください。
空間データの読み込み
空間データを読み込みます。
まず、福岡県、佐賀県、長崎県、熊本県、大分県の行政区域データを読み込みます。 これは、塗り分け地図を作成するために使います。
5県のデータを、
# 福岡県の行政界データのみ読み込む場合
fukuoka <- read_sf("data/N03-20250101_40_GML/N03-20250101_40.geojson")などとして、これを5回繰り返してもいいのですが、今日は少し違った方法でファイルを読み込んでみましょう。
read_sf関数
read_sf関数は、st_read関数のラッパー関数です。 コンソールにread_sfと入力しenterキーを押すと、
function (..., quiet = TRUE, stringsAsFactors = FALSE, as_tibble = TRUE)
{
st_read(..., quiet = quiet, stringsAsFactors = stringsAsFactors,
as_tibble = as_tibble)
}と表示され、read_sf関数の中でst_read関数を呼び出していることがわかります。 st_read関数との最も大きな違いは、デフォルトでquiet = TRUEとなっていることです。 つまり、実行時にデータソースについての情報を表示しません。
まず、読み込むGeoJSONファイルのリストを作ります。
# 行政界データのファイルリスト
reg_files <- str_c("data/N03-20250101_", seq(40, 44),
"_GML/N03-20250101_", seq(40, 44), ".geojson")
reg_files[1] "data/N03-20250101_40_GML/N03-20250101_40.geojson"
[2] "data/N03-20250101_41_GML/N03-20250101_41.geojson"
[3] "data/N03-20250101_42_GML/N03-20250101_42.geojson"
[4] "data/N03-20250101_43_GML/N03-20250101_43.geojson"
[5] "data/N03-20250101_44_GML/N03-20250101_44.geojson"stringr::str_c関数は、複数の文字列を1つの文字列に結合する関数です。 seq関数は連続する数字のベクトルを作る関数です。 ここでは、40から44までの整数のベクトルを作成します。 つまり、seq(40, 44)は、c(40, 41, 42, 43, 44)と同じ結果を返します。
この2つの関数を組み合わせて、GeoJSONファイルのリストを作成します。
purrr::map関数は、ベクトルの要素に対して、1つずつ関数を適用するための関数です。 ここでは、reg_filesの要素、つまり読み込むべきGeoJSONのファイル名を1つずつsf::read_sf関数に渡して、それぞれのファイルを読み込みます。
# 行政界データの読み込み
region <- reg_files |>
map(read_sf) |>
bind_rows()読み込んだ結果、5つのsfオブフェクト(データフレームでもある)のリストが出来上がるのですが、それに対して、dplyr::bind_rows関数を適用することで、1つの大きなsfオブジェクト(データフレーム)に結合しています。
次に、読み込んだ地図を、自治体ごとにまとめます。 この行政区域データは、1つの自治体が複数のポリゴンから成り立っています。 これを1つのデータに集約するために、dplyr::group_by関数とdplyr::summarise関数を使った空間データに対する集計を実行します(少し時間がかかります)。 また、北九州空港の近くに「羽島」という小さな島があるのですが、これが所属未定地なので、このデータを取り除いています。
# 行政界データを市町村単位に統合
region <- region |>
filter(N03_004 != "所属未定地") |>
st_make_valid() |>
group_by(N03_001, N03_004, N03_007) |>
summarise(.groups = "drop") |> ungroup()
glimpse(region)Rows: 180
Columns: 4
$ N03_001 <chr> "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県"…
$ N03_004 <chr> "みやき町", "上峰町", "伊万里市", "佐賀市", "吉野ヶ里町", "唐津市", "基山町", "多久市", "…
$ N03_007 <chr> "41346", "41345", "41205", "41201", "41327", "41202", "41341"…
$ geometry <GEOMETRY [°]> POLYGON ((130.44 33.39886, ..., POLYGON ((130.4206 3…北部九州5県には、180の自治体があることがわかります。 国土数値情報の行政区域データは、塗り分け地図を作成するという用途には細かすぎるので、 sf::st_simplify関数を使って単純化しておきます(データ量も減らせます)。 そして、平面直角座標系II系に投影変換しておきます。
# 行政界データの簡略化・投影変換
region <- region |>
st_simplify(dTolerance = 100) |>
st_transform(6670) |>
select(origin_code = N03_007, geometry)次に、自治体間の距離を計算するために、市区町村役場のポイントデータを読み込みます。 行政区域データでやったのと同じように、GeoJSONファイル名のリストを作成して、 purrr::map関数で順番に読み込みます。
# 役場データの読み込み
loc_files <- str_c("data/P05-22_", seq(40, 44),
"_GML/P05-22_", seq(40, 44), ".geojson")
location <- loc_files |>
map(read_sf) |>
bind_rows()読み込んだ市区町村役場のデータから、まず、本庁舎だけのデータに(支所等のデータを削除)します。 自治体コードと施設名のデータをそれぞれorigin_codeとnameにdplyr::renameし、 stringr::str_remove関数を使って、施設名から「役所」「役場」の文字列を削除たものを自治体名として使います。
# 役場データの整形
location <- location |> filter(P05_002 == 1) |>
select(origin_code = P05_001, name = P05_003, geometry) |>
mutate(name = str_remove(name, "役所|役場"))政令指定都市については、区(区役所)のデータを使うことにして、「指令指定都市の市役所」のデータは取り除いておきます。 また、福岡県那珂川町は2018年に市政施行し那珂川市)に変わっていますが、那珂川町役場のデータが残っていますので、これも併せて削除しておきます。
# 政令指定都市のデータを削除
location <- location |>
filter(name != "福岡市", name != "北九州市", name != "熊本市", name != "那珂川町") |>
st_transform(6670)読み込んだ境界データと役所データを地図にしてみましょう。
# 九州北部5県の役場地図
ggplot() +
geom_sf(data = region) +
geom_sf(data = location) +
theme_minimal()
他市区町村就業者数と通勤者数
e-statから、国勢調査のデータを入手します。
e-stat API利用のためのアプリケーションIDの取得
以下では、e-Stat APIを利用したデータ取得の演習を行います。 そのために、以下のページの内容にしたがって、各自でe-Statのユーザー登録を行い、アプリケーションIDを取得してください。
アプリケーションIDの管理
アプリケーションIDは、e-Statのマイページに行けば確認することができますが、いちいち確認するためにe-Statにログインするのも手間です。 アプリケーションIDは暗記するには長すぎますし、かといって、RスクリプトファイルにアプリケーションIDをそのまま書き込んでしまうのも不安です。 このような場合には、OSが用意しているパスワード管理システム1を利用すると便利です。 ここでは、keyringパッケージを利用したアプリケーションIDの管理方法を紹介します。
アプリケーションIDの登録
RStudioのコンソール(Console)ペインに、以下のコマンドを入力します(「“e-stat”」の部分は、登録したアプリケーションIDを呼び出すためのキーですので、好きな文字列にしても構いません)。
keyring::key_set("e-stat")すると、パスワードを入力するウィンドウが開きますので、e-StatのページにあるアプリケーションIDをコピーして、入力欄にペーストしましょう。 そして[OK]ボタンをクリックすれば、登録完了です。 この情報は、自分でパスワード管理システムを操作して情報を削除しない限り、PC内部に暗号化された形で永続的に保持されます。
さて、jpstatパッケージを使って、e-Statのデータを取得する準備をします。 jpstatパッケージでは、アプリケーションIDを環境変数に登録する必要があります。 ここでは、アプリケーションIDを直接入力するのではなく、keyring::key_get関数を使って、パスワード管理システムに登録したアプリケーションIDを呼び出しています(このとき、もしかしたら、パスワードの入力を求められるかもしれませんが、その場合は適切なパスワードを入力してください)。
# e-Stat appIdの設定
Sys.setenv(ESTAT_API_KEY = keyring::key_get("e-stat"))これで、e-Stat APIを使う準備が整いましたので、早速、データを取得してみましょう。
他市区町村就業者数
jpstatパッケージを利用してe-Statからデータを取得するには、取得したいデータの統計表表示IDを把握する必要があります。 今回の他市区町村就業者数のデータは、男女,年齢(5歳階級),常住地又は従業地・通学地別就業者数-全国,都道府県,市区町村という統計表から取得します。 この統計表の統計表表示IDは”0003454500”ですので、jpstat::estat関数のstatsDataId引数にこれを与えます。 これで、統計表のメタデータを取得することができます。
# 就業者数データ(メタデータ)の取得
worker <- estat(statsDataId = "0003454500")
worker# ☐ tab: 表章事項 [1] <code, name, level, unit>
# ☐ cat01: 男女 [3] <code, name, level>
# ☐ cat02: 年齢 [25] <code, name, level>
# ☐ cat03: 常住地又は従業地・通学地 [19] <code, name, level>
# ☐ area: 全国,都道府県,市区町村 [1,965] <code, name, level, parentCode>
# ☐ time: 時間軸(年次) [1] <code, name, level>
#
# Please `activate()`.e-Stat APIを使ったデータ抽出では、表彰事項、カテゴリー(年齢、性別など、統計表によって異なる)、地域、時間軸ごとにデータが格納されているので、データが必要なカテゴリー項目を設定する必要があります。 そのために、設定項目ごとに、navigatr::activate(必要であればnavigatr::rekeyも)とdplyr::filterを繰り返し適用して、最後にdplyr::collectでデータを取得します。
例えば、cat03の「常住地又は従業地・通学地」にどのよう表章項目があるのかみてみましょう。
worker |>
activate(cat03)# ☐ tab: 表章事項 [1] <code, name, level, unit>
# ☐ cat01: 男女 [3] <code, name, level>
# ☐ cat02: 年齢 [25] <code, name, level>
# ☒ cat03: 常住地又は従業地・通学地 [19] <code, name, level>
# ☐ area: 全国,都道府県,市区町村 [1,965] <code, name, level, parentCode>
# ☐ time: 時間軸(年次) [1] <code, name, level>
#
# A tibble: 19 × 4
# Stickers: .estat_rowid
.estat_rowid code name level
* <int> <chr> <chr> <chr>
1 1 0 常住地による人口 1
2 2 001 従業も通学もしていない 2
3 3 002 自市区町村で従業・通学 2
4 4 0021 自宅で従業 3
5 5 0022 自宅外の自市区町村で従業・通学 3
6 6 003 他市区町村で従業・通学 2
7 7 0031 自市内他区で従業・通学 3
8 8 0032 県内他市町村で従業・通学 3
9 9 0033 他県で従業・通学 3
10 10 0034 従業・通学市区町村「不詳・外国」 3
11 11 004 従業地・通学地「不詳」 2
12 12 0R1 (再掲)流出人口 2
13 13 1 従業地・通学地による人口 1
14 14 101 うち他市区町村に常住 2
15 15 1011 自市内他区に常住 3
16 16 1012 県内他市町村に常住 3
17 17 1013 他県に常住 3
18 18 102 うち従業地・通学地「不詳」又は従業・通学市区町村「不詳・外国」で当地に常住している者…… 2
19 19 1R1 (再掲)流入人口 2 必要な項目はcodeが003の「他市区町村で従業・通学」であることがわかります。
worker <- worker |>
activate(tab) |> select() |>
activate(cat01) |> rekey("gender") |> select(name) |>
activate(cat02) |> filter(name == "総数") |> select() |>
activate(cat03) |> filter(code == "003") |> select() |>
activate(area) |> rekey("origin") |> select(code) |>
activate(time) |> select() |>
collect(n = "worker") |>
mutate(worker = parse_number(worker, na = "-"))The total number of data is 5895.rekey |
filter |
select |
|
|---|---|---|---|
| tab | |||
| cat01 | gender | name | |
| cat02 | “総数”のみ | ||
| cat03 | “他市区町村で従業・通学”のみ | ||
| area | origin | code | |
| time |
ここでの処理内容を表に整理しています。
- 表彰事項(tab)には処理はしていません。なので、最終的なデータには含まれません。
- カテゴリー1(cat01)の項目名をgenderにしています。データとして、name(日本語文字列:“総数”、“男”、“女”)を取得します。
- カテゴリー2(cat02)の年齢は、“総数”データだけを取得するフィルタリングに利用しています。
- カテゴリー3(cat03)は、“他市区町村で従業・通学”しているデータだけを取り出します。
- 地域(area)は、名前をoriginにしたうえで、code(自治体コード)を取得します。
- 時間軸(time)も、tabと同様にデータから落とします。
最後に、readr::parse_number関数を使って就業者数を文字列から数値にしています。
dplyr::glimpse関数で、取得したデータの内容を確認してみましょう。
# 就業者データの確認
glimpse(worker)Rows: 5,895
Columns: 3
$ gender_name <chr> "総数", "総数", "総数", "総数", "総数", "総数", "総数", "総数", "総数", "総数"…
$ origin_code <chr> "00000", "01000", "01100", "01101", "01102", "01103", "011…
$ worker <dbl> 25015142, 694338, 417629, 28085, 61207, 53219, 47849, 5929…通勤者数
通勤者数のデータは、男女,就業・通学,常住地(全国,都道府県,市区町村)別就業者・通学者数-全国[総数],都道府県,市区町村(従業地・通学地)という統計表から取得します。 この統計表の統計表表示IDは”0003454525”ですので、jpstat::estat関数のstatsDataId引数にこれを与えます。 これで、統計表のメタデータを取得することができます。
# 通勤データ(メタデータ)の取得
commuter <- estat(statsDataId = '0003454525')
commuter# ☐ tab: 表章事項 [1] <code, name, level, unit>
# ☐ cat01: 男女 [3] <code, name, level>
# ☐ cat02: 常住地 [11] <code, name, level>
# ☐ cat03: 全国,都道府県,市区町村(常住地) [1,965] <code, name, level, parentCode>
# ☐ cat04: 就業・通学 [5] <code, name, level>
# ☐ area: 全国[総数],都道府県,市区町村(従業地・通学地) [1,965] <code, name, level, parentCode>
# ☐ time: 時間軸(年次) [1] <code, name, level>
#
# Please `activate()`.先ほどの就業者データと同様に、activateとfilterを繰り返し適用してデータを取得します。
# 通勤データの取得
commuter <- commuter |>
activate(tab) |> select() |>
activate(cat01) |> rekey('gender') |> select(name) |>
activate(cat02) |> filter(name == '他市区町村に常住') |> select() |>
activate(cat03) |> rekey('origin') |> select(code) |>
activate(cat04) |> filter(name == '15歳以上就業者') |> select() |>
activate(area) |> rekey('destination') |> filter(name %in% c('佐賀市', '久留米市')) |> select(name) |>
activate(time) |> select() |>
collect(n = "commuter") |>
mutate(commuter = parse_number(commuter, na = "-"))The total number of data is 11790.rekey |
filter |
select |
|
|---|---|---|---|
| tab | |||
| cat01 | gender | name | |
| cat02 | “他市区町村に常住”のみ | ||
| cat03 | origin | code | |
| cat04 | “15歳以上就業者”のみ | ||
| area | destination | “佐賀市”または”久留米市” | name |
| time |
ここでの処理内容を表に整理しています。
# 通勤データの確認
glimpse(commuter)Rows: 11,790
Columns: 4
$ gender_name <chr> "総数", "総数", "総数", "総数", "総数", "総数", "総数", "総数", "総数",…
$ origin_code <chr> "00000", "00000", "01000", "01000", "01100", "01100",…
$ destination_name <chr> "久留米市", "佐賀市", "久留米市", "佐賀市", "久留米市", "佐賀市", "久留米市", …
$ commuter <dbl> 36433, 31163, NA, 1, NA, NA, NA, NA, NA, NA, NA, NA, …データの可視化
性別の他市区町村就業者数の塗り分け地図を作ってみましょう。
# 他市区町村就業者数の確認
region_w <- region |>
left_join(worker, by = join_by(origin_code))
glimpse(region_w)Rows: 540
Columns: 4
$ origin_code <chr> "41346", "41346", "41346", "41345", "41345", "41345", "412…
$ geometry <MULTIPOLYGON [m]> MULTIPOLYGON (((-52012.98 4..., MULTIPOLYGON …
$ gender_name <chr> "総数", "男", "女", "総数", "男", "女", "総数", "男", "女", "総数", "男",…
$ worker <dbl> 7050, 3915, 3135, 3051, 1621, 1430, 5685, 3276, 2409, 2065…行数が540になっているのは、市町村数(180)の3倍です。 性別の種類が3(“総数”、“男”、“女”)なので、left_joinしたことで、自動的に540行のデータになっています。
ggplotで地図にしてみましょう。 ggplot2::scale_fill_gradient関数のtrans引数を"log10"にすることで、 塗り分けの軸を常用対数にしています。 また、ggplot2::facet_wrap関数で、性別の種類(“総数”、“男”、“女”)ごとの地図を並べて表示しています。
# 他市区町村就業者数の塗り分け地図
ggplot() + geom_sf(aes(fill = worker), data = region_w) +
scale_fill_gradient(low = 'white', high = 'blue', trans = 'log10') +
facet_wrap(vars(gender_name)) +
theme_bw()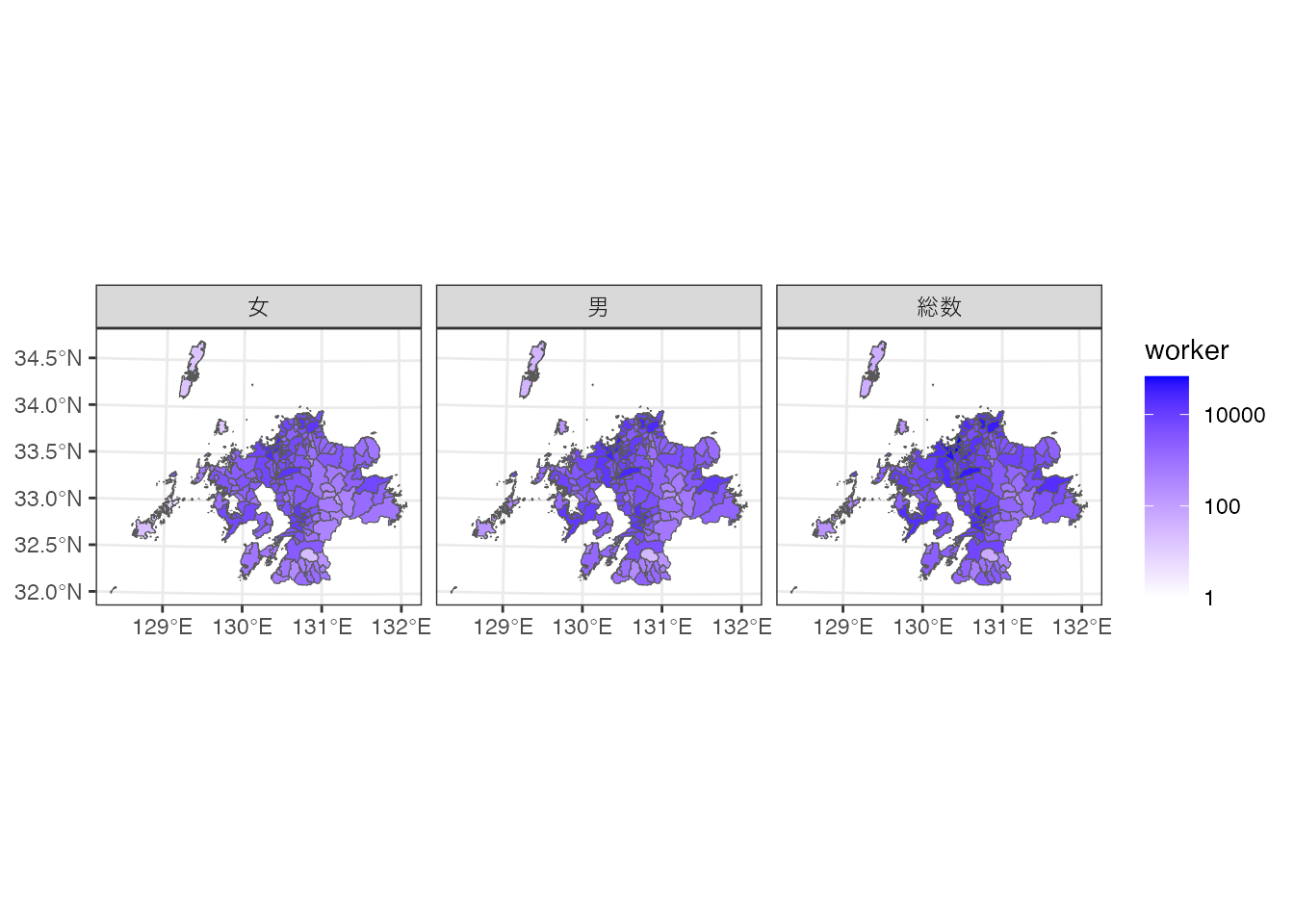
次に、佐賀市・久留米市への通勤者数による塗り分け地図を作ってみましょう。
# 佐賀市・久留米市への通勤者数データの確認
region_c <- region |>
left_join(commuter, by = join_by(origin_code))
glimpse(region_c)Rows: 1,080
Columns: 5
$ origin_code <chr> "41346", "41346", "41346", "41346", "41346", "41346",…
$ geometry <MULTIPOLYGON [m]> MULTIPOLYGON (((-52012.98 4..., MULTIPOL…
$ gender_name <chr> "総数", "総数", "男", "男", "女", "女", "総数", "総数", "男", "男",…
$ destination_name <chr> "久留米市", "佐賀市", "久留米市", "佐賀市", "久留米市", "佐賀市", "久留米市", …
$ commuter <dbl> 1537, 874, 748, 499, 789, 375, 290, 455, 143, 236, 14…left_joinの結果、今度はデータの列数が1,080になっていますね。 これは、性別の3区分に加えて、目的地の2区分(“佐賀市”、“久留米市”)が加わったために、3×2で6倍になるためです。
# 佐賀市・久留米市への通勤者数による塗り分け地図
ggplot() + geom_sf(aes(fill = commuter), data = region_c) +
scale_fill_gradient(low = 'white', high = 'red', trans = 'log10') +
facet_grid(cols = vars(gender_name), rows = vars(destination_name)) +
theme_bw()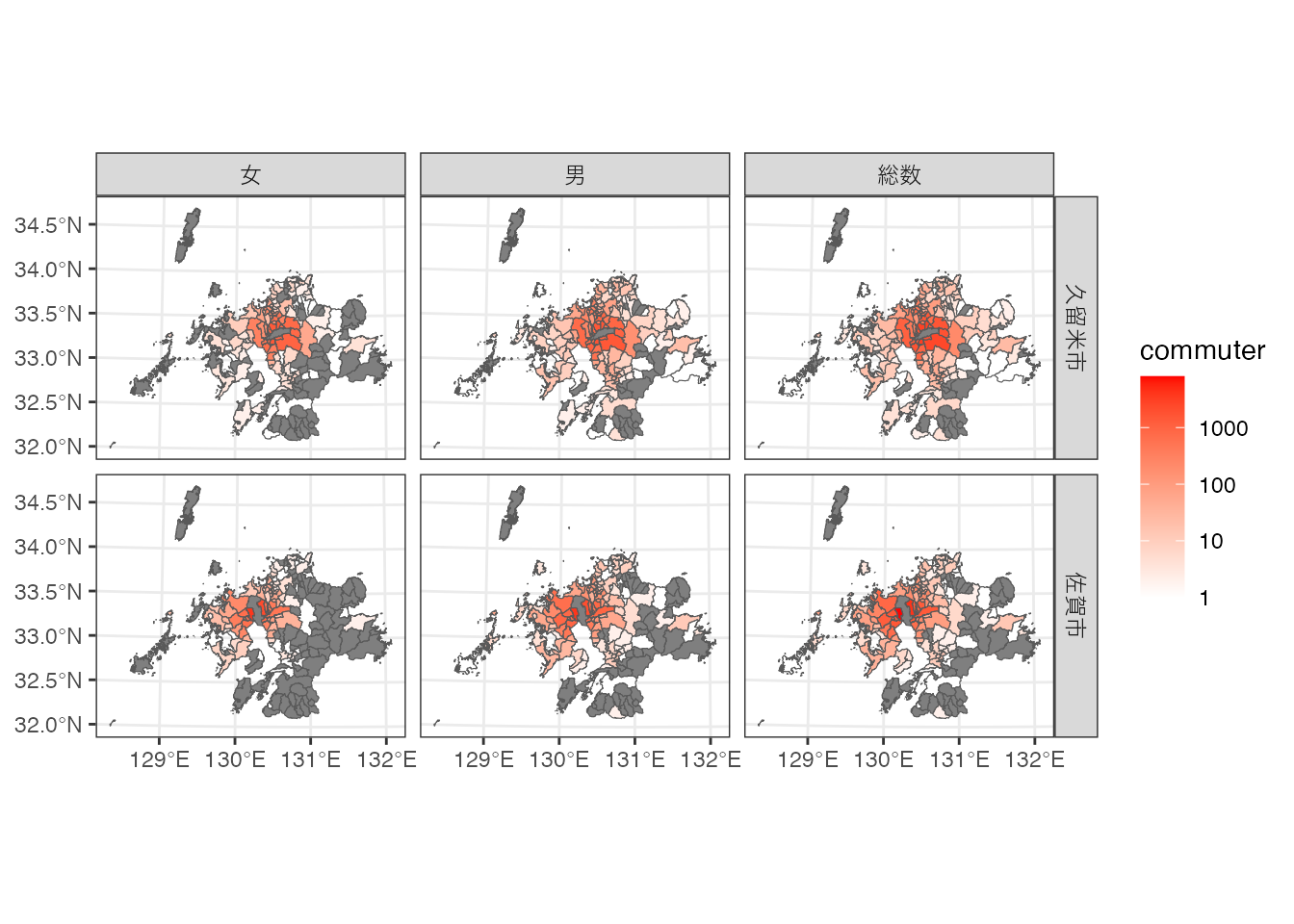
佐賀市・久留米市までの距離
各市区町村から佐賀市・久留米市までの通勤者数と距離との関係を分析するために、 各市区町村から佐賀市・久留米市までの距離のデータが必要です。 ここでは、sf::st_distanceを使って計算しています。
locationデータに、佐賀市の座標情報であるsaga_geom列と、久留米市の座標情報であるkurume_geom列を追加します。 あとは、locationの市区町村との距離をsf::st_distance関数で計算するだけです。 計算に使用したsaga_geom列とkurume_geom列を削除し、最後にsf::st_drop_geometry関数でポイントデータではない距離データを持つ、distanceという名前のデータフレームにしています。
# 各市区町村から佐賀市・久留米市への距離の計算
saga <- location |> filter(name == "佐賀市")
kurume <- location |> filter(name == "久留米市")
distance <- location |>
mutate(
saga_geom = st_geometry(saga),
kurume_geom = st_geometry(kurume),
佐賀市 = st_distance(location, saga_geom, by_element = TRUE),
久留米市 = st_distance(location, kurume_geom, by_element = TRUE)
) |>
select(-saga_geom, -kurume_geom) |>
st_drop_geometry()このデータを「tidy」なデータ形式にしておきます。 tidyr::pivot_longer関数を使って、佐賀市と久留米市の2つのデータ列を、cityというデータ列(佐賀市または久留米市のどちらかの文字列がデータとして入る)とdistanceというデータ列(佐賀市または久留米市までの距離がデータとして入る)に再編しています。 その後、距離を1,000で割ることで、距離の単位をmからkmに変換しています。
# 距離データをtidy形式に変換
distance <- distance |>
pivot_longer(佐賀市:久留米市, names_to = 'destination_name', values_to = 'distance') |>
mutate(distance = units::drop_units(distance) / 1000)
glimpse(distance)Rows: 360
Columns: 4
$ origin_code <chr> "40101", "40101", "40103", "40103", "40105", "40105",…
$ name <chr> "門司区", "門司区", "若松区", "若松区", "戸畑区", "戸畑区", "小倉北区", "小倉…
$ destination_name <chr> "佐賀市", "久留米市", "佐賀市", "久留米市", "佐賀市", "久留米市", "佐賀市", "…
$ distance <dbl> 97.04116, 80.68667, 85.71155, 70.82886, 85.57652, 70.…tidyr::pivot_longer
tidyr::pivot_longerは、「tidy」なデータを作るためには不可欠で便利な関数ですが、 最初はどのような働きをするのかイメージしにくいと思います。 tidyrのCheatsheet にある図がわかりやすいかもしれません。
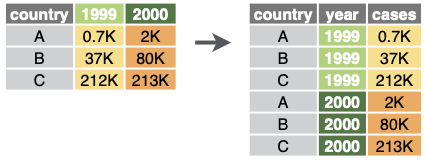
逆にlong型のデータをwide型に変換する関数はtidyr::pivot_widerです。
距離と通勤率との関係
距離と通勤率との関係を見てみます。
dplyr::left_join関数を使って、行政区域データに、就業者数、通勤者数、距離のデータを結合します。 さらに、dplyr::mutate関数を使って、通勤者比率(=通勤者÷就業者)のデータ列を追加します。
# すべてのデータを結合
region_d <- region |>
left_join(worker, by = join_by(origin_code)) |>
left_join(commuter, by = join_by(origin_code, gender_name)) |>
left_join(distance, by = join_by(origin_code, destination_name)) |>
mutate(rate = commuter / worker)
glimpse(region_d)Rows: 1,080
Columns: 9
$ origin_code <chr> "41346", "41346", "41346", "41346", "41346", "41346",…
$ geometry <MULTIPOLYGON [m]> MULTIPOLYGON (((-52012.98 4..., MULTIPOL…
$ gender_name <chr> "総数", "総数", "男", "男", "女", "女", "総数", "総数", "男", "男",…
$ worker <dbl> 7050, 7050, 3915, 3915, 3135, 3135, 3051, 3051, 1621,…
$ destination_name <chr> "久留米市", "佐賀市", "久留米市", "佐賀市", "久留米市", "佐賀市", "久留米市", …
$ commuter <dbl> 1537, 874, 748, 499, 789, 375, 290, 455, 143, 236, 14…
$ name <chr> "みやき町", "みやき町", "みやき町", "みやき町", "みやき町", "みやき町", "", "…
$ distance <dbl> 5.044407, 15.849471, 5.044407, 15.849471, 5.044407, 1…
$ rate <dbl> 0.218014184, 0.123971631, 0.191060026, 0.127458493, 0…ggplot2::ggplotを使って、距離と通勤者比率の散布図を描きましょう。 ggplot2::facet_grid関数を使って、都市(佐賀市と久留米市)と性別ごとの散布図にします。
# 通勤距離と通勤率の関係
ggplot(region_d, aes(x = distance, y = rate)) +
geom_point() +
facet_grid(rows = vars(destination_name), cols = vars(gender_name)) +
theme_bw()Warning: Removed 335 rows containing missing values or values outside the scale range
(`geom_point()`).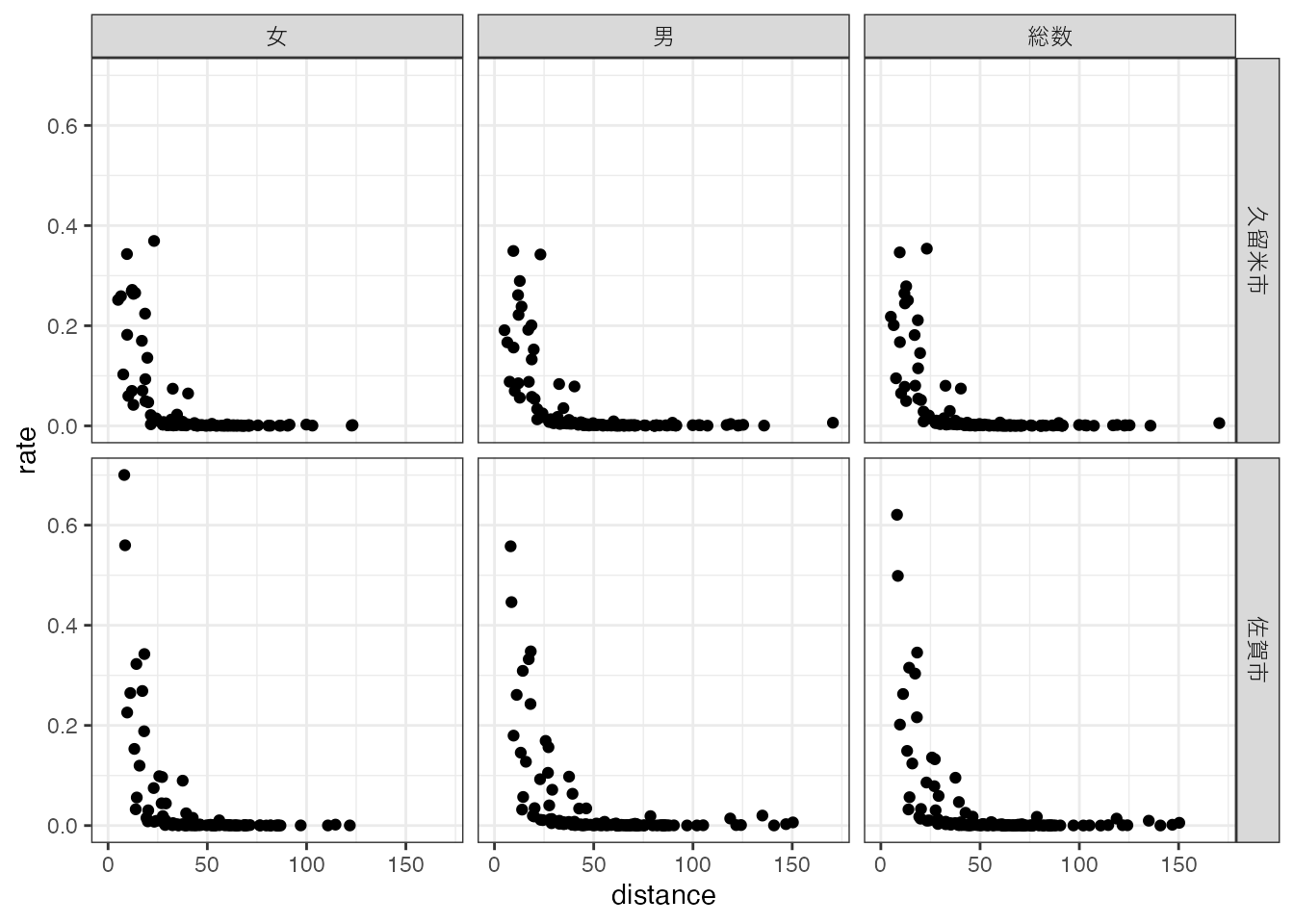
距離が遠くなるほど、通勤者比率が減少しているように見えますが、点が軸に張り付いているようにみえ、両者にどのような関係があるのかよくわかりません。 そこで、このような場合の常套手段として、x軸とy軸を対数軸にしてみます。
# 通勤距離と通勤率の関係(対数軸)
ggplot(region_d, aes(x = distance, y = rate)) +
geom_point() +
scale_y_log10() + scale_x_log10() +
facet_grid(rows = vars(destination_name), cols = vars(gender_name)) +
theme_bw()Warning in scale_x_log10(): log-10 transformation introduced infinite values.Warning: Removed 335 rows containing missing values or values outside the scale range
(`geom_point()`).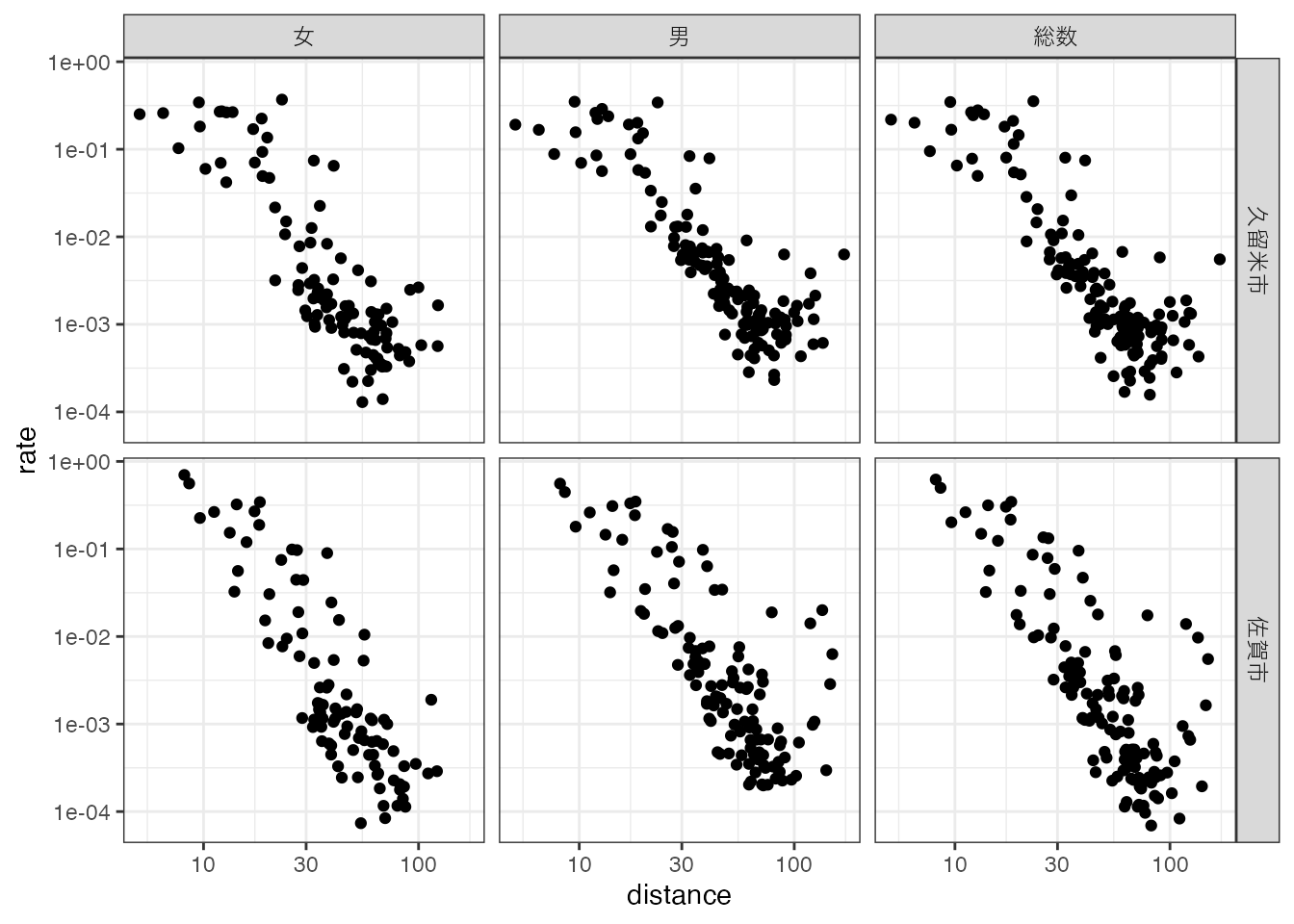
両対数をとると、散布図は右下がりの線分に沿っているように見えます。 そこで、ggplot2::geom_smooth関数を使って、回帰直線を表示してみましょう。
# 回帰直線の描画
ggplot(region_d, aes(x = distance, y = rate)) +
geom_point() +
scale_y_log10() + scale_x_log10() +
geom_smooth(method = lm, se = FALSE) +
facet_grid(rows = vars(destination_name), cols = vars(gender_name)) +
theme_bw() Warning in scale_x_log10(): log-10 transformation introduced infinite values.
log-10 transformation introduced infinite values.`geom_smooth()` using formula = 'y ~ x'Warning: Removed 335 rows containing non-finite outside the scale range
(`stat_smooth()`).Warning: Removed 335 rows containing missing values or values outside the scale range
(`geom_point()`).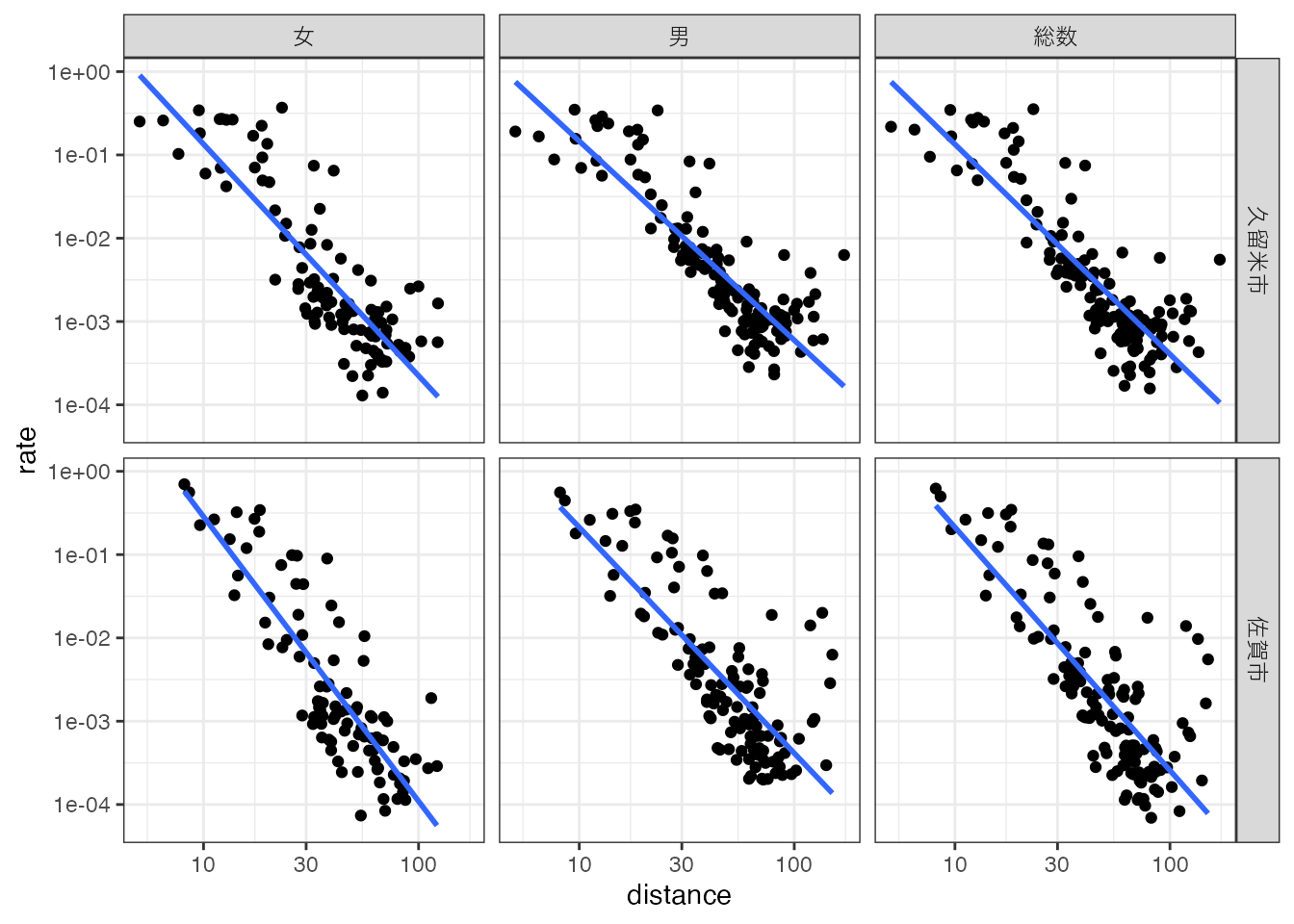
回帰係数を確認してみましょう。 都市と性別でデータをグループ化し、tidyr::nest関数を使って、グループ化したデータフレームをリスト型の列の要素にしてしまいます。 そのネストしたデータフレームに対して、順番に回帰分析(lm関数)を実行し、その結果をlm列に格納しています(purrr::mapを使って処理しています)。 さらに回帰分析の結果を、broom::tidy関数でtidyな形式に変換したものをcoef列に追加し、 最後にtidyr::unnestでcoefをアンネスト(ネストを解除)しています。
# 回帰係数
region_d |>
group_by(destination_name, gender_name) |>
nest() |>
mutate(lm = map(data, function(x){lm(log(rate) ~ log(distance), data = x)})) |>
mutate(coef = map(lm, broom::tidy)) |>
unnest(coef)# A tibble: 12 × 9
# Groups: destination_name, gender_name [6]
gender_name destination_name data lm term estimate std.error statistic
<chr> <chr> <list> <list> <chr> <dbl> <dbl> <dbl>
1 総数 久留米市 <sf> <lm> (Int… 3.80 0.492 7.72
2 総数 久留米市 <sf> <lm> log(… -2.52 0.127 -19.8
3 総数 佐賀市 <sf> <lm> (Int… 5.17 0.783 6.61
4 総数 佐賀市 <sf> <lm> log(… -2.92 0.200 -14.6
5 男 久留米市 <sf> <lm> (Int… 3.59 0.455 7.89
6 男 久留米市 <sf> <lm> log(… -2.39 0.118 -20.3
7 男 佐賀市 <sf> <lm> (Int… 4.70 0.770 6.10
8 男 佐賀市 <sf> <lm> log(… -2.71 0.198 -13.7
9 女 久留米市 <sf> <lm> (Int… 4.40 0.630 6.98
10 女 久留米市 <sf> <lm> log(… -2.78 0.170 -16.3
11 女 佐賀市 <sf> <lm> (Int… 6.61 0.803 8.23
12 女 佐賀市 <sf> <lm> log(… -3.42 0.215 -15.9
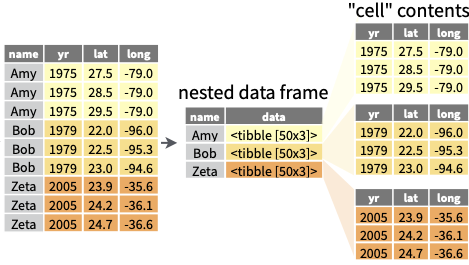
# ℹ 1 more variable: p.value <dbl>tidyr::nest
tidyr::nestとtidyr::unnestについても、Cheatsheet の図を貼り付けておきます。 参考にしてください。
 n
n 
線形回帰の結果を表にまとめると、以下のようになります。 \(\beta\)については、回帰の係数(\(b\))ではなく\(\exp(b)\)の値であることに注意してください。
| 都市 | 性別 | \(\beta\) | \(\alpha\) |
|---|---|---|---|
| 久留米市 | 女 | 81.34652 | 2.780654 |
| 久留米市 | 男 | 36.05946 | 2.390588 |
| 久留米市 | 総数 | 44.55006 | 2.520781 |
| 佐賀市 | 女 | 744.36591 | 3.416006 |
| 佐賀市 | 男 | 109.67832 | 2.712030 |
| 佐賀市 | 総数 | 176.53639 | 2.918836 |
\(\beta\)はその都市が通勤者を惹きつける力(魅力)のようなものを表しています。 \(\alpha\)は距離の影響に関するパラメータで、値が大きいほど距離が効く(距離が遠くなると通勤者比率が大きく減る)ことを意味しています。
この結果表を見ると、佐賀市においても、久留米市においても、女性の方が男性よりも\(\alpha\)も\(\beta\)も大きいことがわかります。 女性は男性に比べ遠くに通勤しないが、近場であれば他市区町村への通勤を厭わない、と解釈できるかもしれません。
性別による回帰直線を重ねて表示すると、次の図のようになります。
# 性別による回帰直線
ggplot(region_d, aes(x = distance, y = rate, color = gender_name)) +
geom_point() +
scale_y_log10() + scale_x_log10() +
geom_smooth(method = "lm", se = FALSE) +
facet_wrap(vars(destination_name)) +
theme_bw()Warning in scale_x_log10(): log-10 transformation introduced infinite values.
log-10 transformation introduced infinite values.`geom_smooth()` using formula = 'y ~ x'Warning: Removed 335 rows containing non-finite outside the scale range
(`stat_smooth()`).Warning: Removed 335 rows containing missing values or values outside the scale range
(`geom_point()`).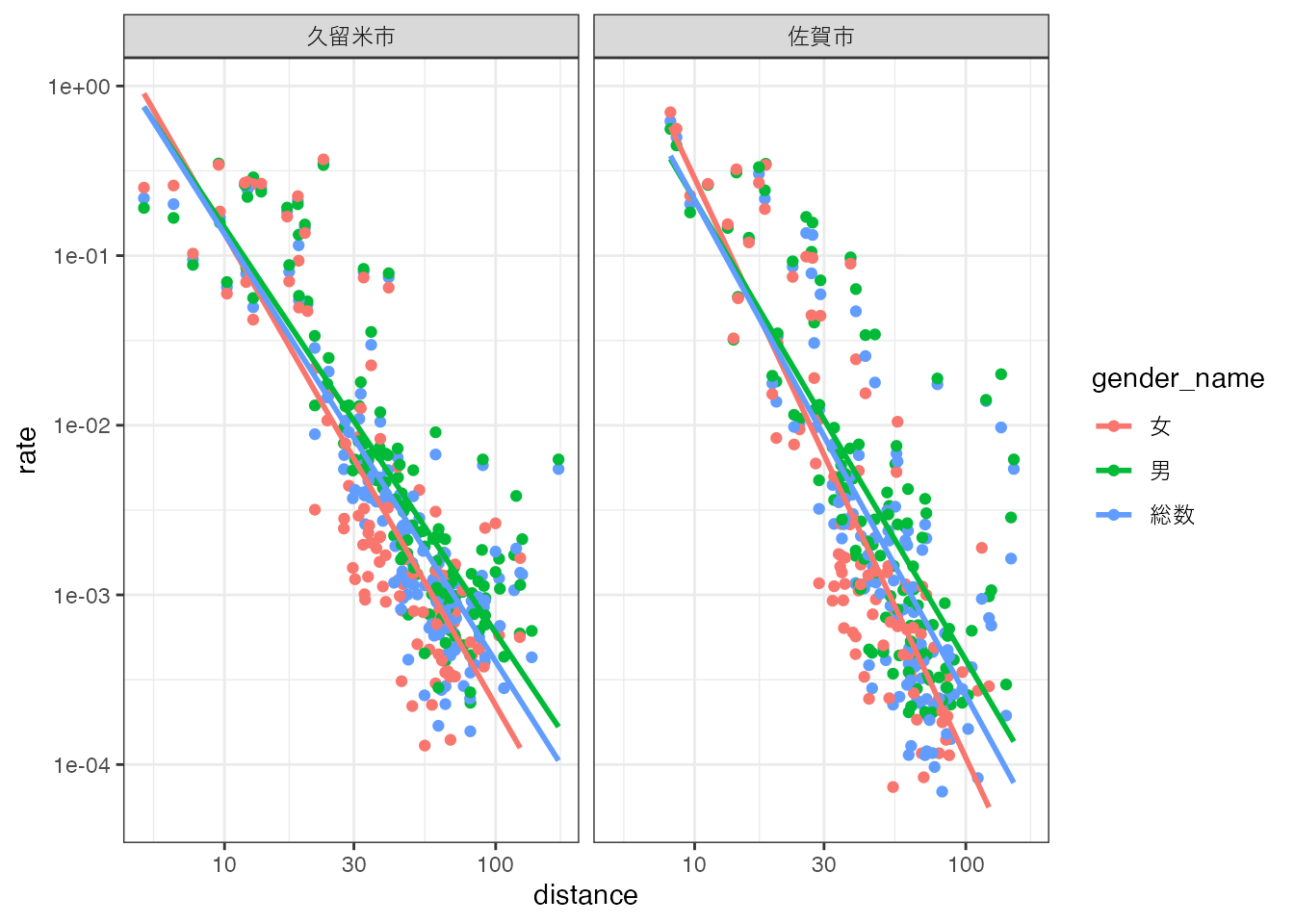
また、いずれの性別においても、久留米市に比べて佐賀市の\(\alpha\)及び\(\beta\)が大きくなっています。 佐賀市の方が久留米市よりも市外からの通勤者を惹きつけるが、遠くからの通勤者比率は少なくなる、という結果になりました。
通勤先都市による回帰直線を重ねて表示すると、次の図のようになります。
# 通勤先による回帰直線
ggplot(region_d, aes(x = distance, y = rate, color = destination_name)) +
geom_point() +
scale_y_log10() + scale_x_log10() +
geom_smooth(method = "lm", se = FALSE) +
facet_wrap(vars(gender_name)) +
theme_bw() Warning in scale_x_log10(): log-10 transformation introduced infinite values.
log-10 transformation introduced infinite values.`geom_smooth()` using formula = 'y ~ x'Warning: Removed 335 rows containing non-finite outside the scale range
(`stat_smooth()`).Warning: Removed 335 rows containing missing values or values outside the scale range
(`geom_point()`).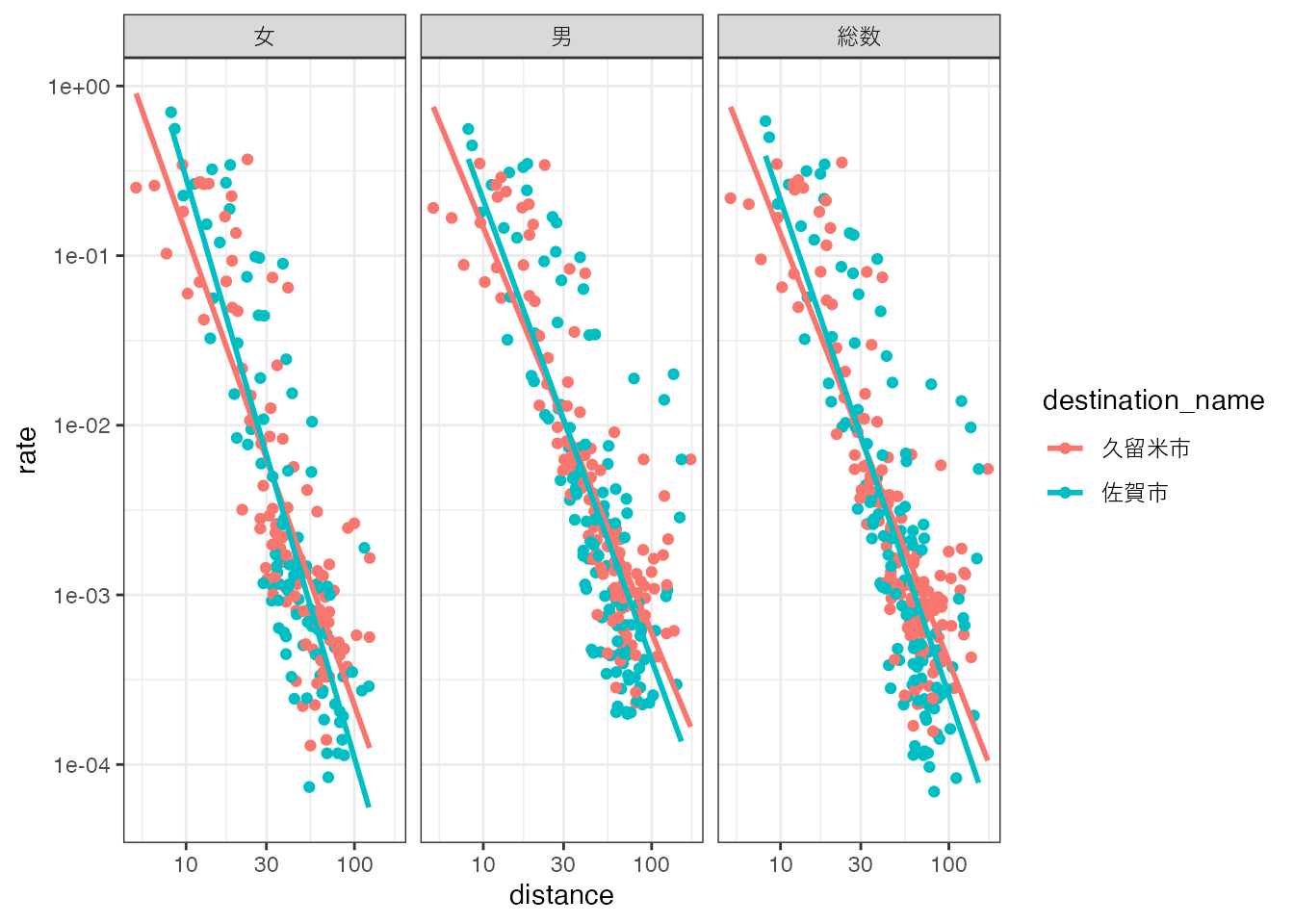
おわりに
今回は、重力モデルについて実際にデータを操作しながら、その雰囲気を味わってもらいました。 重力モデルといいつつ、実際にはそれを簡略化した形(距離・移動モデル)ですが、距離と移動との関係を体感していただけたのではないかと思います。
脚注
Windowsでは資格情報マネージャー、MacOSではキーチェーンアクセスが該当します。↩︎