# パッケージのロード
library(tidyverse)
library(sf)
library(jpgrid)9: 地域メッシュ統計
はじめに
今回も、これまでの講義内容の復習を兼ねて、Rを使った立地分析の演習を行います。 今日の演習では、いろいろな空間データをつかって、佐賀市内のコンビニエンスストアの立地について考えてみることにします。
今日の分析では、新たにjpgridパッケージを使いますので、インストールしてください。 そして、以下のlibrary関数を実行して、使用するパッケージをロードしてください。
コンビニエンスストアのデータ
コンビニエンスストア(以下、コンビニと呼びます)のポイントデータは、無料で手に入るものはありませんので、購入するか自分で作成するかする必要があります。 今回の演習では、皆さんに協力していただいて作成したGeoJSONファイルがありますので、これを使いましょう1。
GeoJSONファイルをダウンロードし、プロジェクトのdataフォルダに移動してください。 これをsf::st_read関数で読み込みます。
# コンビニ店舗データの読み込み
cvs <- st_read("data/saga_cvs_2025_rev.geojson")Reading layer `saga_cvs_2025_rev' from data source
`/Users/kzktmr/Documents/LectureNotes/EconomicGeography/data/saga_cvs_2025_rev.geojson'
using driver `GeoJSON'
Simple feature collection with 419 features and 4 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: -112338.5 ymin: -4359.17 xmax: -43117.11 ymax: 60117.67
Projected CRS: JGD2011 / Japan Plane Rectangular CS IIglimpse(cvs)Rows: 419
Columns: 5
$ name <chr> "ザ・イースト", "セブンイレブンみやき江口店", "セブンイレブンみやき町三根店", "セブンイレブンみやき町原古賀店…
$ brand <chr> "その他", "セブンイレブン", "セブンイレブン", "セブンイレブン", "セブンイレブン", "セブンイレブン",…
$ address <chr> "佐賀県武雄市武雄町大字武雄5066-3", "佐賀県三養基郡みやき町江口2954-11", "佐賀県三養基郡みやき町大字…
$ city <chr> "武雄市", "みやき町", "みやき町", "みやき町", "みやき町", "みやき町", "みやき町", "みやき町"…
$ geometry <POINT [m]> POINT (-91028.94 21248.34), POINT (-48252.92 35589.18),…このデータには、佐賀県内の419件のコンビニの店名と位置情報が入っています。
チェーンごとのコンビニ立地件数を確認してみましょう。
# 県内コンビニチェーンのランキング
cvs |>
count(brand) |>
arrange(desc(n))Simple feature collection with 7 features and 2 fields
Geometry type: MULTIPOINT
Dimension: XY
Bounding box: xmin: -112338.5 ymin: -4359.17 xmax: -43117.11 ymax: 60117.67
Projected CRS: JGD2011 / Japan Plane Rectangular CS II
brand n geometry
1 セブンイレブン 206 MULTIPOINT ((-108702.1 3293...
2 ローソン 80 MULTIPOINT ((-107361 31150....
3 ファミリーマート 79 MULTIPOINT ((-112338.5 3783...
4 ヤマザキショップ 18 MULTIPOINT ((-103427.2 3000...
5 その他 17 MULTIPOINT ((-94758.23 3425...
6 ミニストップ 12 MULTIPOINT ((-80417.45 2439...
7 デイリーヤマザキ 7 MULTIPOINT ((-109112.1 3329...佐賀県内のコンビニは、セブンイレブンが最も多く、次いでローソン、ファミリーマートの順になっています。
今日の分析に使うのは佐賀市内の店舗だけですので、dplyr::filter関数を使って、市内の店舗だけを抜き出しておきましょう。
# 佐賀市内のコンビニエンスストアデータ
cvs <- cvs |> filter(city == "佐賀市")
glimpse(cvs)Rows: 114
Columns: 5
$ name <chr> "セブンイレブン久保田新田店", "セブンイレブン佐賀三瀬店", "セブンイレブン佐賀久保泉工業団地入口店", "セブンイ…
$ brand <chr> "セブンイレブン", "セブンイレブン", "セブンイレブン", "セブンイレブン", "セブンイレブン", "セブンイレ…
$ address <chr> "佐賀県佐賀市久保田町大字新田字久富3798-1", "佐賀県佐賀市三瀬村三瀬2898番2", "佐賀県佐賀市久保泉町大字…
$ city <chr> "佐賀市", "佐賀市", "佐賀市", "佐賀市", "佐賀市", "佐賀市", "佐賀市", "佐賀市", "佐賀市"…
$ geometry <POINT [m]> POINT (-70636.25 24653.17), POINT (-67120.59 47348.05),…佐賀市内114件のコンビニエンスストアの位置を地図にしてみましょう。
背景地図として、佐賀市のポリゴンデータを用意します。 佐賀県オープンデータカタログサイトから、佐賀県の市町村ポリゴンデータをダウンロードしましょう。 ファイル名を「410004saga.geojson」に変更したら、今日のプロジェクトのdataフォルダに移動してください。
st_read関数で読み込んだ後、filter関数で佐賀市のポリゴンだけを抜き出します。
# 背景地図(佐賀市)の読み込み
saga_city <-
st_read('data/410004saga.geojson') |>
filter(GST_NAME == '佐賀市') |>
st_transform(6670)Reading layer `410004saga' from data source
`/Users/kzktmr/Documents/LectureNotes/EconomicGeography/data/410004saga.geojson'
using driver `GeoJSON'
Simple feature collection with 20 features and 4 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 129.7368 ymin: 32.95054 xmax: 130.5424 ymax: 33.6189
Geodetic CRS: WGS 84ggplotで地図にしてみましょう。
# 佐賀市内のコンビニ地図
ggplot() +
geom_sf(data = saga_city) +
geom_sf(aes(color = brand), data = cvs) +
theme_minimal()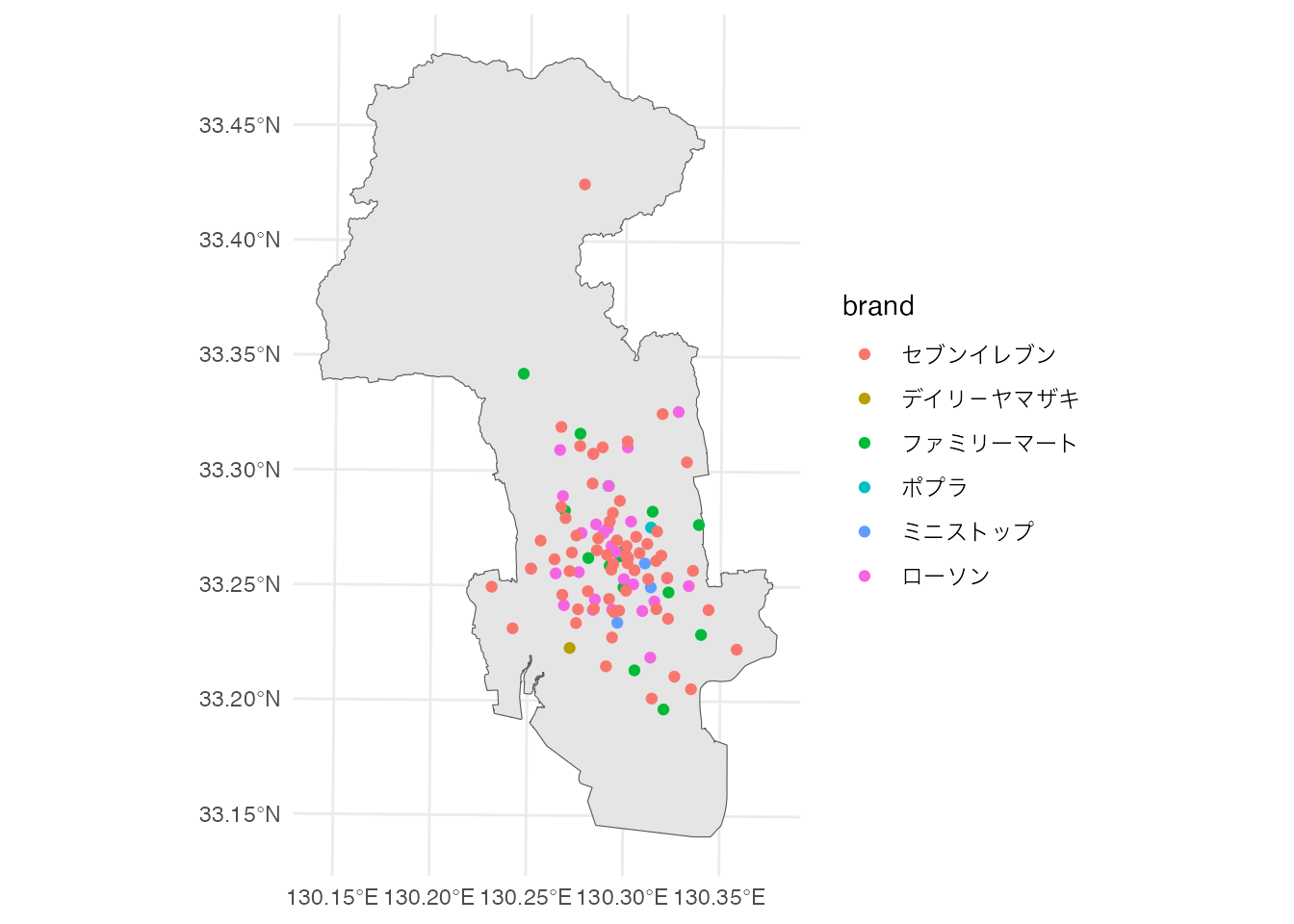
佐賀市のコンビニは、そのほとんどが市南部の平野部に集中していることがわかります。
コンビニエンスストアの周辺人口の確認
都市部のコンビニの商圏は、徒歩5分の範囲であるといわれます。 佐賀市のコンビニストアについて、商圏人口がどのくらいいるのかを調べてみましょう。
人口データは国勢調査の基本単位区データを使いましょう。e-Statページにアクセスして、 基本単位区の境界データをダウンロードしてください。
- 境界データダウンロード
- [小地域]→[国勢調査]→[2020年]→[小地域(基本単位区)(JGD2011)]→[世界測地系平面直角座標系・Shapefile]→[41 佐賀県]→[41201 佐賀市]からダウンロード
- 境界データ(B002005212020XYSWC41201-JGD2011.zip)を展開してできたフォルダを、プロジェクトのdataフォルダに移動
- ダウンロードページへのダイレクトリンクはこちら
ダウンロードした境界データを、sf::st_read関数を使って読み込みます。
# 基本単位区境界データの読み込み
district <-
st_read('data/B002005212020XYSWC41201-JGD2011/r2kb41201.shp')Reading layer `r2kb41201' from data source
`/Users/kzktmr/Documents/LectureNotes/EconomicGeography/data/B002005212020XYSWC41201-JGD2011/r2kb41201.shp'
using driver `ESRI Shapefile'
Simple feature collection with 3835 features and 37 fields
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: -80084.88 ymin: 15840.25 xmax: -57844.26 ymax: 53682.39
Projected CRS: JGD2011 / Japan Plane Rectangular CS IIコンビニの商圏人口を調べるために、
- コンビニの徒歩5分(≒350 m)のバッファーを作成
- バッファーに代表点が含まれる基本単位区の人口を集計する
という操作を行います。 まず、基本単位区はポリゴンデータですから、sf::st_centroid関数を使って図形代表点のポイントデータに変換します。
# 基本単位区のポリゴンデータをポイントデータに
pop <- district |> st_centroid()Warning: st_centroid assumes attributes are constant over geometriessf::st_buffer関数を使って、コンビニの350 mバッファーを作成します。
# コンビニ店舗から350mのバッファーを作成
buffer <- cvs |>
st_buffer(dist = 350)コンビニのバッファーと基本単位区の代表点を重ねて地図にしてみましょう。
# 地図に表示しバッファーを確認
p <- ggplot() +
geom_sf(data = saga_city) +
geom_sf(aes(fill = JINKO), data = district, color = NA) +
geom_sf(data = pop, size = 0.1, alpha = 0.5) +
geom_sf(data = buffer, color = 'red', fill = NA) +
scale_fill_distiller(direction = 1) +
theme_minimal()
p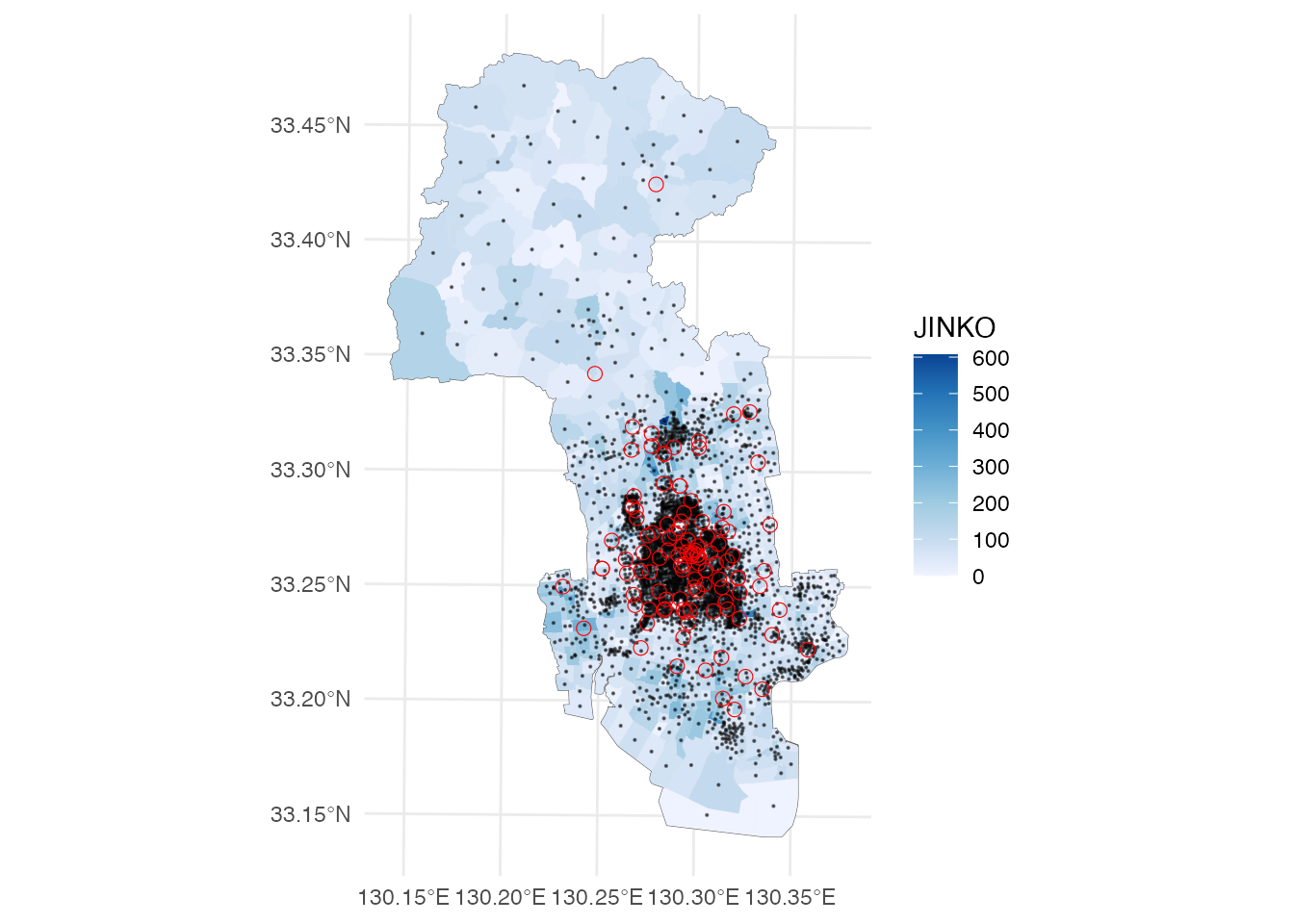
佐賀市中心部を拡大してみます。
p + xlim(-70000, -60000) + ylim(25000, 35000)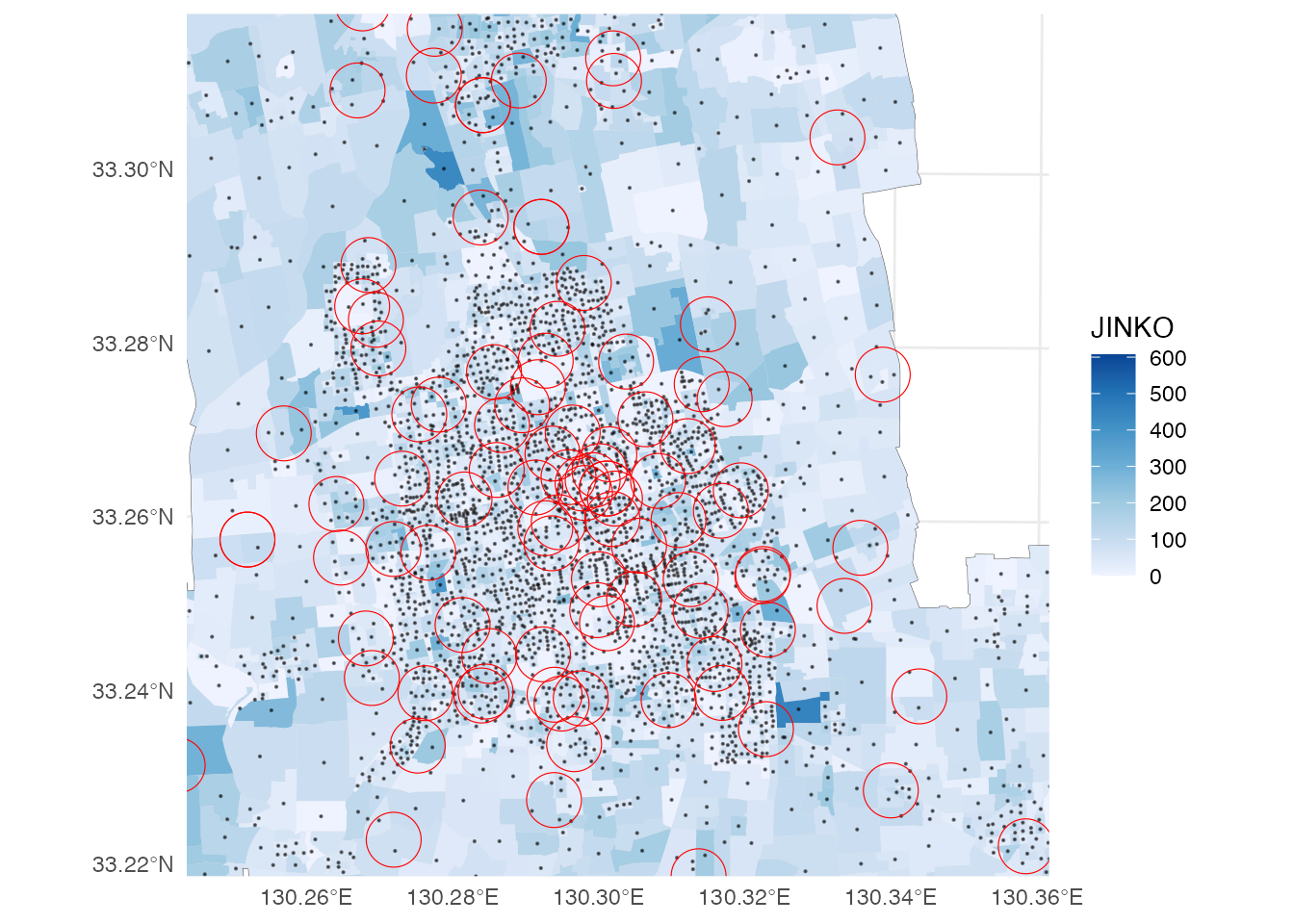
それぞれの店舗の350 mバッファー(商圏)に、たくさんの基本単位区(の図形重心)が含まれていることがわかると思います。
ヒント
xlimやylim関数には、それぞれx軸とy軸の範囲(下限値と上限値)を与える必要があります。投影変換後の座標のあたりをつけるためには、st_bbox関数が便利かもしれません。
st_bbox(saga_city) xmin ymin xmax ymax
-80084.89 15840.25 -57844.26 53682.39 この結果と図を見比べると、およその見当がつけられると思います。
それでは、店舗の商圏に含まれる基本単位区の人口(商圏人口)を集計してみましょう。 sf::st_join関数と、group_byとsummarise関数を組み合わせて使います。
sf::st_joinは、空間結合のための関数で、空間データどうしのleft_join関数に相当します。 ここでは、コンビニ商圏のポリゴンデータに対して、そのポリゴンと交わる基本単位区代表点のポイントデータを全て結合します。 そしてgroup_by関数を使ってコンビニごとにグルーピングした上で、summarise関数を使って、商圏ごとに、交わる基本単位区の人口を合計しています。
# コンビニ店舗の商圏人口
market <- buffer |>
st_join(pop) |>
group_by(name) |>
summarise(population = sum(JINKO))
market |> arrange(desc(population))Simple feature collection with 114 features and 2 fields
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: -71976.77 ymin: 21643.1 xmax: -59447.42 ymax: 47698.05
Projected CRS: JGD2011 / Japan Plane Rectangular CS II
# A tibble: 114 × 3
name population geometry
<chr> <int> <POLYGON [m]>
1 ファミリーマートJR佐賀駅店 2600 ((-65100.58 29509.74, -65101.0…
2 ローソン佐賀若楠三丁目店 2557 ((-66230.2 30930.74, -66230.68…
3 セブンイレブン佐賀兵庫北店 2490 ((-63758.9 29986.41, -63759.38…
4 ファミリーマート佐賀駅南口店 2433 ((-65070.87 29388.87, -65071.3…
5 ローソン佐賀高伝寺前店 2430 ((-66390.74 26804.54, -66391.2…
6 セブンイレブン佐賀駅前中央2丁目店 2422 ((-64759.35 29882.63, -64759.8…
7 ミニストップ佐賀田代2丁目店 2417 ((-63594.61 27884.37, -63595.0…
8 セブンイレブン佐賀高木瀬東2丁目店 2407 ((-65423.24 31483.4, -65423.72…
9 セブンイレブン佐賀南本庄店 2364 ((-66338.53 26854.67, -66339.0…
10 セブンイレブン佐賀医大通り店 2350 ((-67705.79 31232.43, -67706.2…
# ℹ 104 more rowsこの結果を使って、商圏人口(population)で色をつけて地図にしてみましょう。
# 店舗の商圏人口地図
ggplot() +
geom_sf(data = saga_city) +
geom_sf(aes(fill = population), data = market) +
scale_fill_distiller(direction = 1) +
theme_minimal()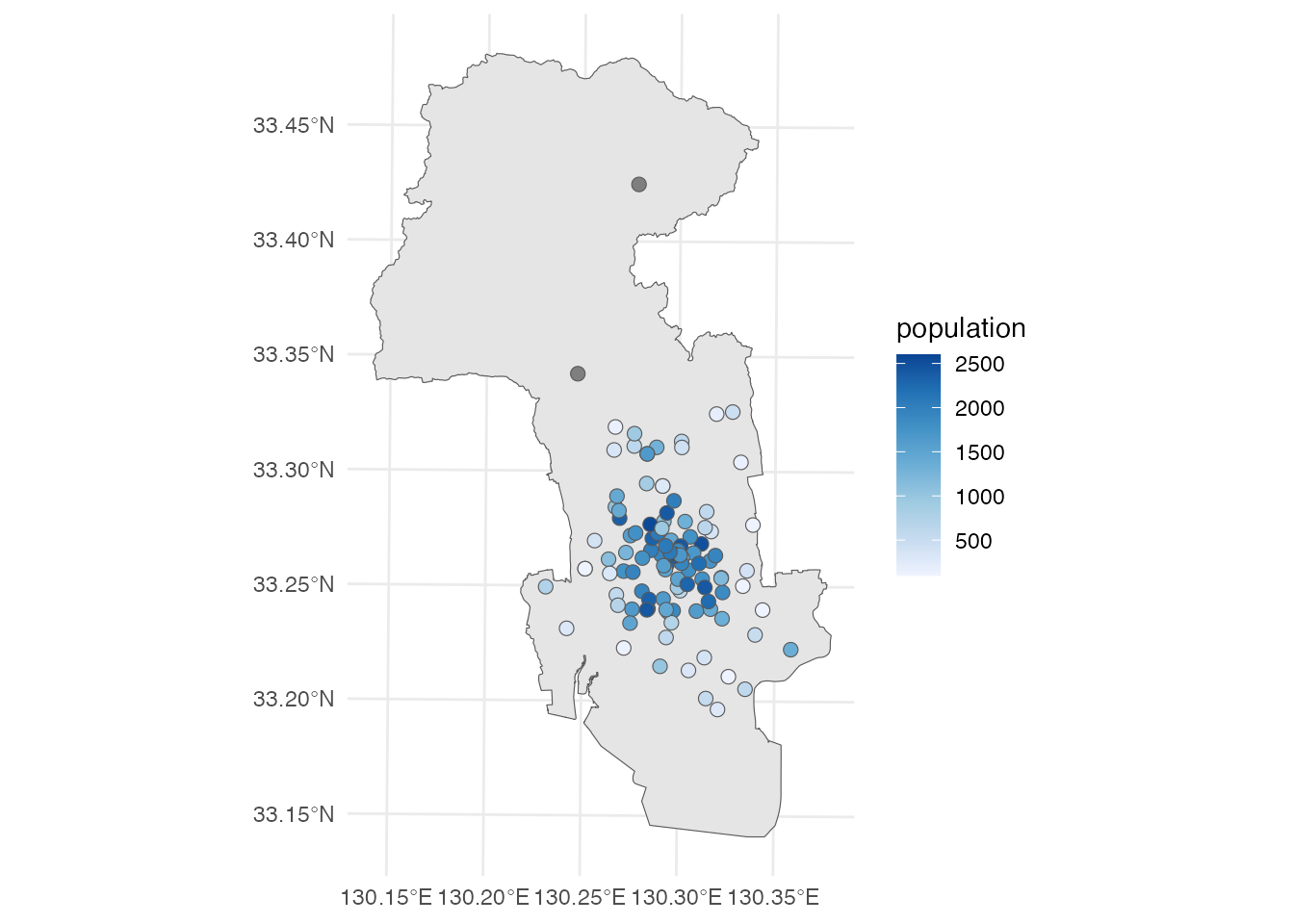
地図を見ると、店舗によってその商圏人口はまちまちですが、人口密度の高い市中心部の店舗の商圏人口が多い傾向にあることがわかります。
佐賀市内のコンビニについて、商圏人口の分布はどのようになっているでしょうか? ggplotを使って、ヒストグラムを書いてみましょう。
# 商圏人口のヒストグラム
ggplot(aes(x = population), data = market) +
geom_histogram(boundary = 0, binwidth = 200) +
theme_minimal()Warning: Removed 2 rows containing non-finite outside the scale range
(`stat_bin()`).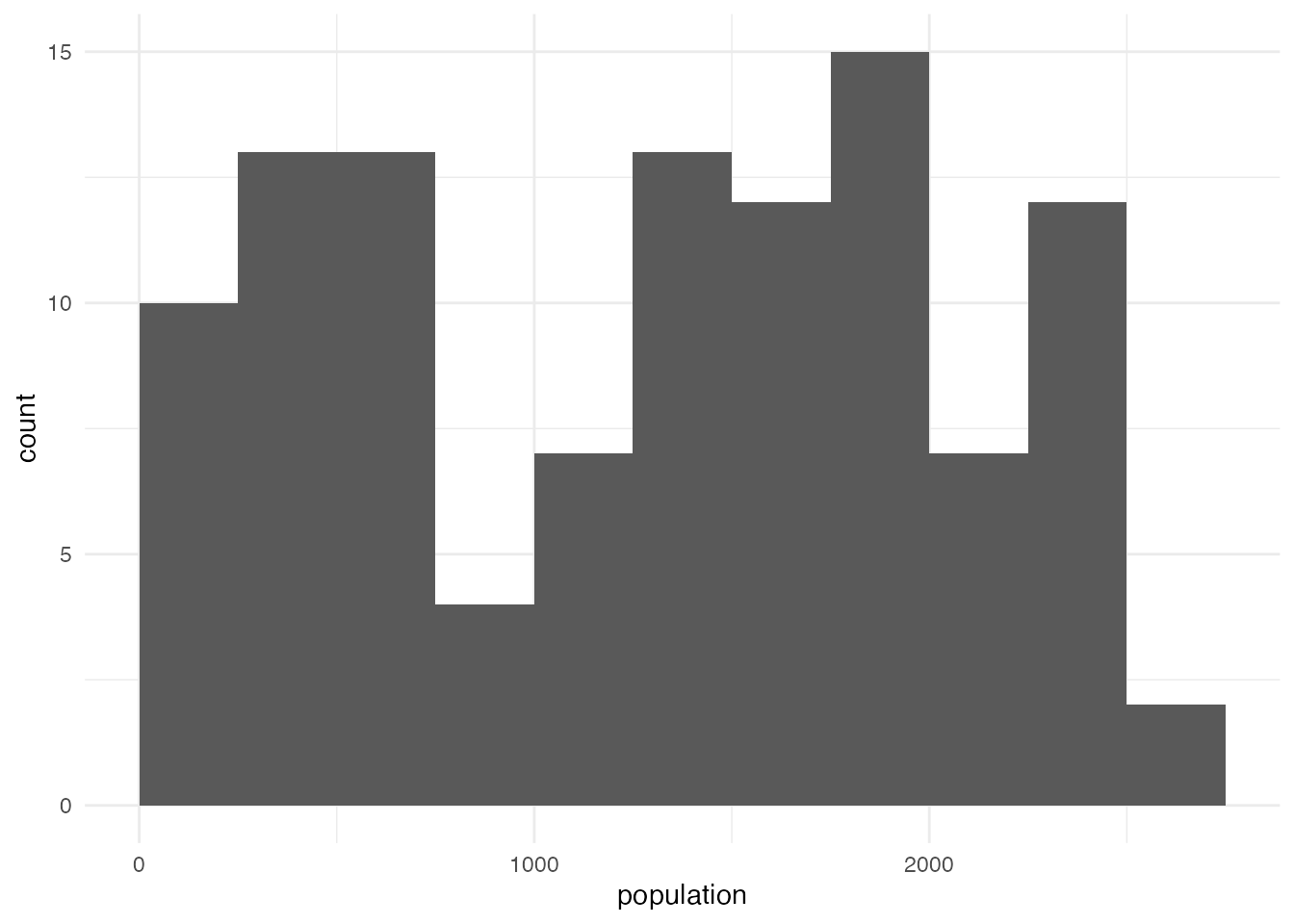
佐賀市のコンビニ立地においては、半径350 mの範囲に1,000人の人口がいるかどうかで、店舗立地の傾向が分かれそうな気がします。 ということで、商圏人口1,000人を閾値にして、地図を書いてみましょう。 mutate関数を使って、人口が1,000人よりも多ければTRUE、そうでなければFALSEとなるようなデータ列locationを作成し、locationを使って色を塗り分けた地図を描いてみます。
# 商圏人口が1,000人を超える店舗はどこにあるか
market <- market |>
mutate(location = population > 1000)
ggplot() +
geom_sf(data = saga_city) +
geom_sf(aes(fill = location), data = market) +
theme_minimal()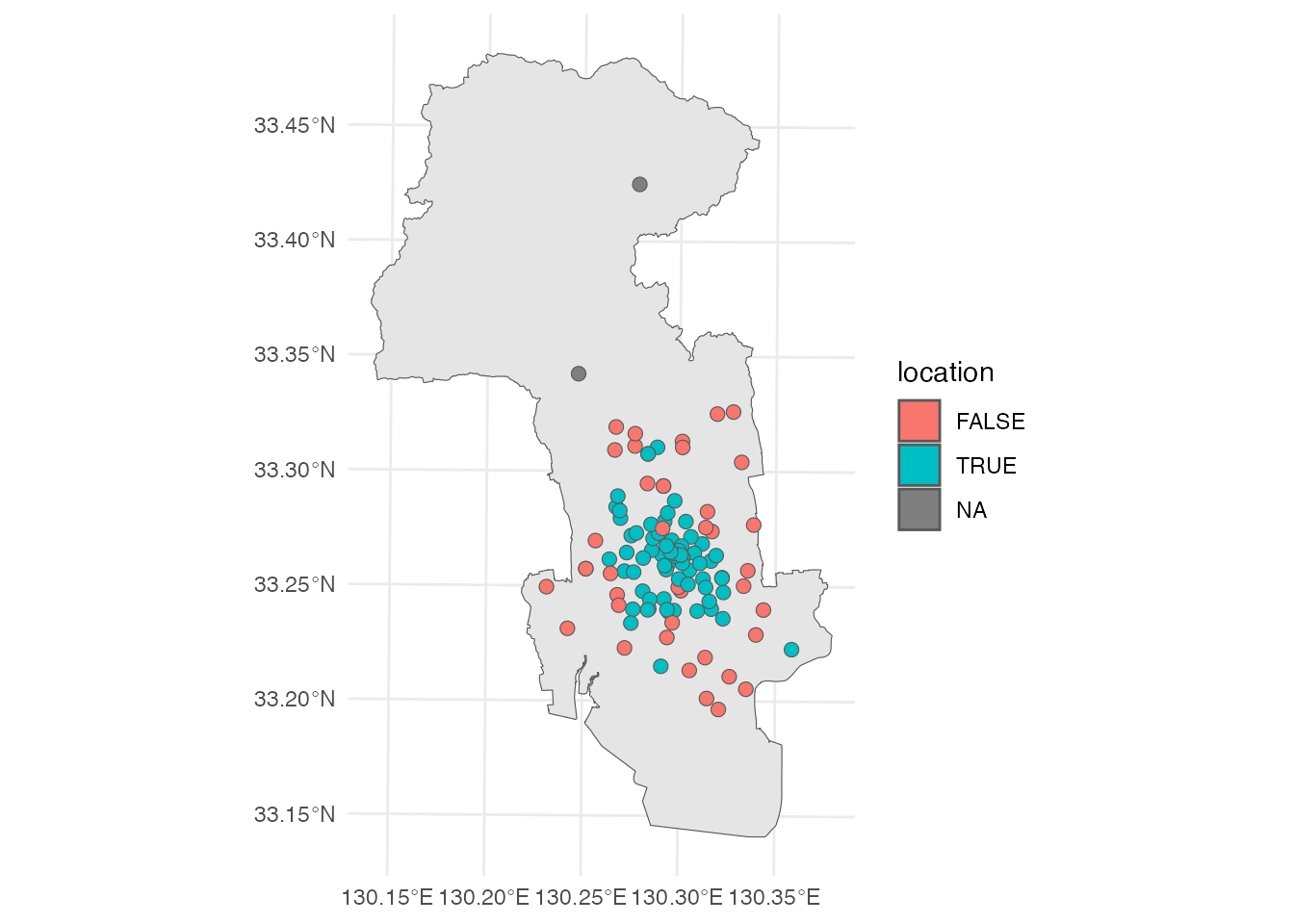
先ほどの地図よりも中心部と周辺部の店舗による商圏人口の違いがはっきりとわかる地図になりました。 周辺部のコンビニ店舗は、店舗周辺の人口は少ないけれども、幹線道路沿いであるなど、別の立地要因が影響している可能性があります(道路交通量の分析は今後の課題ということにしておきます)。
新規出店場所の検討
次に、新しく佐賀市内のどこにコンビニを出店可能かについて考えてみましょう。 ここでは、地域メッシュ統計のデータを使ってみることにします。
まず、佐賀市の250 mメッシュのポリゴンデータを作成します。 Rで地域メッシュ統計を扱うにはいろいろな方法がありますが、ここではjpgridパッケージのgeometry_to_grid関数とgrid_as_sf関数を使った方法を紹介します。
この関数jpgrid::geometry_to_gridを使えば、行政境界などのsfオブジェクトを、地域メッシュコードに変換することができます。 また、jpgrid::grid_as_sfにより、地域メッシュコードを含む(gridクラスの)データを、sfオブジェクトに変換することが可能です。
佐賀市のポリゴンデータを使って、佐賀市の市域にかかる4次メッシュ(250 mメッシュ)からなるポリゴンデータを作成します。 jpgrid::geometry_to_grid関数は長さ1のリストを返すので、dplyr::first関数を使ってリストの要素を取り出しています。 また、後で統計データを結合するためのmeshcodeを文字列型のデータとして作っておきます。
# 佐賀市域の地域メッシュ(250m)
saga_grid <- saga_city |> st_transform(6668) |>
geometry_to_grid(grid_size = '250m') |>
first() |> grid_as_sf(crs = 6668) |>
st_transform(6670) |>
mutate(meshcode = as.character(grid))できた佐賀市のメッシュを、佐賀市のポリゴンに重ねて地図にすることで確認してみましょう。
# 佐賀市地域メッシュ地図(250m)
ggplot() +
geom_sf(data = saga_city) +
geom_sf(data = saga_grid) +
theme_minimal()
コンビニエンスストアの新規出店候補地を調べたいわけですが、ここでは考える地域を市南部の平野に限定しましょう。 たまたま、1次メッシュ区画の境界が平地と山地の境目付近にありますので、ここで区切ることにしましょう。
ということで、1次メッシュ区画が4930であるメッシュだけを抽出します。 地域メッシュ統計は1次メッシュごとに統計データが公開されているので、データダウンロードが1回で済むというメリットもありますね。
ちなみに、九州周辺の1次メッシュコードは下図のようになっています。 佐賀県と重なっているのは、4929、4930、5029、5030の4つで、そのうち佐賀市にかかるのは、 4930と5030の2つです。
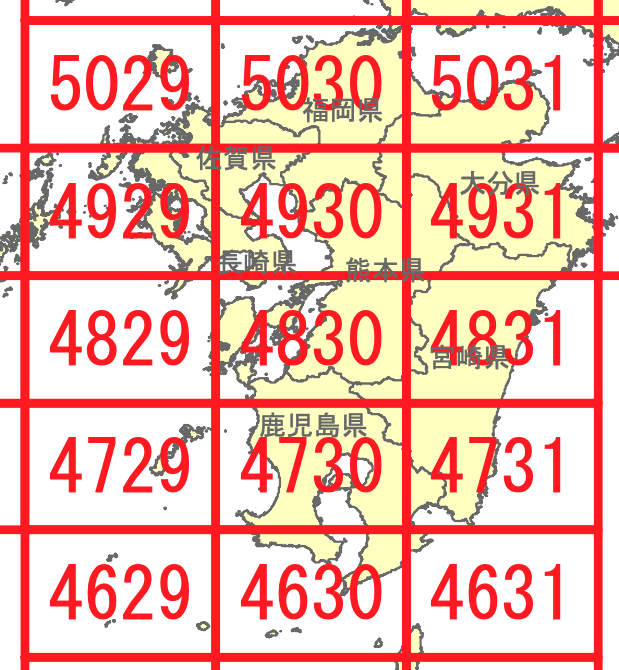
5次メッシュコードは11桁の数字ですが、その先頭4桁は対応する1次メッシュコードになっていますので、 メッシュコードの先頭が4930から始まっているメッシュだけをフィルタリングします。 stringr::str_starts関数は文字列の先頭が第1引数の文字列が、第2引数のパターンから始まる場合にTRUEを、そうでない場合にFALSEを返します。
# メッシュコードが"4930"で始まるメッシュを抽出
saga_grid <- saga_grid |>
filter(str_starts(meshcode, "4930"))もう一度地図を表示して、フィルタリングがうまくいったか確認しましょう。
# フィルタリング結果の図示
ggplot() +
geom_sf(data = saga_city) +
geom_sf(data = saga_grid) +
theme_minimal()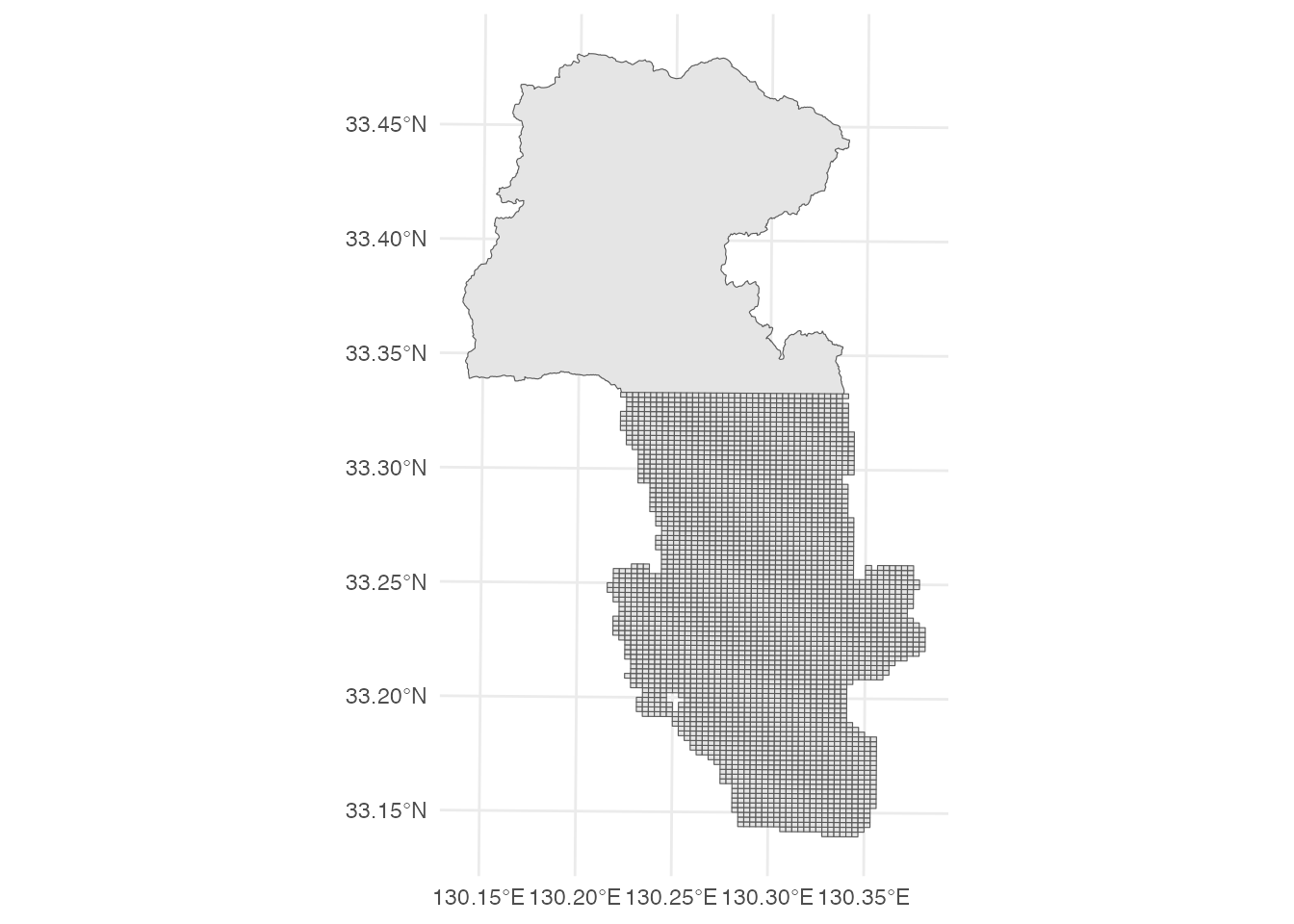
次に地域メッシュ統計の人口データをダウンロードします。 e-Statから、1次メッシュコード4930の人口データを取得しましょう。
- [国勢調査]→[2020年]→[5次メッシュ(250mメッシュ)]→[人口及び世帯(JGD2011)]
- 「都道府県で絞込みはコチラ」をクリックし、「41 佐賀県」の左のチェックボックスにチェック☑️をいれ「選択」ボタンをクリックすると、佐賀県にかかる4つの1次メッシュだけが表示されるので、上から2番目の「CSV」をクリックしてください。
- ダウンロードページへのダイレクトリンクはこちら。
「tblT001142Q4930.zip」がダウンロードされたら、これを展開して、できたファイル「tblT001142Q4930.txt」だけを、プロジェクトのdataフォルダに移動してください。
さて、これをreadr::read_csv関数で読み込むわけですが、例によって、2回に分けて読み込みます。 以下のコードでは、1回目はヘッダ情報のみ、2回目はデータ部分のみ読み込んでいます。
# メッシュ統計データの読み込み
col_names <-
read_csv('data/tblT001142Q4930.txt', n_max = 1,
col_names = FALSE, col_types = 'c') |>
as.character()
mesh <-
read_csv('data/tblT001142Q4930.txt', skip = 2,
col_names = col_names, na = c("", "*"))Rows: 32215 Columns: 54
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): GASSAN
dbl (53): KEY_CODE, HTKSYORI, HTKSAKI, T001142001, T001142002, T001142003, T...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.今回使用するのは、メッシュ総人口のデータだけですので、dplyr::select関数で抜き出しましょう。 同時に、人口データの列名をpopulationに、またmeshcodeを数値型から文字列型に変更しています。
# 総人口データの抽出
mesh <- mesh |>
select(meshcode = KEY_CODE,
population = T001142001) |>
mutate(meshcode = as.character(meshcode))
glimpse(mesh)Rows: 32,215
Columns: 2
$ meshcode <chr> "4930010022", "4930010023", "4930010024", "4930010034", "49…
$ population <dbl> 3, 57, 70, 3, 24, 92, 2, 22, 37, 5, 1, 86, 60, 18, 61, 1, 3…このmeshをsaga_gridに結合します。dplyr::left_joinを使います。
# メッシュ統計データをメッシュポリゴンデータに結合
saga_grid <-
saga_grid |> left_join(mesh, by = join_by(meshcode))
glimpse(saga_grid)Rows: 3,319
Columns: 4
$ grid <grd250> 4930526634, 4930526643, 4930526644, 4930526733, 49305267…
$ geometry <POLYGON [m]> POLYGON ((-62684.14 15679.9..., POLYGON ((-62392.58…
$ meshcode <chr> "4930526634", "4930526643", "4930526644", "4930526733", "49…
$ population <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…メッシュ人口の地図を描いてみましょう。 メッシュ統計の利点の1つは、各メッシュの大きさがほぼ同じなので、人口密度を計算しなくても、それぞれのメッシュの人口の大小を直接比較できることです。
# メッシュ人口地図
ggplot() +
geom_sf(aes(fill = population), data = saga_grid, color = NA) +
scale_fill_distiller(direction = 1) +
theme_minimal()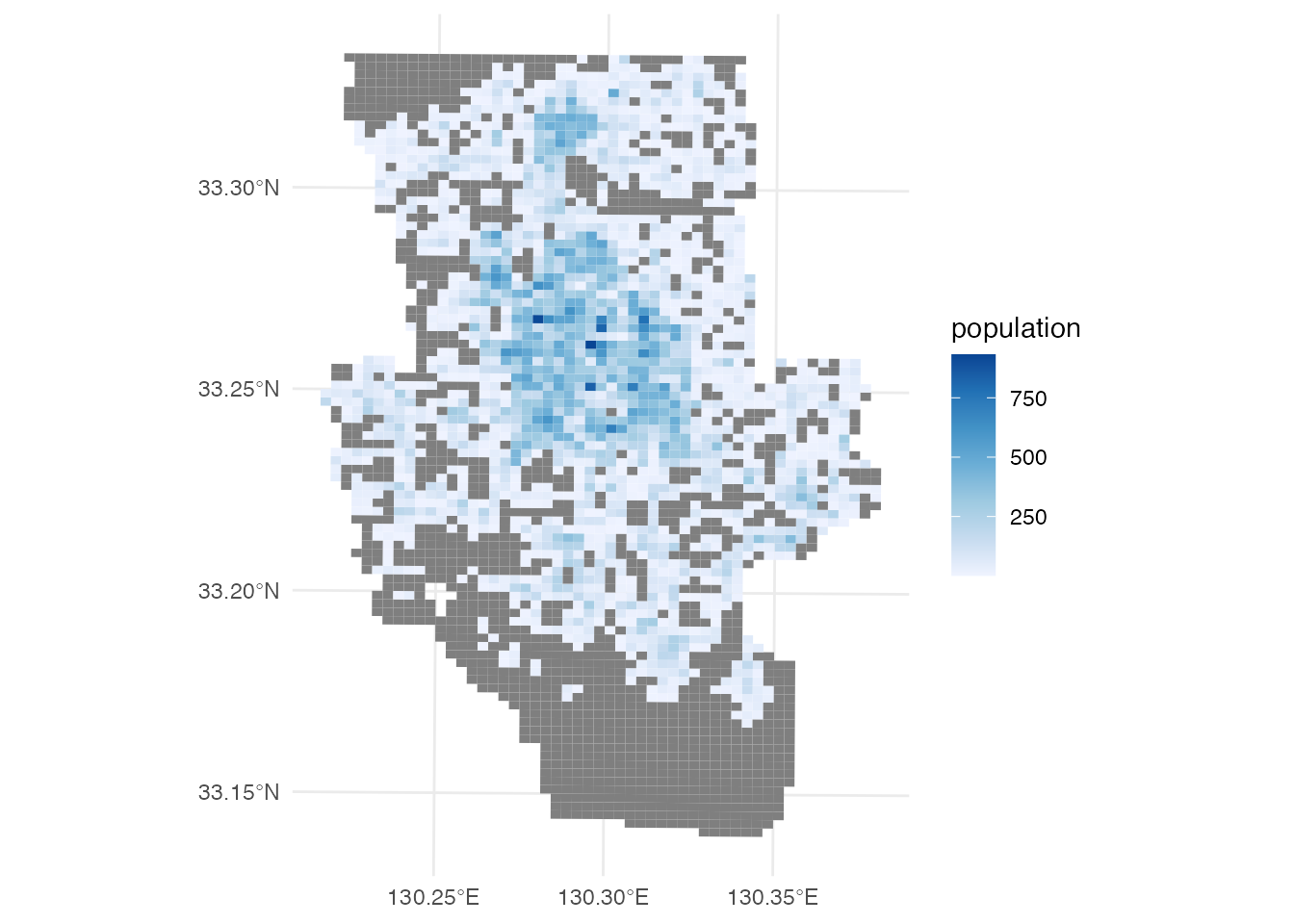
さて、佐賀市におけるコンビニの成立条件は、半径350 mの範囲に1,000の人口がいることでした。 これをメッシュ人口に置き換えると、メッシュの面積がおよそ2502 m2、半径350 mの円の面積がπ× 3502 m2ですから、メッシュ区画が3×3=9個並んだ範囲において、
# 閾値の計算
1000 * 250^2 * 9 / (pi * 350^2 )[1] 1461.627およそ1,500人の人口がいることに相当します。 それでは、9区画の人口が1,500人を超えるメッシュ区画を抽出してみましょう。
Rの関数定義
Rでも他のプログラミング言語と同様に、自前の関数を定義できます。 その基本的な書式は、以下のとおりです。
new_function <- function(variables){
# ここに処理を書く
}ここでは、例としてベクトルの平均を計算する関数averageの例を見てみましょう。
x <- c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
average <- function(x){
n <- length(x)
s <- sum(x)
s / n
}
average(x)[1] 5.5以下では、周辺9メッシュ合計の人口を計算する関数compute_neighbor_popを定義しています。 そして、その関数をpurrr::map_int関数によって全てのメッシュについて繰り返し計算しています。 計算した結果は、neighbor_pop列に格納しています。
# 近隣9メッシュの人口を計算する関数
compute_neighbor_pop <- function(grid){
neighbor_grid <- grid |>
grid_neighborhood(n = 0:1, type = 'moore') |>
first()
saga_grid |>
filter(grid %in% neighbor_grid) |>
pull(population) |>
sum(na.rm = TRUE)
}
# 近隣9メッシュの人口を計算
saga_grid <- saga_grid |>
mutate(neighbor_pop = map_int(grid, compute_neighbor_pop))次に、mutate関数を使って、人口が1,500人を超えるかどうかをTRUEかFALSEかで格納したmarketというデータ列を作成します。
# # 近隣9メッシュの人口が1,500人を超える地域
saga_grid <- saga_grid |>
mutate(candidate = neighbor_pop > 1500)candidateでメッシュの色を塗り分けた地図を表示してみましょう。 その地図に、現在のコンビニの商圏を重ねます。
# 出店候補地の図示
union_buffer <- buffer |> st_union()
ggplot() +
geom_sf(aes(fill = candidate), data = saga_grid, color = NA) +
geom_sf(data = union_buffer) + ylim(16000, 37000) +
theme_minimal()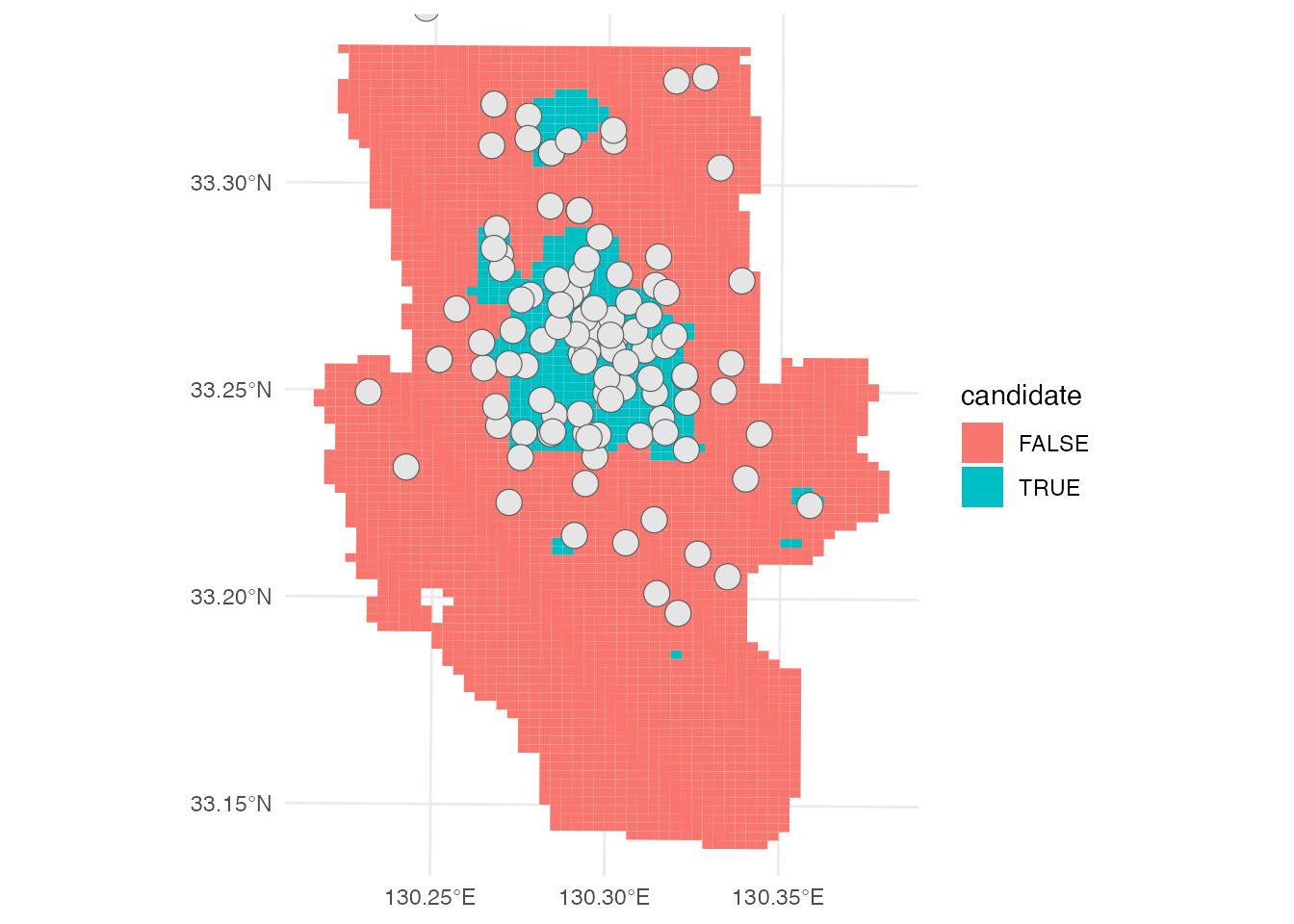
人口が1,500人を超えていて、なおかつ既存のコンビニが出店していないメッシュが、まずは新規出店の候補地となるのではないでしょうか。 しかし、実際の出展計画を考える際にはこれだけの分析では不十分だと考えられます。 まずは、実際にその付近の土地や建物の利用可能性を確認する必要があります。 また、夜間人口だけでなく、昼間の周辺人口(職場や学校など)、敷地前面道路の交通量など、周辺の土地利用や建築に関わる規制など、多くの要素を考慮に入れる必要があるでしょう。
実際にローソンの出店ガイドラインをみると、「第一種低層住居専用地域、工業専用地域には原則出店できません」との記述があります。 そこで最後に、佐賀市中心部の用途地域ついて確認してみましょう。
用途地域とは
都市における住居、商業、工業といった土地利用は、似たようなものが集まっていると、それぞれにあった環境が守られ、効率的な活動を行うことができます。 しかし、種類の異なる土地利用が混じっていると、互いの生活環境や業務の利便が悪くなります。 そこで、都市計画では都市を住宅地、商業地、工業地などいくつかの種類に区分し、これを「用途地域」として定めています。 それぞれの用途地域に応じて、建てられる建築物の用途や規模が決められています。
佐賀市の最新の用途地域については、佐賀市ウェブサイトおよびそこからリンクされているぐるっとさがナビから確認することができます。 また、用途地域のポリゴンデータが国土数値情報から入手可能です。
こちらから、2022年度(令和4年度)の佐賀市の都市計画決定情報データ(A55-22_41201_GEOJSON.zip)をダウンロードしてください。 ダウンロードフォルダにあるzipファイルを展開して、できたフォルダ(A55-22_41201_GEOJSON)を、プロジェクトのdataフォルダに移動してください。
シェープファイルをsf::st_read関数で読み込みます。 日本語の文字化けを解消するために、文字コードをoptions引数で指定しています。
# 用途地域データの読み込み
zoning <- st_read("data/A55-22_41201_GEOJSON/41201_youto.geojson") |>
filter(YoutoID == 1 | YoutoID == 13) |>
st_transform(6670)Reading layer `41201_youto' from data source
`/Users/kzktmr/Documents/LectureNotes/EconomicGeography/data/A55-22_41201_GEOJSON/41201_youto.geojson'
using driver `GeoJSON'
Simple feature collection with 186 features and 11 fields
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: 130.2618 ymin: 33.20996 xmax: 130.3746 ymax: 33.32395
Geodetic CRS: JGD2011佐賀市の用途地域データから、用途地域が第一種低層住居専用地域、工業専用地域であるポリゴンだけを抜き出すために、filter関数でフィルタリングを行っています。 そして、平面直角座標系II系に投影変換しています。
先ほどの地図に、用途地域(第一種低層住居専用地域、工業専用地域)のポリゴンを重ねて表示してみましょう。
# 出店候補地(+用途地域)の表示
ggplot() +
geom_sf(aes(fill = candidate), data = saga_grid, color = NA) +
geom_sf(aes(fill = `用途地域`), data = zoning) +
geom_sf(data = union_buffer) + ylim(16000, 37000) +
theme_minimal()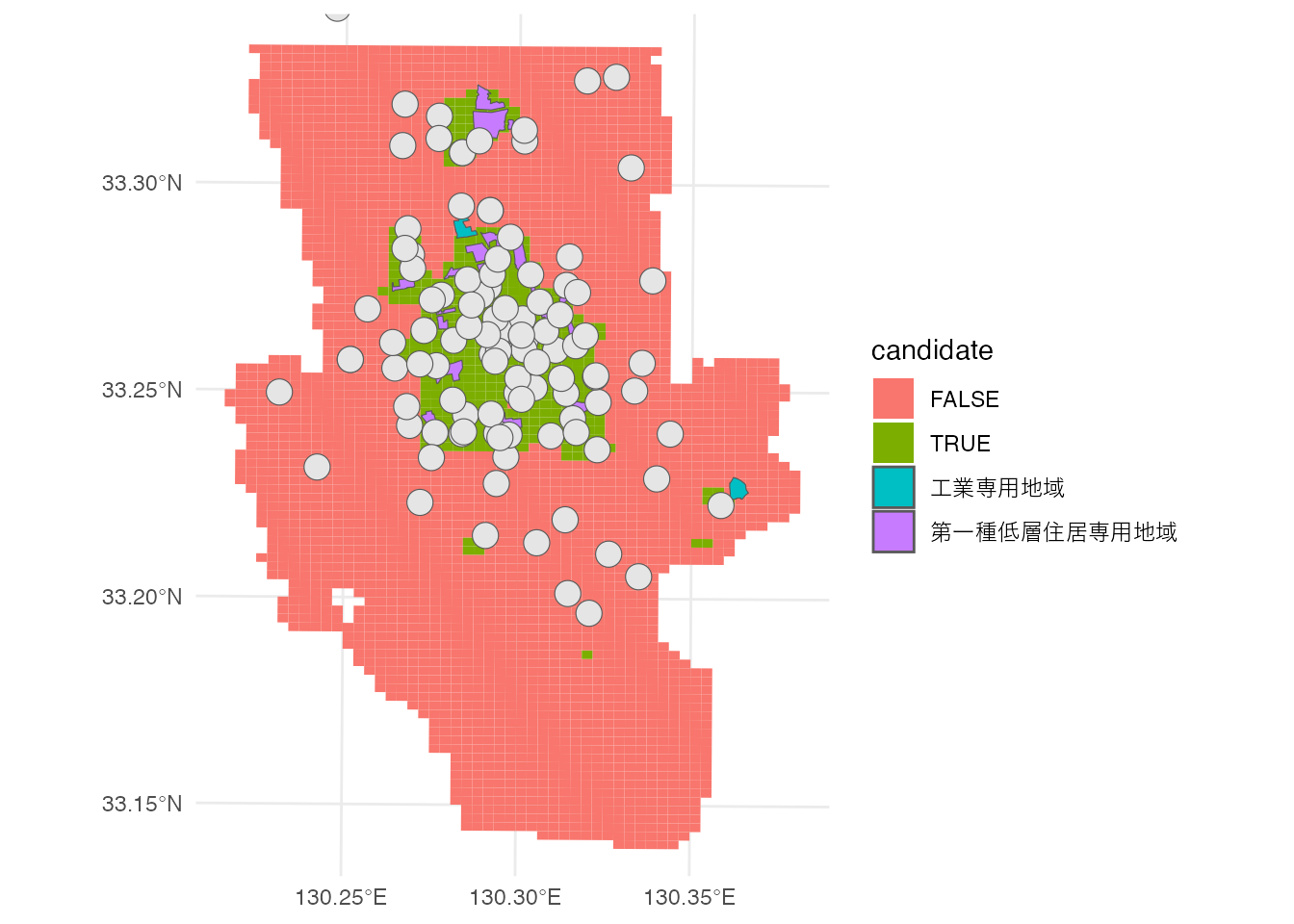
なんとなく、どのあたりに出店したら良さそうか、見えてきたでしょうか。
脚注
学外からはアクセスできません。学内ネットワークからダウンロードしてください。↩︎