?curve2: RとRStudioの基礎
今回は、RとRStudioの基本的な使い方を習得します。
RStudioの使いかた
プロジェクト機能
複数の分析プロジェクトを並行して行うときなどに、使用するデータや記述したコードなどをプロジェクトごとに管理できると便利です。 そのような管理機能を提供するのが、RStudioのプロジェクト機能です。
プロジェクトの作成
RStudio画面右上の[Project:]から、[New Project…]を選択することで、新しいプロジェクトを作成できます。
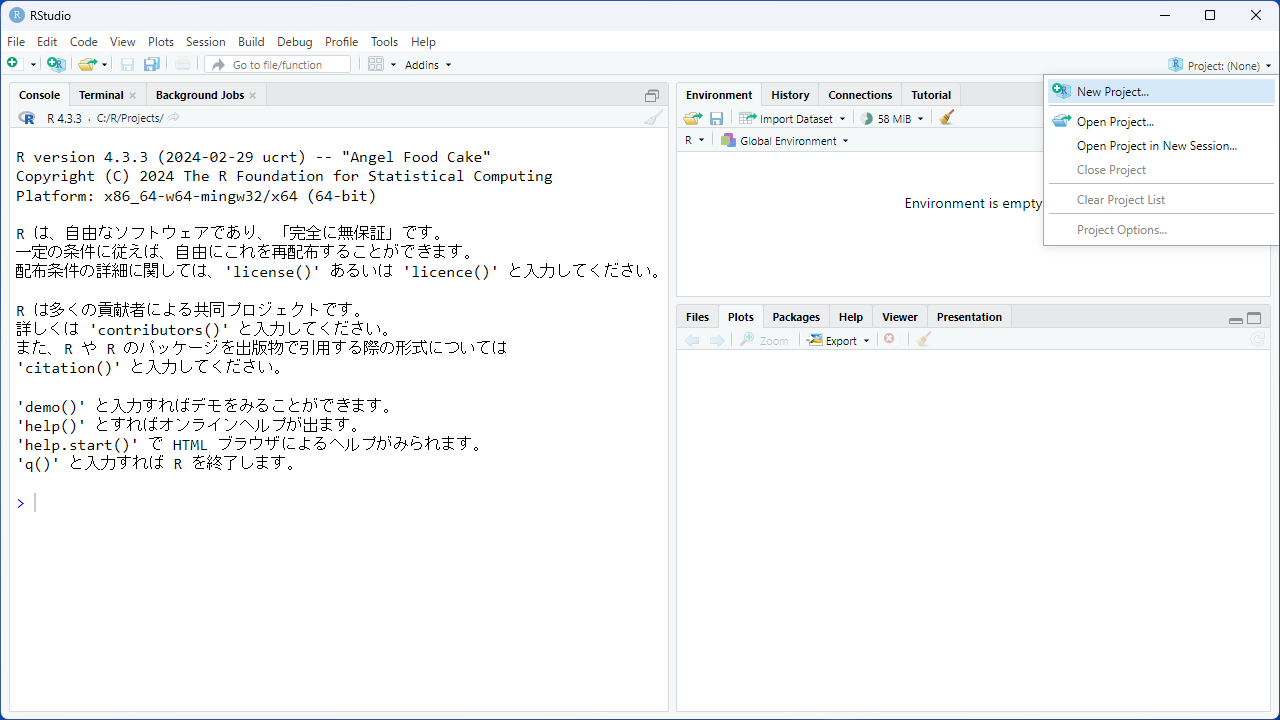
[New Directory]を選択し、新しいディレクトリを作って、そこにプロジェクトのファイル一式を置くことにします。
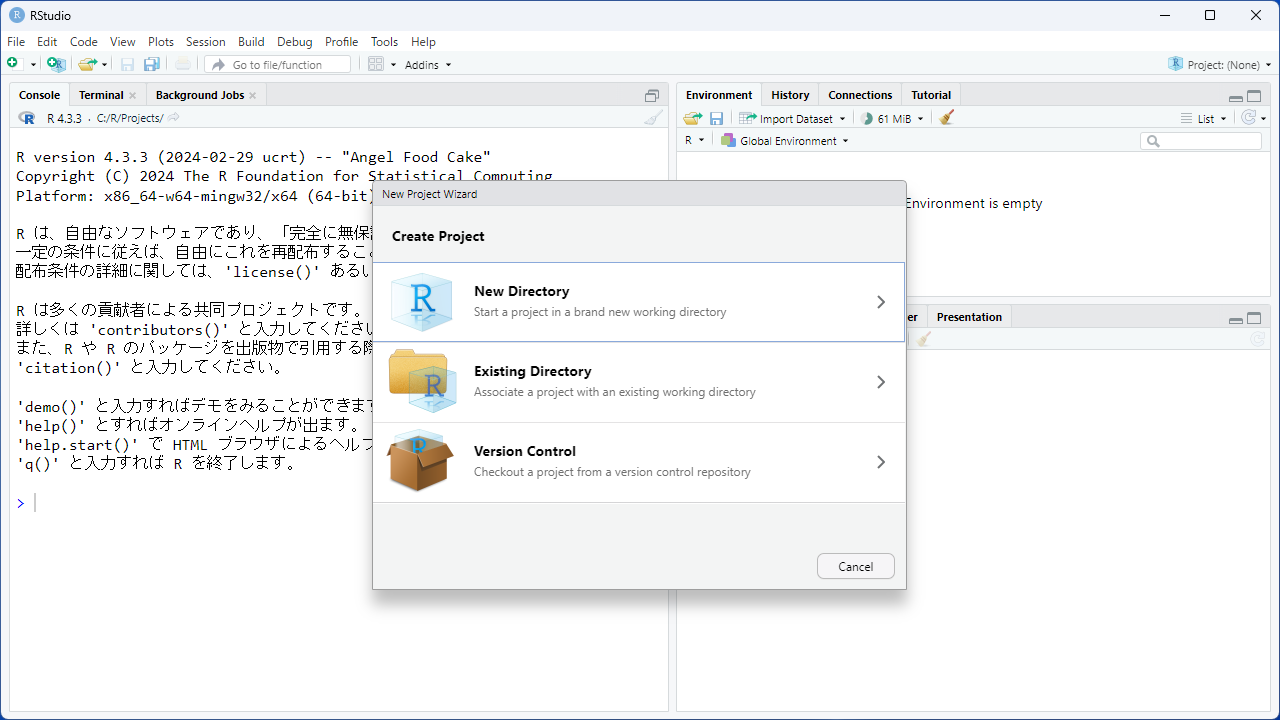
Project Typeは、[New Project]を選択します。
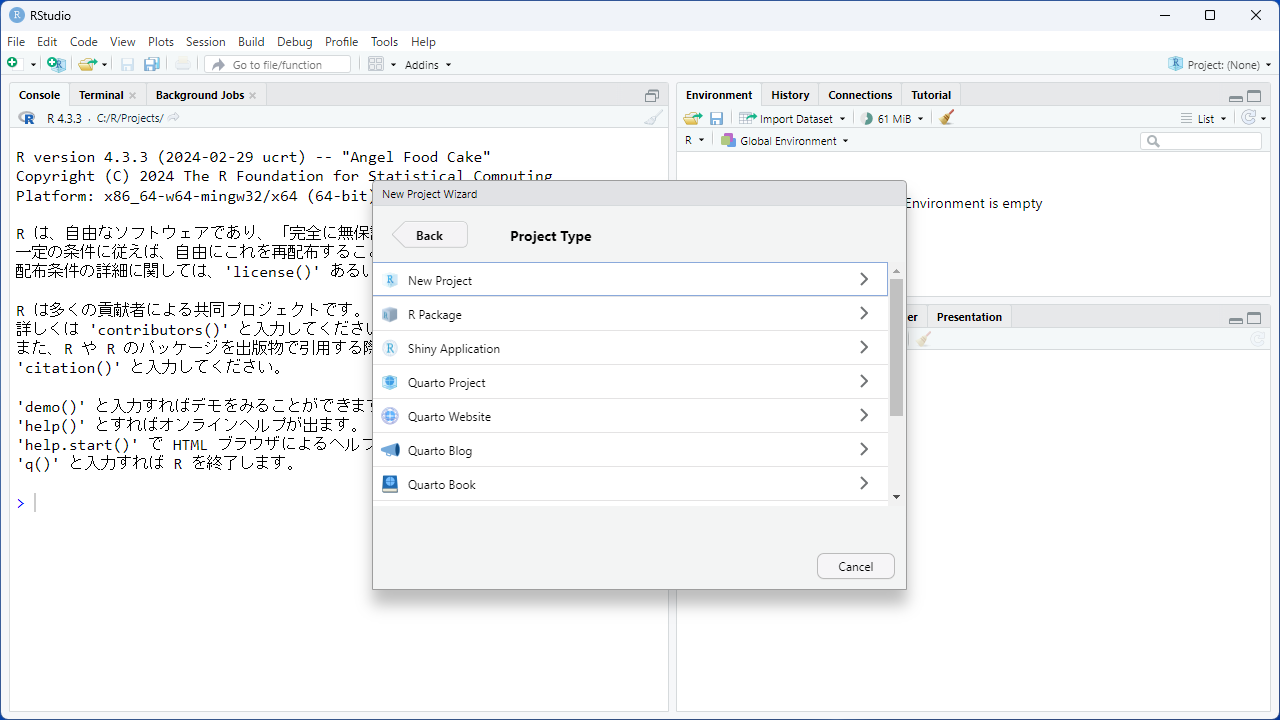
[Directory Name:]欄に、作成するプロジェクトの名前を入力したら、 [Browse…]ボタンを押し、プロジェクトディレクトリを設置する場所を指定します。 最後に[Create Project]ボタンを押すと、プロジェクトが作成され、新しいウィンドウでRStudioが立ち上がります。
作成したプロジェクトのフォルダに、拡張子がRprojのファイルがあると思いますが、これがプロジェクトファイルです。 このプロジェクトファイルを開くことでも、RStudioでこのプロジェクトを再開することができます。
試しに、RStudioを終了してみましょう。 そして、プロジェクトファイルをダブルクリックすることで、RStudioを起動してみてください。
パッケージ管理
分析にRを使うことの大きなメリットの1つは、世界中のRユーザが作成したパッケージを利用できることです。 パッケージを利用することで、Rにさまざまな機能を追加したり、Rで分析を実行するためのツールや関数を追加したりできます。
CRAN Task Views
Rのパッケージは主にCRANで管理されていて、2025年4月22日現在で、22,334のパッケージが登録されています。 CRANのウェブサイトを開いて、左側のリンクから、[Packages]をクリックしてみてください。
自分の分析目的に使えるパッケージを探すときには、CRAN Task Viewsが便利です。 左側のリンクから、[Task Views]をクリックしてください。 すると、トピックごとのリンクが表示されると思います。 試しに、[Spatial](空間分析)をクリックしてみてください。 すると、さらに細かな分野ごとに、利用できるパッケージとその簡単な説明があります。
RStudioを使ったパッケージのインストール
Rにパッケージをインストールする方法にはいくつかありますが、ここではRStudioの機能を使った方法を説明します。
RStudioの画面右下のペインの[Packages]タブをクリックしてください。 すると、現在インストールされているパッケージの一覧が表示されます。

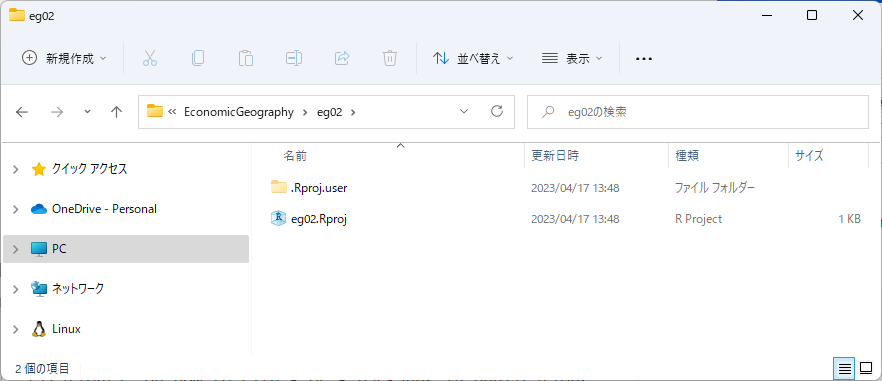
ここで、今日の講義で使用するパッケージをインストールしてみましょう。新たにパッケージをインストールするには、[Install]をクリックします。
[Packages]欄に、[dplyr, readr, readxl]と入力してInstallボタンをクリックしてください。左下のコンソールにインストールの進捗状況が表示されます。
パッケージのアップデート
パッケージは、機能の追加や問題の修正など、日々更新されています。 なので、できるだけ最新のパッケージを利用することが望ましいといえます。 インストール済みのパッケージを最新版にアップデートするには、右下のパッケージ・ペインから[Update]ボタンを押します。 すると、インストールされているパッケージのうち、「最新版でないもの」が表示されるので、[Sellect All]を押し、[Install Updates]を押せば、新しいパッケージがインストールされます。
時々、この作業を行い、パッケージを最新版に保つようにしましょう。
パッケージのインストール・アップデートにおける注意事項
パッケージのインストールやアップデートを行うと、時々、コンソールに
Do you want to install from sources the packages which need compilation? (Yes/no/cancel)
のように表示され、インストールが中断されることがあります。この場合、コンソールに、[yes][no][cancel]のいずれかをキーボードから入力する必要がありますが、[no]と入力することをおすすめします。[yes]を選ぶと、インストールに時間がかかるだけでなく、インストールやアップデートがうまくいかないこともあります。[no]と入力することで、少し古いパッケージがインストールされますが、実用上はそれで問題ないです。
関数のヘルプ
原則として、すべてのRの関数にはヘルプ記事が用意されています(英語ですが)。 これを閲覧するには、右下のペインから[Help]タブを選択し、検索欄に関数名を入力してヘルプ記事を検索します。
また、コンソールに、関数の前にクエスチョンマーク[?]を付けて入力しても、ヘルプ記事を参照できます。
スクリプトファイル
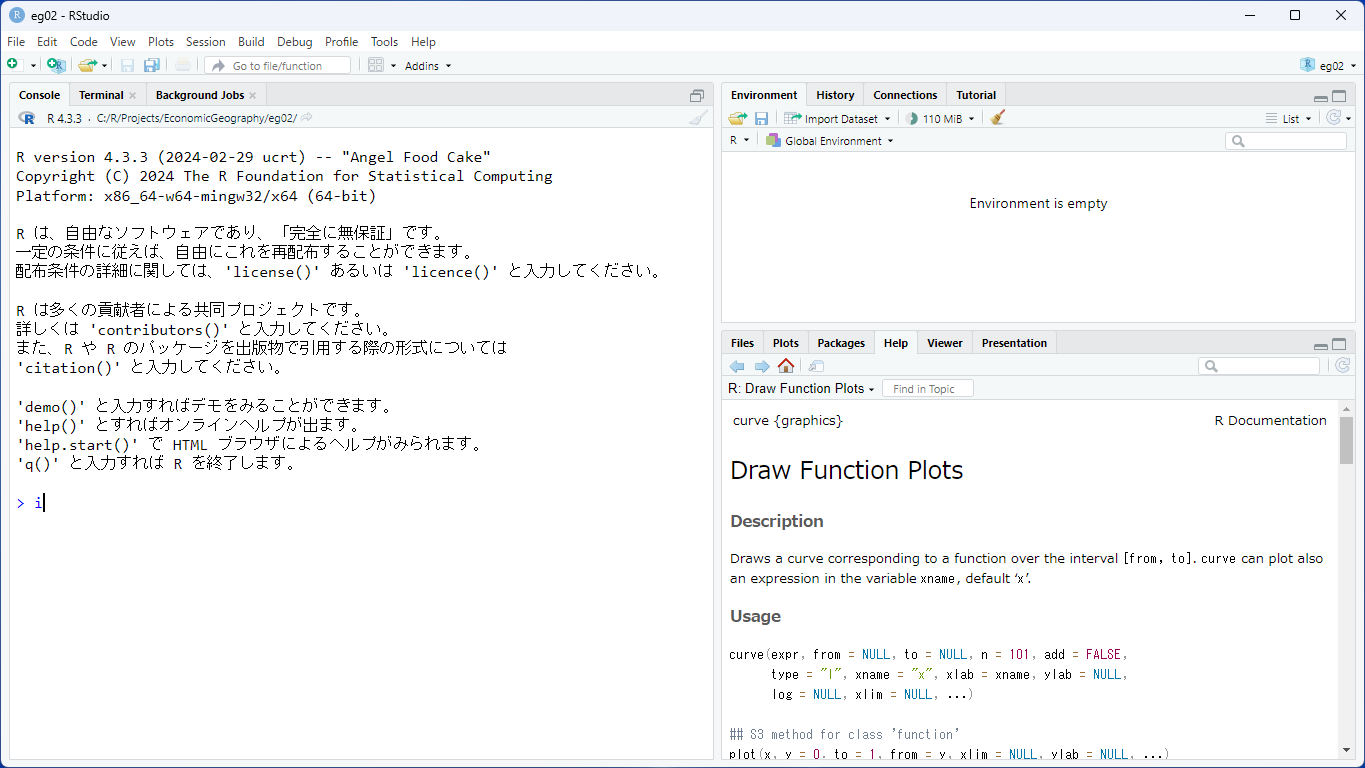
Rへの入力は、直接コンソール・ペインに入力してもよいですが、通常はスクリプトファイルにコードを記述して利用します。 新しいスクリプトファイルを作成するにはいくつかの方法がありますが、 ここでは、右下のファイルペインから[New File]をクリックしましょう。
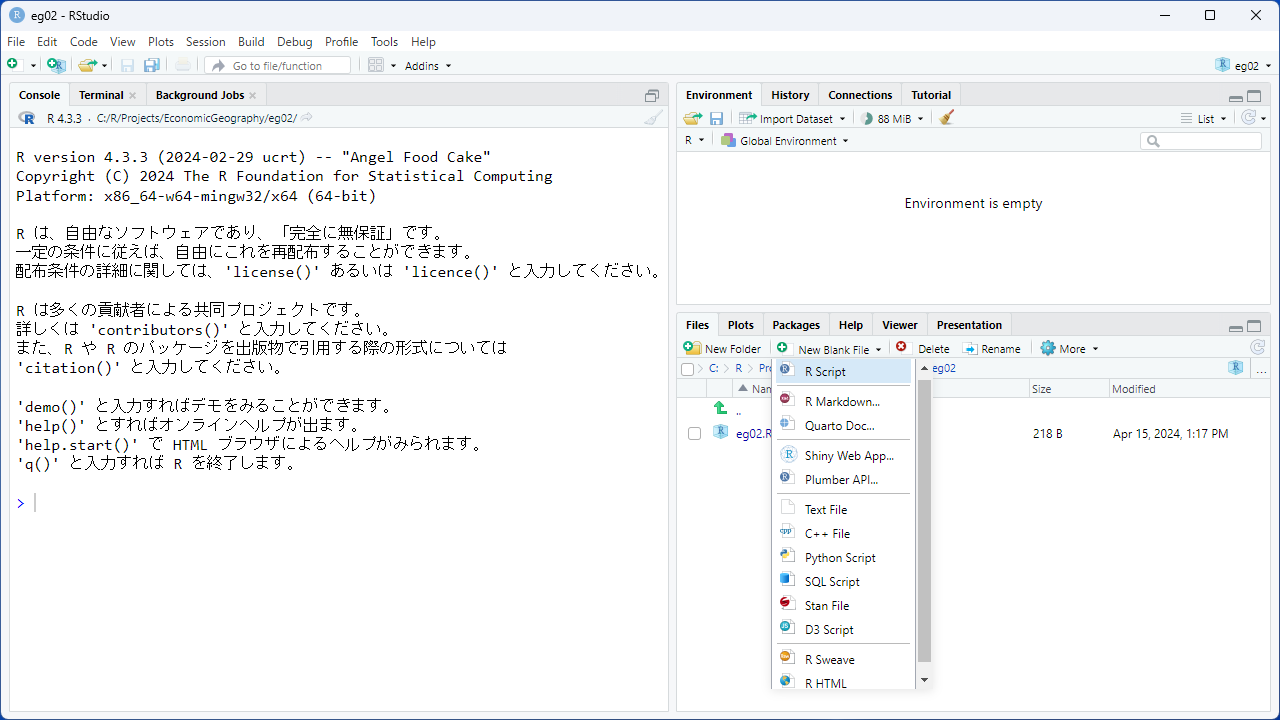
プルダウンメニューが開くので、一番上の[R Script]を選んでください。
ファイル名を入力するウィンドウが出てきますので、新しいファイルの名前(自由につけてください。ここでは「eg02.R」とでもしておきましょう。ただし、拡張子は.R)を入力して[OK]ボタンをクリックします。
これで、左上のソース・ペイン(コンソール・ペインの上)に「eg02.R」ファイルが表示されたと思います。 そこに、
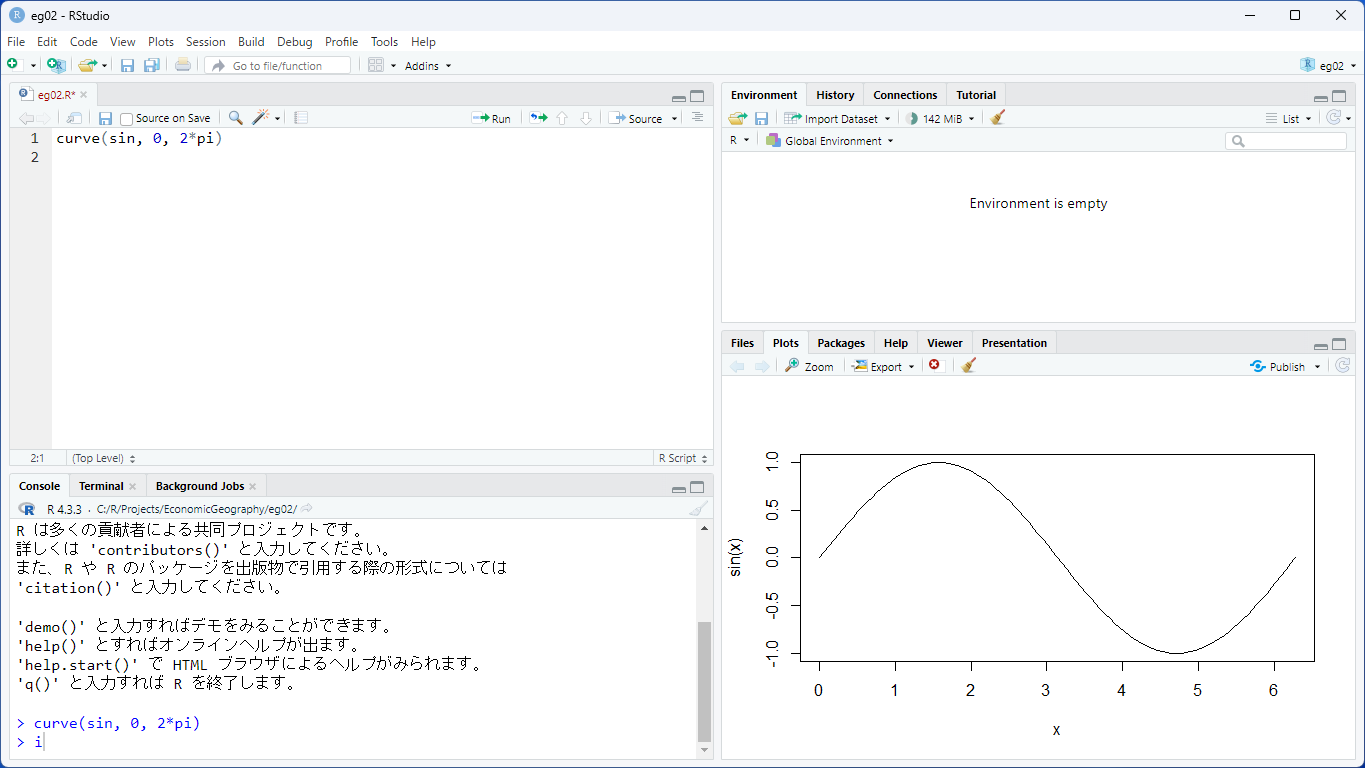
curve(sin, 0, 2*pi)と入力しましょう。
入力したコードを実行するには、実行したいコードのある行にカーソルを置いた状態で、キーボードから[Ctrl+Enter]を入力します(コントロールキーを押しながら、Enterキーを押します)。 その行の内容が、コンソール・ペインに入力され、実行されます。 うまくいけば、右下のプロット・ペインにサインカーブが描かれるはずです。
入力履歴
Rには、入力履歴を保存する機能があります。 それまでに入力したコマンドを表示するには、コンソールにカーソルがある状態で、キーボードの上下矢印キー(↑や↓)を押します。
フォルダ作成
プロジェクトフォルダの中に、分析で使うデータを保存する際に、データファイルだけをまとめて保存しておくフォルダを作っておくと便利です。 また、スクリプトファイルを複数作成する場合などにも、それらをまとめて格納しておくフォルダがあると、ファイル管理が楽になります。
もちろん、OS(WindowsやMacOS)の機能(エクスプローラーやファインダー)で、新規フォルダを作成しても良いのですが、RStudioの機能を使って、プロジェクトフォルダに新しいフォルダを作ることができます。
右下のファイルペインから[New Folder]をクリックすると、小さなウィンドウが開きますので、作成したいフォルダの名前を入力し、[OK]をクリックします。
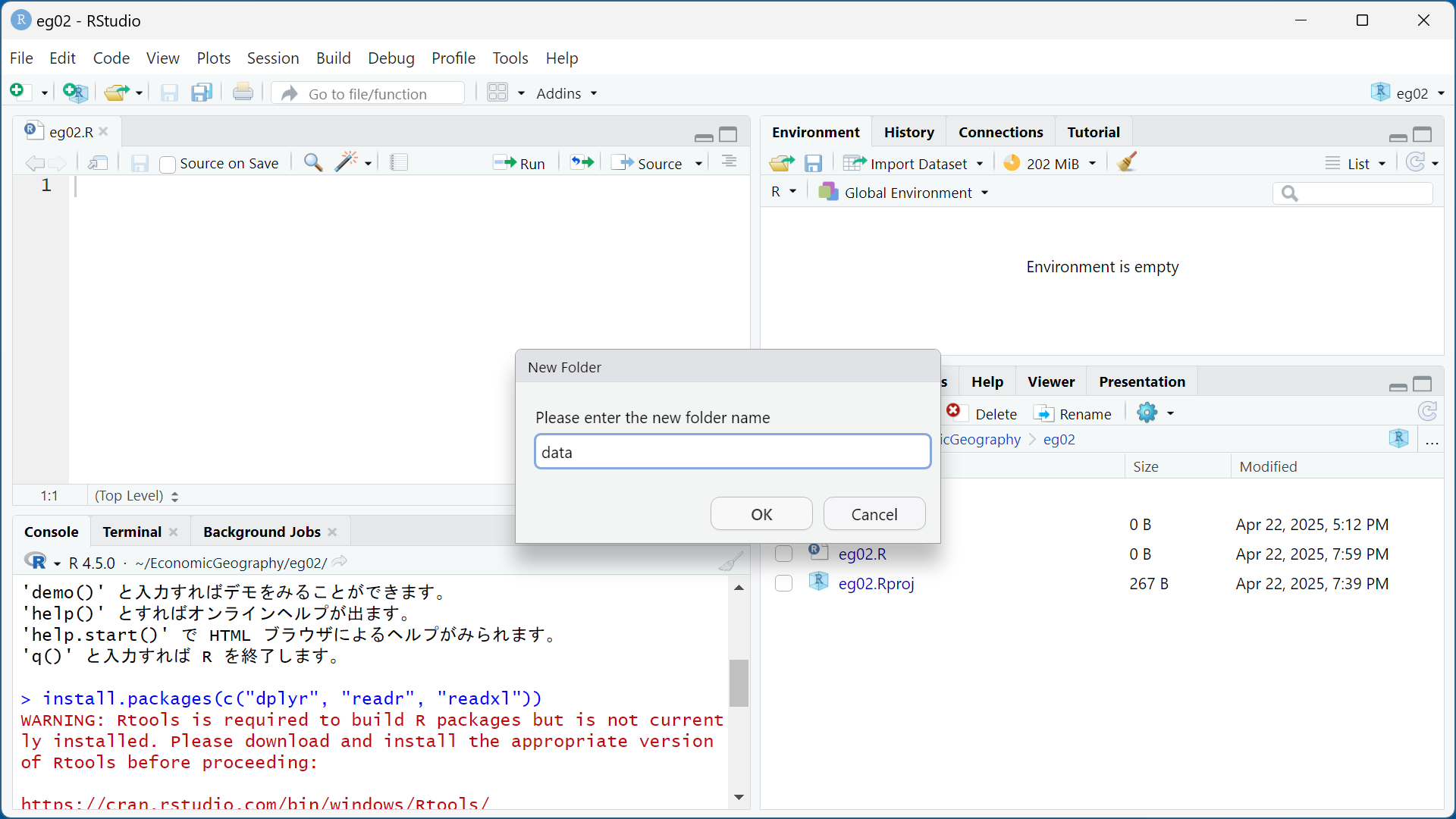
これで、プロジェクトフォルダの中に、dataという名前の新フォルダを作成することができました。 今日の演習で使用するデータファイルは、このdataフォルダに保存することにしましょう。
Rの基礎
データ型
Rでよく使うデータ型には、数値型、論理型、文字列型、因子型、日付型などがあります。
# 数値型
1
3.14
# 論理型
TRUE
FALSE
# 文字列型
"apple"
"123"
# 因子型、日付型などはまた後日…
コメント・アウト
Rのコードにおいて、行の先頭に#記号があると、Rはその行の内容を評価(実行)しません。 なので、Rのコード中になんらかのメモやコメントを残したい場合に、この#記号を使うことができます。
行の先頭に#記号を挿入することをコメント・アウトといいます。 専用のキーボード・ショートカットも用意されていて、Windowsは[Ctrl]+[Shift]+[C]、Macは[Command]+[Shift]+[C]です。 コメント・アウトを解除するのにも、同じキーボード・ショートカットを使います。
演算
演算
Rで四則演算をやってみましょう。
# 足し算
7 + 3[1] 10# 引き算
7 - 3[1] 4# 掛け算
7 * 3[1] 21# 割り算
7 / 3[1] 2.333333# 割り算(商)
7 %/% 3[1] 2# 割り算(余り)
7 %% 3[1] 1# 冪乗
7 ** 3[1] 343# これも冪乗
7 ^ 3[1] 343大小関係や等号・不等号などの関係演算は、以下のように実行します。 演算結果は、TRUEもしくはFALSEの論理型データになります。
# 大小関係
7 > 3[1] TRUE7 < 3[1] FALSE# 等号・不等号
7 == 3[1] FALSE7 != 3[1] TRUENOTやAND・ORなどの論理演算は、以下のようにします。
# NOT(否定)
!TRUE[1] FALSE!FALSE[1] TRUE# AND(論理積)
TRUE & TRUE[1] TRUETRUE & FALSE[1] FALSE# OR(論理和)
TRUE | TRUE[1] TRUETRUE | FALSE[1] TRUE数学関数
Rには、例えば以下のような数学関数が用意されています。
# 平方根
sqrt(2)[1] 1.414214# 自然対数
log(10)[1] 2.302585# 常用対数
log10(100)[1] 2# 指数関数
exp(1)[1] 2.718282# 丸める
round(pi, 2)[1] 3.14# 切り上げ(天井関数)
ceiling(pi)[1] 4# 切り下げ(床関数)
floor(pi)[1] 3
Rの定数
Rにも、他のプログラミング言語と同様に、いくつかの定数が用意されています。
pi # 円周率
Inf # 無限大(Infinity)
NULL # 空値
NaN # 非数(Not a Number)
NA # 欠損値(Not Available)このうちNAは、一般的なプログラミング言語では見かけることのない定数で、欠損値のための定数が用意されているというのは、統計解析のための言語であるRの特徴だといえるでしょう。
代入
Rで変数に値を代入するには、<-や->を使います(->はあまり使いません)。 =でも代入できます(<-と=のどちらを使うかは、好みです)。
x <- 7
y <- 3
z <- x / y
z[1] 2.333333x <- x ** 2
x[1] 49z = sqrt(x)
z[1] 71 / y -> z
z[1] 0.3333333ベクトル
Rのプログラミング言語としての特徴の1つは、ベクトルや行列が扱いやすいことです。
ベクトルの作成
Rのベクトルは、数学のベクトルとほとんど同じ概念で、同じ型のデータが、2つ以上まとめたデータです。 数学のベクトルと違って、数値型以外の型(例えば文字列型)のデータもまとめてベクトルにすることができます。
いろいろな方法でベクトルを作成することができます。
# 要素を結合
c(2, 4, 6)[1] 2 4 6# 整数の並び
2:6[1] 2 3 4 5 6# 連続する数の間隔を指定
seq(2, 5, by = 0.5)[1] 2.0 2.5 3.0 3.5 4.0 4.5 5.0# ベクトルを繰り返す
rep(1:2, times = 3)[1] 1 2 1 2 1 2# ベクトルの要素を繰り返す
rep(1:2, each = 3)[1] 1 1 1 2 2 2ベクトル関数
ベクトルを引数にとる関数もあります。
x <- c(3, 6, 2, 5, 1, 3)
# 合計
sum(x)[1] 20# 平均
mean(x)[1] 3.333333# 標準偏差
sd(x)[1] 1.861899# 並べ替え
sort(x)[1] 1 2 3 3 5 6# 逆順
rev(x)[1] 3 1 5 2 6 3# ユニークな値
unique(x)[1] 3 6 2 5 1# 各要素の個数
table(x)x
1 2 3 5 6
1 1 2 1 1 # ベクトルの長さ(要素の数)
length(x)[1] 6ベクトルの演算
ベクトルの演算では、要素ごとの演算の結果を格納したベクトルが得られます。
x <- c(2, 4, 6, 8)
y <- c(1, 2, 3, 4)
# 足し算
x + y[1] 3 6 9 12# 引き算
x - y[1] 1 2 3 4# 掛け算
x * y[1] 2 8 18 32# 割り算
x / y[1] 2 2 2 2# 商
x %/% y[1] 2 2 2 2# 余り
x %% y[1] 0 0 0 0
長さの異なるベクトルの演算
ベクトルの長さが異なる場合、長いベクトルの長さが短いベクトルの長さの倍数ならば、短いベクトルを繰り返して演算されます。
x <- c(2, 4, 6, 8)
y <- c(1, 2)
z <- c(1, 2, 1, 2) # zはyを2つつなげたベクトル
x / y # yが短いので、yを2つつなげたベクトルで演算[1] 2 2 6 4x / z # yを2つつなげたベクトルで演算した結果と同じ[1] 2 2 6 4y <- 2 # スカラー
x / y # xの要素をそれぞれ2で割る演算になる[1] 1 2 3 4ベクトルの要素を取り出す
ベクトルの要素を取り出すさまざまな方法があります。
x <- c(3, 6, 2, 5, 1, 3)
# 4番目の要素
x[4][1] 5# 4番目以外の要素
x[-4][1] 3 6 2 1 3# ベクトルで位置を指定
x[1:2][1] 3 6x[c(1, 4)][1] 3 5x[-(1:2)][1] 2 5 1 3# 値による指定
x[x == 3][1] 3 3x[x >= 5][1] 6 5# 集合に含まれる要素
x[x %in% c(1, 3, 5)][1] 3 5 1 3%in%演算子
%in%演算子は、値のマッチングに関する二項演算子です。 演算子の左側の要素が、右側の要素(通常はベクトル)に含まれるかどうかを表す論理型データ(TRUEもしくはFALSEを返します。例えば、
1 %in% c(1, 2, 4)[1] TRUE3 %in% c(1, 2, 4)[1] FALSE演算子の左型をベクトルにすると、ベクトルの要素それぞれについての%in%の結果を、ベクトルで返します。
c(1, 3) %in% c(1, 2, 4)[1] TRUE FALSE上の例では、
x %in% c(1, 3, 5)[1] TRUE FALSE FALSE TRUE TRUE TRUEx[c(TRUE, FALSE, FALSE, TRUE, TRUE, TRUE)][1] 3 5 1 3の結果が表示されているということです。
データ型の変換
x <- c(1, 0, 1)
# データ型の確認
class(x)[1] "numeric"# 論理型に変換
y <- as.logical(x)
y [1] TRUE FALSE TRUE# 論理型データはTRUEを1にFALSEを0として算術演算できる
sum(y)[1] 2# 文字列型に変換
z <- as.character(x)
z[1] "1" "0" "1"# 文字列型を数値型に変換
as.numeric(z)[1] 1 0 1type.convert(z, as.is = TRUE)[1] 1 0 1リスト
いろいろなデータ型を持つ要素を、まとめて1つのリストにすることができます。
リストの作成
z <- list(x = 1:3, y = c("a", "b"))
z$x
[1] 1 2 3
$y
[1] "a" "b"リストの要素を取り出す
# リストzの2番目の要素
z[[2]][1] "a" "b"# リストzの名前がyの要素
z$y[1] "a" "b"データフレーム
データフレームは、分析に使うデータを保持する構造として、最も一般的なものの1つです。スプレッドシート上でデータを管理するときのように、列名(colmun name)と行番号(row index) を持つ2次元配列の格好をしています。
データフレームの作成
データベースをつくるには、data.frame関数を使います。以下の表のようなデータを持つデータフレームをつくるコードを示します。
| names | division | wins | draws | losses | goals_for | goals_against |
|---|---|---|---|---|---|---|
| Avispa | J1 | 12 | 14 | 12 | 33 | 38 |
| Giravanz | J3 | 15 | 11 | 12 | 41 | 39 |
| Sagan | J1 | 10 | 5 | 23 | 48 | 68 |
| V-Varen | J2 | 21 | 12 | 5 | 74 | 39 |
| Roasso | J2 | 13 | 7 | 18 | 53 | 62 |
| Trinita | J2 | 10 | 13 | 15 | 33 | 47 |
| Tegevajaro | J3 | 12 | 10 | 16 | 46 | 50 |
| United FC | J2 | 7 | 9 | 22 | 35 | 59 |
teams <- data.frame(
names = c("Avispa", "Giravanz", "Sagan", "V-Varen", "Roasso", "Trinita", "Tegevajaro", "United FC"),
division = c("J1", "J3", "J1", "J2", "J2", "J2", "J3", "J2"),
wins = c(12, 15, 10, 21, 13, 10, 12, 7),
draws = c(14, 11, 5, 12, 7, 13, 10, 9),
goals_for = c(33, 41, 48, 74, 53, 33, 46, 35),
goals_against = c(38, 39, 68, 39, 62, 47, 50, 59)
)
teams names division wins draws goals_for goals_against
1 Avispa J1 12 14 33 38
2 Giravanz J3 15 11 41 39
3 Sagan J1 10 5 48 68
4 V-Varen J2 21 12 74 39
5 Roasso J2 13 7 53 62
6 Trinita J2 10 13 33 47
7 Tegevajaro J3 12 10 46 50
8 United FC J2 7 9 35 59ただし、実際の分析ではデータは外部ファイルから読み込むことが多く、このようにコードを書いてデータフレームを作成する場面は少ないとは思います(外部ファイルからデータを読み込む方法は、後ほど紹介します)。
データフレームの操作
データフレームの大きさ(行数と列数)を知るには、dim関数を使います。 行数のみを出力するnrow関数や、列数のみを出力するncol関数もあります。 これらから、teamsは8行6列のデータフレームであることがわかります。
# 行数と列数
dim(teams)[1] 8 6# 行数
nrow(teams)[1] 8# 列数
ncol(teams)[1] 6データフレームから要素を抽出するには、以下に示すような方法があります。
# 行番号と列番号を指定する
teams[3, 2][1] "J1"# 行を抜き出す
teams[c(2, 3), ] names division wins draws goals_for goals_against
2 Giravanz J3 15 11 41 39
3 Sagan J1 10 5 48 68# 列を抜き出す
teams[, 1][1] "Avispa" "Giravanz" "Sagan" "V-Varen" "Roasso"
[6] "Trinita" "Tegevajaro" "United FC" teams[, "names"][1] "Avispa" "Giravanz" "Sagan" "V-Varen" "Roasso"
[6] "Trinita" "Tegevajaro" "United FC" teams$names[1] "Avispa" "Giravanz" "Sagan" "V-Varen" "Roasso"
[6] "Trinita" "Tegevajaro" "United FC" # 値が条件を満たすものを抜き出す
teams[teams$division == "J1", ] names division wins draws goals_for goals_against
1 Avispa J1 12 14 33 38
3 Sagan J1 10 5 48 68teams[teams$goals_against > 60, ] names division wins draws goals_for goals_against
3 Sagan J1 10 5 48 68
5 Roasso J2 13 7 53 62dplyrによるデータフレーム操作
外部ファイルの読み込み
分析に使うデータは、Microsoft Excel形式など、外部ファイルとして準備することが多いと思います。 ここでは、CSV(Comma-Separated Values:カンマ区切り値)ファイルとExcelファイルをRで読み込む方法を説明します。
サンプルファイルとして、saga.csvとsaga.xlsxの2つのファイルを用意したので、下のリンクからダウンロードしてください。 ダウンロードしたファイルは、プロジェクトフォルダの中に[data]というフォルダを作成し、その中に保存することにしましょう。
ダウンロードしたファイルを開いて、それぞれの中身を確認してみてください。
CSVファイル
Rには、read.csvというCSVファイルを読み込むための関数が用意されています。 しかし、ここでは、より柔軟性の高いreadrパッケージのread_csv関数を使います。
library(readr)
dat <- read_csv("data/saga.csv")Rows: 20 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): name
dbl (5): code, population, pop_male, pop_female, households
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.dat# A tibble: 20 × 6
code name population pop_male pop_female households
<dbl> <chr> <dbl> <dbl> <dbl> <dbl>
1 412015 佐賀市 236372 111453 124919 93306
2 412023 唐津市 122785 57547 65238 43872
3 412031 鳥栖市 72902 34799 38103 27630
4 412040 多久市 19749 9146 10603 6847
5 412058 伊万里市 55238 26395 28843 19698
6 412066 武雄市 49062 23178 25884 16932
7 412074 鹿島市 29684 13920 15764 10124
8 412082 小城市 44259 20823 23436 14769
9 412091 嬉野市 27336 12667 14669 9214
10 412104 神埼市 31842 15172 16670 10913
11 413275 吉野ヶ里町 16411 8136 8275 5891
12 413411 基山町 17501 8266 9235 6321
13 413453 上峰町 9283 4379 4904 3260
14 413461 みやき町 25278 11969 13309 8638
15 413879 玄海町 5902 3035 2867 1918
16 414018 有田町 20148 9356 10792 6900
17 414239 大町町 6777 3077 3700 2560
18 414247 江北町 9583 4497 5086 3225
19 414255 白石町 23941 11133 12808 7253
20 414417 太良町 8779 4125 4654 2838Excelファイル
Excelファイルを読むには、readxlライブラリのread_excel関数が便利です。
library(readxl)
dat1 <- read_excel("data/saga.xlsx")
dat1# A tibble: 20 × 6
code name population pop_male pop_female households
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 412015 佐賀市 236372 111453 124919 93306
2 412023 唐津市 122785 57547 65238 43872
3 412031 鳥栖市 72902 34799 38103 27630
4 412040 多久市 19749 9146 10603 6847
5 412058 伊万里市 55238 26395 28843 19698
6 412066 武雄市 49062 23178 25884 16932
7 412074 鹿島市 29684 13920 15764 10124
8 412082 小城市 44259 20823 23436 14769
9 412091 嬉野市 27336 12667 14669 9214
10 412104 神埼市 31842 15172 16670 10913
11 413275 吉野ヶ里町 16411 8136 8275 5891
12 413411 基山町 17501 8266 9235 6321
13 413453 上峰町 9283 4379 4904 3260
14 413461 みやき町 25278 11969 13309 8638
15 413879 玄海町 5902 3035 2867 1918
16 414018 有田町 20148 9356 10792 6900
17 414239 大町町 6777 3077 3700 2560
18 414247 江北町 9583 4497 5086 3225
19 414255 白石町 23941 11133 12808 7253
20 414417 太良町 8779 4125 4654 2838
ノート
ところで、先ほどのファイル入力の結果に、tibbleという文字列があるのに気づいた人がいるかもしれません。tibbleは、Rのデータフレームの発展系の1つで、データフレームの代わりによく使われるデータ構造です。read_csv関数やread_excel関数で読み込んだデータは、自動的にtibbleになります。この講義では、データフレームとtibbleを特に区別せずに説明します。
dplyrパッケージの関数群によるデータフレームの操作
Rにある関数だけでも、ある程度データフレームの操作が可能です。 しかし、dplyrパッケージの関数群を用いることで、より直感的に、より柔軟にデータフレームを操作することができます。 dplyrパッケージの関数群を使いこなすことが、データ処理の技術向上の近道です。
行の操作
行を抽出するには、filter関数やslice関数などを使います。 例えば、人口が10万人以上の自治体を取り出したい場合には、filter関数が便利です。
library(dplyr)
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, unionfilter(dat, population > 100000)# A tibble: 2 × 6
code name population pop_male pop_female households
<dbl> <chr> <dbl> <dbl> <dbl> <dbl>
1 412015 佐賀市 236372 111453 124919 93306
2 412023 唐津市 122785 57547 65238 43872特定の行を、行番号を使って取り出したい時には、slice関数が使えます。
slice(dat, 4:6)# A tibble: 3 × 6
code name population pop_male pop_female households
<dbl> <chr> <dbl> <dbl> <dbl> <dbl>
1 412040 多久市 19749 9146 10603 6847
2 412058 伊万里市 55238 26395 28843 19698
3 412066 武雄市 49062 23178 25884 16932データを列の数値によって並べ替える(例えば、人口の多い順に並べ替える)にはarrange関数を使います。
arrange(dat, desc(population))# A tibble: 20 × 6
code name population pop_male pop_female households
<dbl> <chr> <dbl> <dbl> <dbl> <dbl>
1 412015 佐賀市 236372 111453 124919 93306
2 412023 唐津市 122785 57547 65238 43872
3 412031 鳥栖市 72902 34799 38103 27630
4 412058 伊万里市 55238 26395 28843 19698
5 412066 武雄市 49062 23178 25884 16932
6 412082 小城市 44259 20823 23436 14769
7 412104 神埼市 31842 15172 16670 10913
8 412074 鹿島市 29684 13920 15764 10124
9 412091 嬉野市 27336 12667 14669 9214
10 413461 みやき町 25278 11969 13309 8638
11 414255 白石町 23941 11133 12808 7253
12 414018 有田町 20148 9356 10792 6900
13 412040 多久市 19749 9146 10603 6847
14 413411 基山町 17501 8266 9235 6321
15 413275 吉野ヶ里町 16411 8136 8275 5891
16 414247 江北町 9583 4497 5086 3225
17 413453 上峰町 9283 4379 4904 3260
18 414417 太良町 8779 4125 4654 2838
19 414239 大町町 6777 3077 3700 2560
20 413879 玄海町 5902 3035 2867 1918
ノート
desc関数は、ベクトルを降順に並べ替えるdplyrパッケージの関数で、arrange関数と一緒に使うことが多いです。
列の操作
列を抽出するには、select関数を使います。
select(dat, name, population)# A tibble: 20 × 2
name population
<chr> <dbl>
1 佐賀市 236372
2 唐津市 122785
3 鳥栖市 72902
4 多久市 19749
5 伊万里市 55238
6 武雄市 49062
7 鹿島市 29684
8 小城市 44259
9 嬉野市 27336
10 神埼市 31842
11 吉野ヶ里町 16411
12 基山町 17501
13 上峰町 9283
14 みやき町 25278
15 玄海町 5902
16 有田町 20148
17 大町町 6777
18 江北町 9583
19 白石町 23941
20 太良町 8779select(dat, pop_male:pop_female)# A tibble: 20 × 2
pop_male pop_female
<dbl> <dbl>
1 111453 124919
2 57547 65238
3 34799 38103
4 9146 10603
5 26395 28843
6 23178 25884
7 13920 15764
8 20823 23436
9 12667 14669
10 15172 16670
11 8136 8275
12 8266 9235
13 4379 4904
14 11969 13309
15 3035 2867
16 9356 10792
17 3077 3700
18 4497 5086
19 11133 12808
20 4125 4654select(dat, !(pop_male:pop_female))# A tibble: 20 × 4
code name population households
<dbl> <chr> <dbl> <dbl>
1 412015 佐賀市 236372 93306
2 412023 唐津市 122785 43872
3 412031 鳥栖市 72902 27630
4 412040 多久市 19749 6847
5 412058 伊万里市 55238 19698
6 412066 武雄市 49062 16932
7 412074 鹿島市 29684 10124
8 412082 小城市 44259 14769
9 412091 嬉野市 27336 9214
10 412104 神埼市 31842 10913
11 413275 吉野ヶ里町 16411 5891
12 413411 基山町 17501 6321
13 413453 上峰町 9283 3260
14 413461 みやき町 25278 8638
15 413879 玄海町 5902 1918
16 414018 有田町 20148 6900
17 414239 大町町 6777 2560
18 414247 江北町 9583 3225
19 414255 白石町 23941 7253
20 414417 太良町 8779 2838select(dat, starts_with("pop"))# A tibble: 20 × 3
population pop_male pop_female
<dbl> <dbl> <dbl>
1 236372 111453 124919
2 122785 57547 65238
3 72902 34799 38103
4 19749 9146 10603
5 55238 26395 28843
6 49062 23178 25884
7 29684 13920 15764
8 44259 20823 23436
9 27336 12667 14669
10 31842 15172 16670
11 16411 8136 8275
12 17501 8266 9235
13 9283 4379 4904
14 25278 11969 13309
15 5902 3035 2867
16 20148 9356 10792
17 6777 3077 3700
18 9583 4497 5086
19 23941 11133 12808
20 8779 4125 4654
ノート
starts_withの他に、ends_with、containsなど、類似のヘルパー関数が用意されています。
select関数を使って列名を変更することができます。
select(dat, pop = population)# A tibble: 20 × 1
pop
<dbl>
1 236372
2 122785
3 72902
4 19749
5 55238
6 49062
7 29684
8 44259
9 27336
10 31842
11 16411
12 17501
13 9283
14 25278
15 5902
16 20148
17 6777
18 9583
19 23941
20 8779しかし、select関数では、列名を変更した列以外が削除されてします。その他の列も残したい場合は、rename関数を使うとよいです。
rename(dat, pop = population)# A tibble: 20 × 6
code name pop pop_male pop_female households
<dbl> <chr> <dbl> <dbl> <dbl> <dbl>
1 412015 佐賀市 236372 111453 124919 93306
2 412023 唐津市 122785 57547 65238 43872
3 412031 鳥栖市 72902 34799 38103 27630
4 412040 多久市 19749 9146 10603 6847
5 412058 伊万里市 55238 26395 28843 19698
6 412066 武雄市 49062 23178 25884 16932
7 412074 鹿島市 29684 13920 15764 10124
8 412082 小城市 44259 20823 23436 14769
9 412091 嬉野市 27336 12667 14669 9214
10 412104 神埼市 31842 15172 16670 10913
11 413275 吉野ヶ里町 16411 8136 8275 5891
12 413411 基山町 17501 8266 9235 6321
13 413453 上峰町 9283 4379 4904 3260
14 413461 みやき町 25278 11969 13309 8638
15 413879 玄海町 5902 3035 2867 1918
16 414018 有田町 20148 9356 10792 6900
17 414239 大町町 6777 3077 3700 2560
18 414247 江北町 9583 4497 5086 3225
19 414255 白石町 23941 11133 12808 7253
20 414417 太良町 8779 4125 4654 2838新しい列を追加するにはmutate関数を使います。
mutate(dat, household_size = population / households)# A tibble: 20 × 7
code name population pop_male pop_female households household_size
<dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 412015 佐賀市 236372 111453 124919 93306 2.53
2 412023 唐津市 122785 57547 65238 43872 2.80
3 412031 鳥栖市 72902 34799 38103 27630 2.64
4 412040 多久市 19749 9146 10603 6847 2.88
5 412058 伊万里市 55238 26395 28843 19698 2.80
6 412066 武雄市 49062 23178 25884 16932 2.90
7 412074 鹿島市 29684 13920 15764 10124 2.93
8 412082 小城市 44259 20823 23436 14769 3.00
9 412091 嬉野市 27336 12667 14669 9214 2.97
10 412104 神埼市 31842 15172 16670 10913 2.92
11 413275 吉野ヶ里町 16411 8136 8275 5891 2.79
12 413411 基山町 17501 8266 9235 6321 2.77
13 413453 上峰町 9283 4379 4904 3260 2.85
14 413461 みやき町 25278 11969 13309 8638 2.93
15 413879 玄海町 5902 3035 2867 1918 3.08
16 414018 有田町 20148 9356 10792 6900 2.92
17 414239 大町町 6777 3077 3700 2560 2.65
18 414247 江北町 9583 4497 5086 3225 2.97
19 414255 白石町 23941 11133 12808 7253 3.30
20 414417 太良町 8779 4125 4654 2838 3.09mutate(
dat,
male_ratio = pop_male / population,
female_ratio = pop_female / population
)# A tibble: 20 × 8
code name population pop_male pop_female households male_ratio
<dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 412015 佐賀市 236372 111453 124919 93306 0.472
2 412023 唐津市 122785 57547 65238 43872 0.469
3 412031 鳥栖市 72902 34799 38103 27630 0.477
4 412040 多久市 19749 9146 10603 6847 0.463
5 412058 伊万里市 55238 26395 28843 19698 0.478
6 412066 武雄市 49062 23178 25884 16932 0.472
7 412074 鹿島市 29684 13920 15764 10124 0.469
8 412082 小城市 44259 20823 23436 14769 0.470
9 412091 嬉野市 27336 12667 14669 9214 0.463
10 412104 神埼市 31842 15172 16670 10913 0.476
11 413275 吉野ヶ里町 16411 8136 8275 5891 0.496
12 413411 基山町 17501 8266 9235 6321 0.472
13 413453 上峰町 9283 4379 4904 3260 0.472
14 413461 みやき町 25278 11969 13309 8638 0.473
15 413879 玄海町 5902 3035 2867 1918 0.514
16 414018 有田町 20148 9356 10792 6900 0.464
17 414239 大町町 6777 3077 3700 2560 0.454
18 414247 江北町 9583 4497 5086 3225 0.469
19 414255 白石町 23941 11133 12808 7253 0.465
20 414417 太良町 8779 4125 4654 2838 0.470
# ℹ 1 more variable: female_ratio <dbl>データフレームの結合
自治体の面積データを読み込み、先ほどのデータと結合するという操作を行いましょう。 以下のsaga2.csvをダウンロードし、dataフォルダに移動してください。
dat2 <- read_csv("data/saga2.csv")Rows: 26 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): name
dbl (2): code, area
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.dat2# A tibble: 26 × 3
code name area
<dbl> <chr> <dbl>
1 412015 佐賀市 432.
2 412023 唐津市 488.
3 412031 鳥栖市 71.7
4 412040 多久市 97.0
5 412058 伊万里市 255.
6 412066 武雄市 195.
7 412074 鹿島市 112.
8 412082 小城市 95.8
9 412091 嬉野市 126.
10 412104 神埼市 125.
# ℹ 16 more rowsこれを見ると、26行のデータフレームになっています。市町のデータだけでなく、6つある郡のデータが入っているようです。このdatとdat2を結合するにはどうすればよいでしょうか。
やや泥臭いですが、dat2の中から、datに含まれる行だけを抽出し、並び順を整え、面積データだけを取り出したデータフレームdat3を作成します。 dplyrパッケージに含まれる関数を駆使しています。
dat3 <- filter(dat2, name %in% dat$name)
dat3 <- arrange(dat3, code)
dat3 <- select(dat3, area)
dat3# A tibble: 20 × 1
area
<dbl>
1 432.
2 488.
3 71.7
4 97.0
5 255.
6 195.
7 112.
8 95.8
9 126.
10 125.
11 44.0
12 22.2
13 12.8
14 51.9
15 35.9
16 65.8
17 11.5
18 24.5
19 99.6
20 74.3dplyrのbind_cols関数を使って、2つのデータフレームを結合することができます。
bind_cols(dat, dat3)# A tibble: 20 × 7
code name population pop_male pop_female households area
<dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 412015 佐賀市 236372 111453 124919 93306 432.
2 412023 唐津市 122785 57547 65238 43872 488.
3 412031 鳥栖市 72902 34799 38103 27630 71.7
4 412040 多久市 19749 9146 10603 6847 97.0
5 412058 伊万里市 55238 26395 28843 19698 255.
6 412066 武雄市 49062 23178 25884 16932 195.
7 412074 鹿島市 29684 13920 15764 10124 112.
8 412082 小城市 44259 20823 23436 14769 95.8
9 412091 嬉野市 27336 12667 14669 9214 126.
10 412104 神埼市 31842 15172 16670 10913 125.
11 413275 吉野ヶ里町 16411 8136 8275 5891 44.0
12 413411 基山町 17501 8266 9235 6321 22.2
13 413453 上峰町 9283 4379 4904 3260 12.8
14 413461 みやき町 25278 11969 13309 8638 51.9
15 413879 玄海町 5902 3035 2867 1918 35.9
16 414018 有田町 20148 9356 10792 6900 65.8
17 414239 大町町 6777 3077 3700 2560 11.5
18 414247 江北町 9583 4497 5086 3225 24.5
19 414255 白石町 23941 11133 12808 7253 99.6
20 414417 太良町 8779 4125 4654 2838 74.3もっとスマートな方法があります。 それは、left_join関数を使う方法です。
left_join(dat, dat2)Joining with `by = join_by(code, name)`# A tibble: 20 × 7
code name population pop_male pop_female households area
<dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 412015 佐賀市 236372 111453 124919 93306 432.
2 412023 唐津市 122785 57547 65238 43872 488.
3 412031 鳥栖市 72902 34799 38103 27630 71.7
4 412040 多久市 19749 9146 10603 6847 97.0
5 412058 伊万里市 55238 26395 28843 19698 255.
6 412066 武雄市 49062 23178 25884 16932 195.
7 412074 鹿島市 29684 13920 15764 10124 112.
8 412082 小城市 44259 20823 23436 14769 95.8
9 412091 嬉野市 27336 12667 14669 9214 126.
10 412104 神埼市 31842 15172 16670 10913 125.
11 413275 吉野ヶ里町 16411 8136 8275 5891 44.0
12 413411 基山町 17501 8266 9235 6321 22.2
13 413453 上峰町 9283 4379 4904 3260 12.8
14 413461 みやき町 25278 11969 13309 8638 51.9
15 413879 玄海町 5902 3035 2867 1918 35.9
16 414018 有田町 20148 9356 10792 6900 65.8
17 414239 大町町 6777 3077 3700 2560 11.5
18 414247 江北町 9583 4497 5086 3225 24.5
19 414255 白石町 23941 11133 12808 7253 99.6
20 414417 太良町 8779 4125 4654 2838 74.3この関数は、2つのデータフレームから共通の名前を持つ列を探して、それらの列の値をキーにして、自動的に2つのデータフレームを結合します。
ノート
left_joinの他にも、inner_join、right_join、full_joinといった類似の関数が用意されています。それぞれどのように異なるのか、RStudioのヘルプ機能を使って調べてみましょう。
課題
今日作成したR Scriptファイル(ファイル名を「あなたの学籍番号.R」にしてください)を、LiveCampusから提出してください。 (締切:4月30日(水)14:00)