library(tidyverse)
library(readxl)
library(sf)
library(mapview)5: 空間データの構造と操作
はじめに
空間データは、現実の地物の位置や形状を表すだけでなく、(地名や地価など)さまざまな属性データも持っていることを学びました。 今回は、この属性データと空間データを操作する代表的な方法をいくつか紹介します。
属性データの操作
属性データとは、空間データのうち、位置(座標)以外のデータのことを意味しますが、 ここでは、より意味を限定して、空間データに紐づいた統計データのことを属性データと呼ぶことにします。 sfバッケージを用いると、属性データを通常のデータフレームと同じように扱うことができます。 今回の演習を進めるうちに、その内容が、第2回の演習内容(dplyrによるデータフレーム操作)とほぼ同じであることに気がつくと思います。
属性データの演算
この演習では、国勢調査の小地域データを使います。 はじめに、佐賀市の小地域データをダウンロードしましょう。
国勢調査小地域データ:e-Statからのダウンロード
e-Statから国勢調査の小地域データをダウンロードし、地図に表示してみます。
小地域とは
小地域は、統計の分野においては、市区町村よりも小さな地域のことを指します。 町丁・字(あざ)等の別に人口や世帯数などを統計したものを、小地域統計と呼びます。
e-Statのウェブサイトをブラウザで開きます。
[地図]をクリックします。
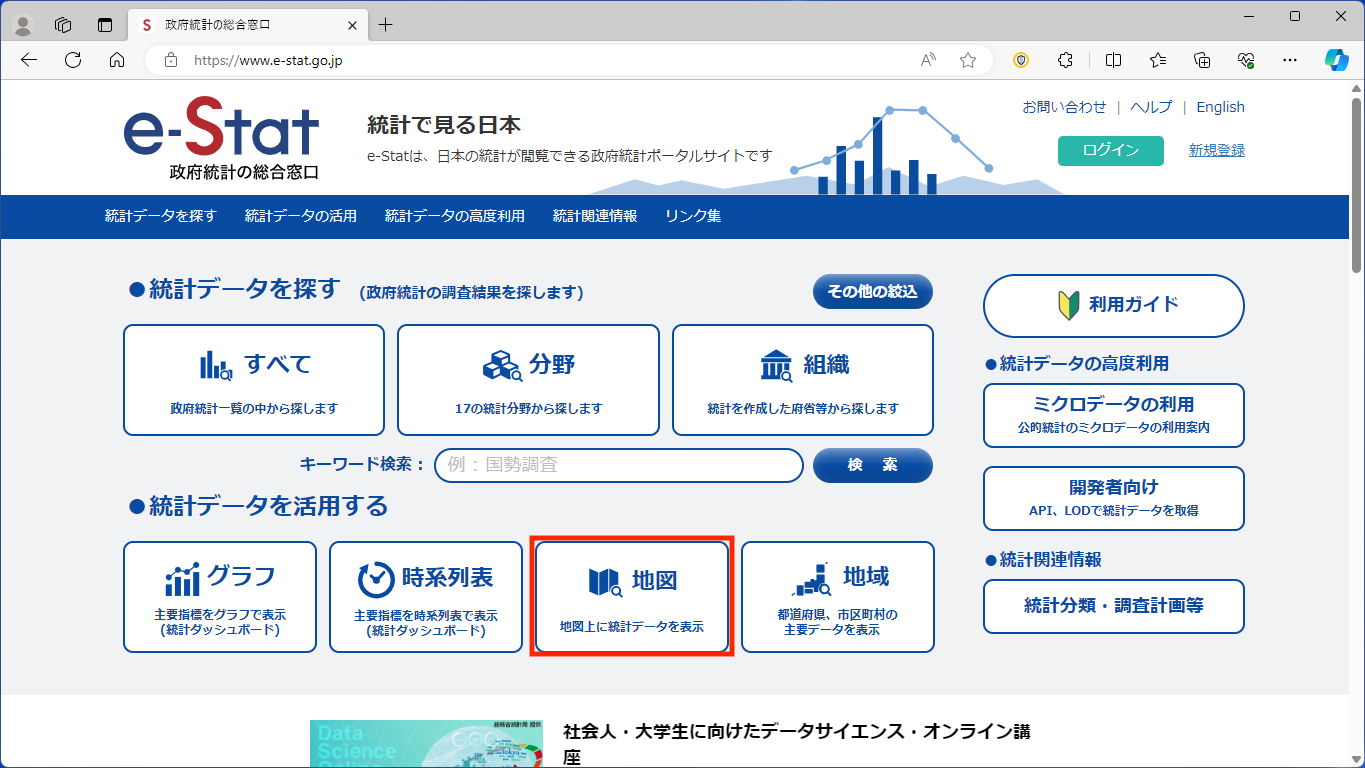
[>境界データダウンロード]をクリックします。
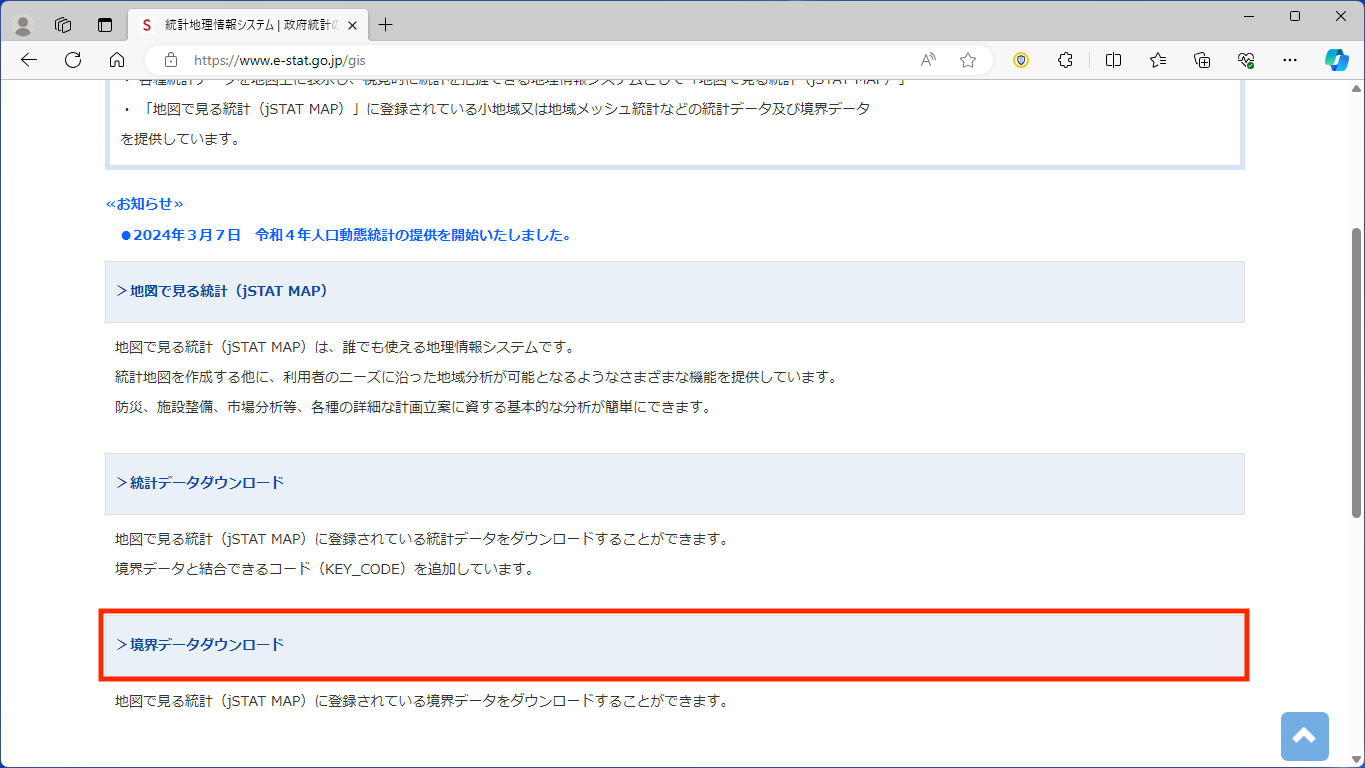
小地域をクリックします。
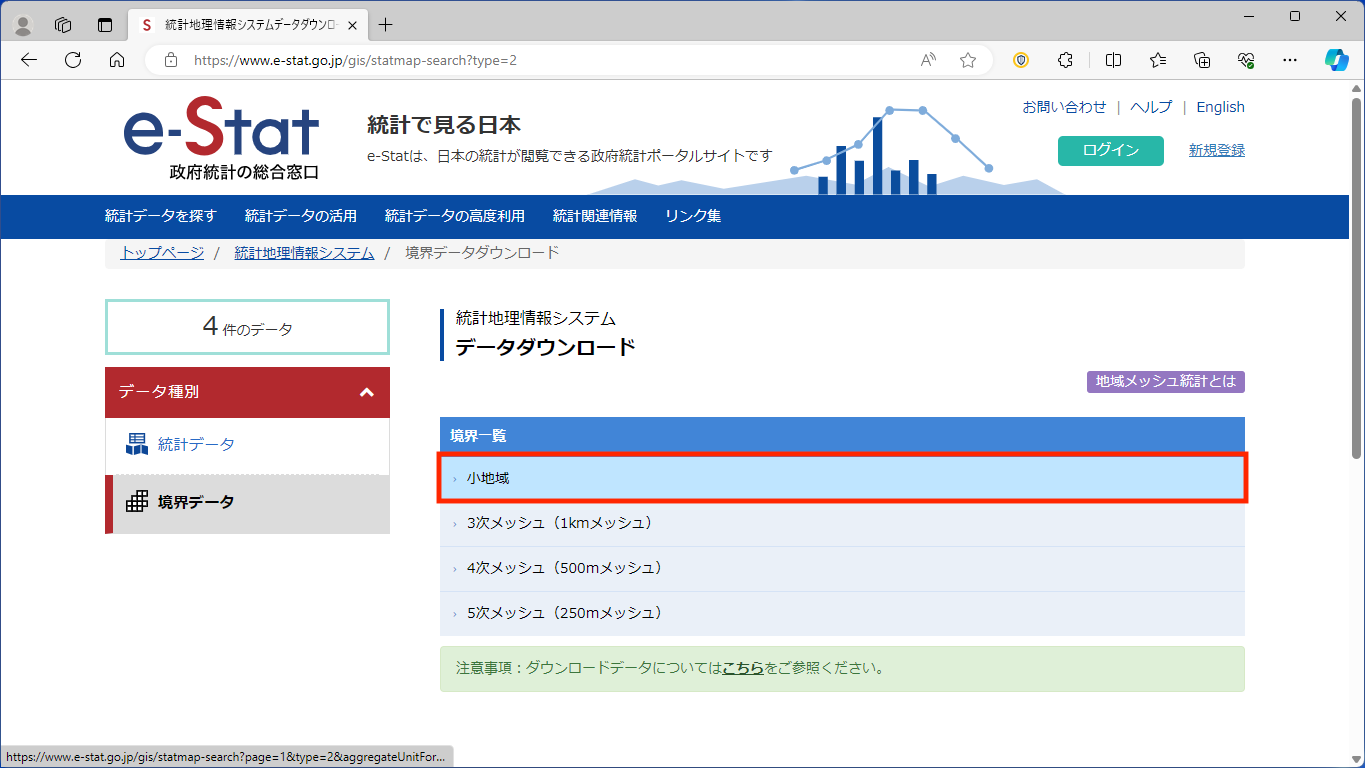
[国勢調査]をクリックします。
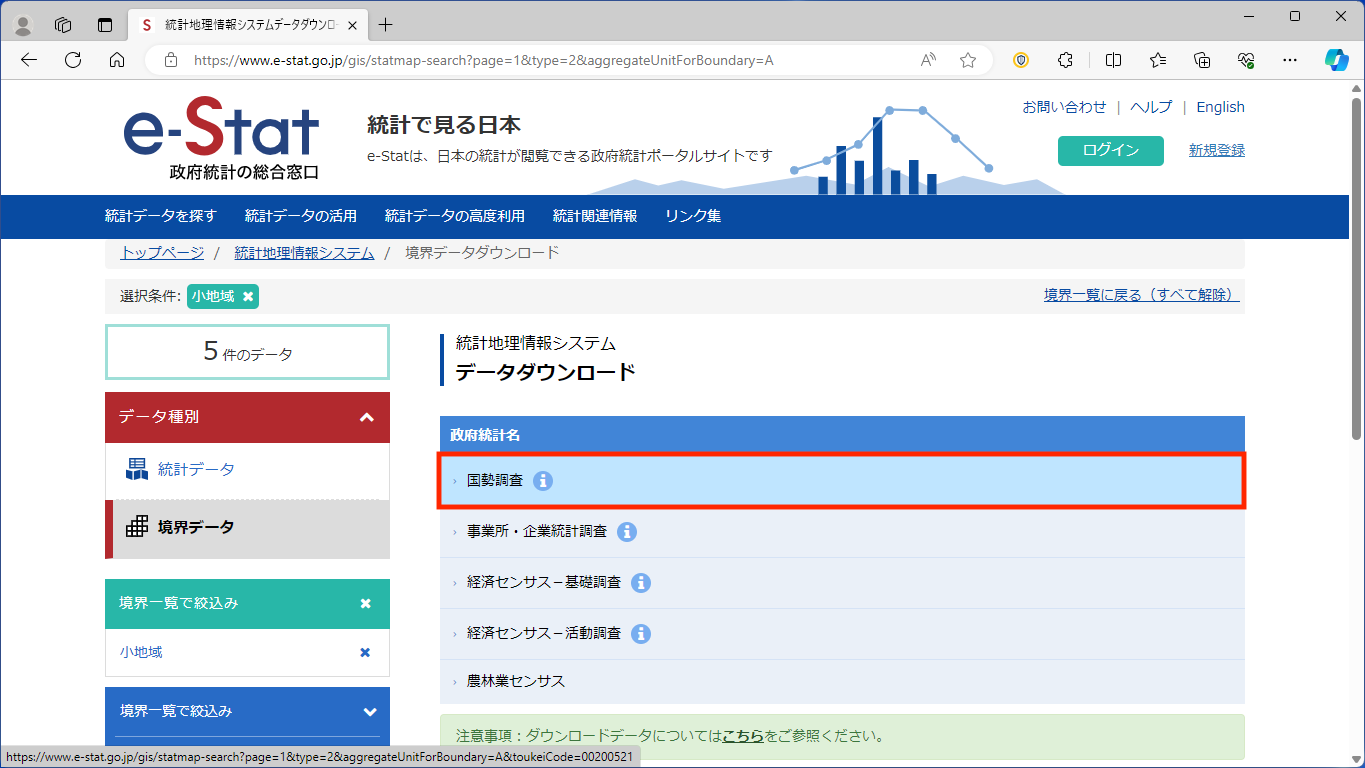
ここでは最新の統計である2020年を選びましょう。
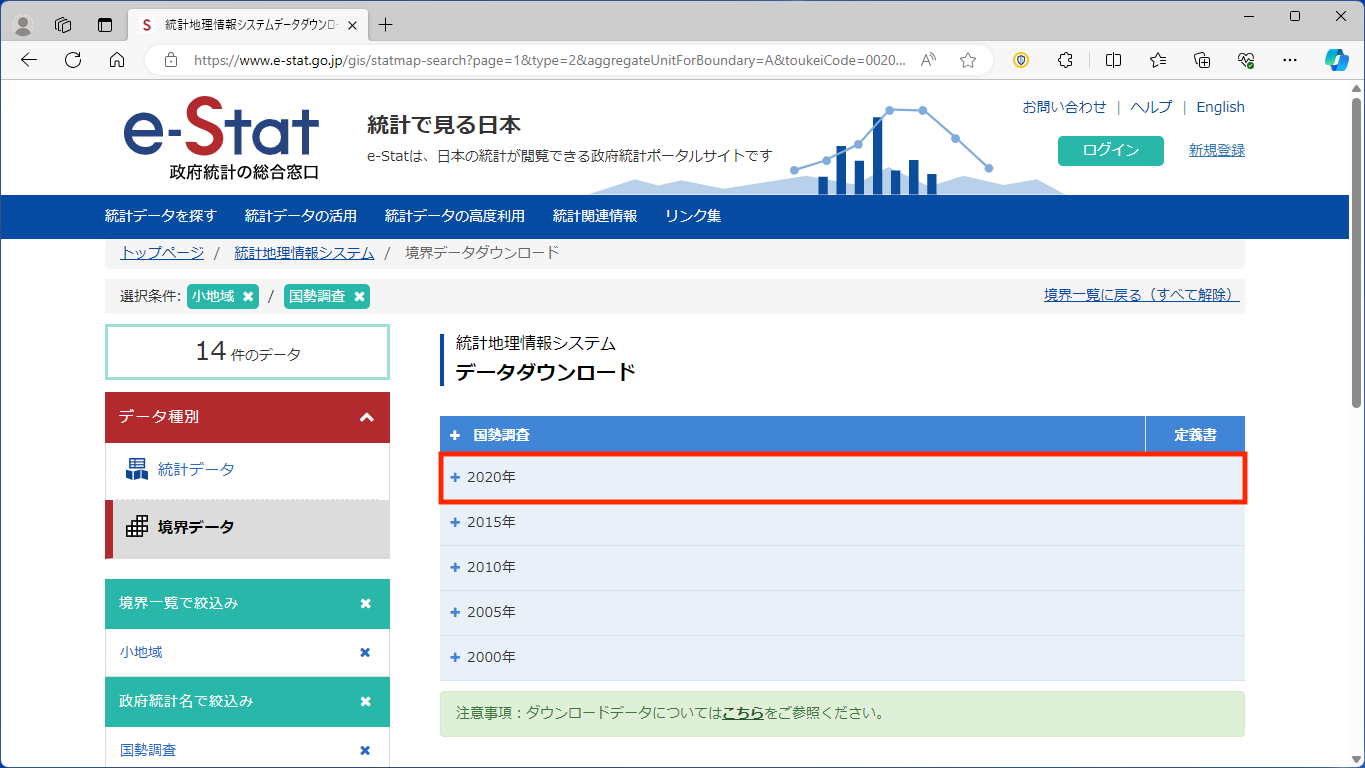
「小地域(町丁・字等)(JGD2011)」をクリックします。
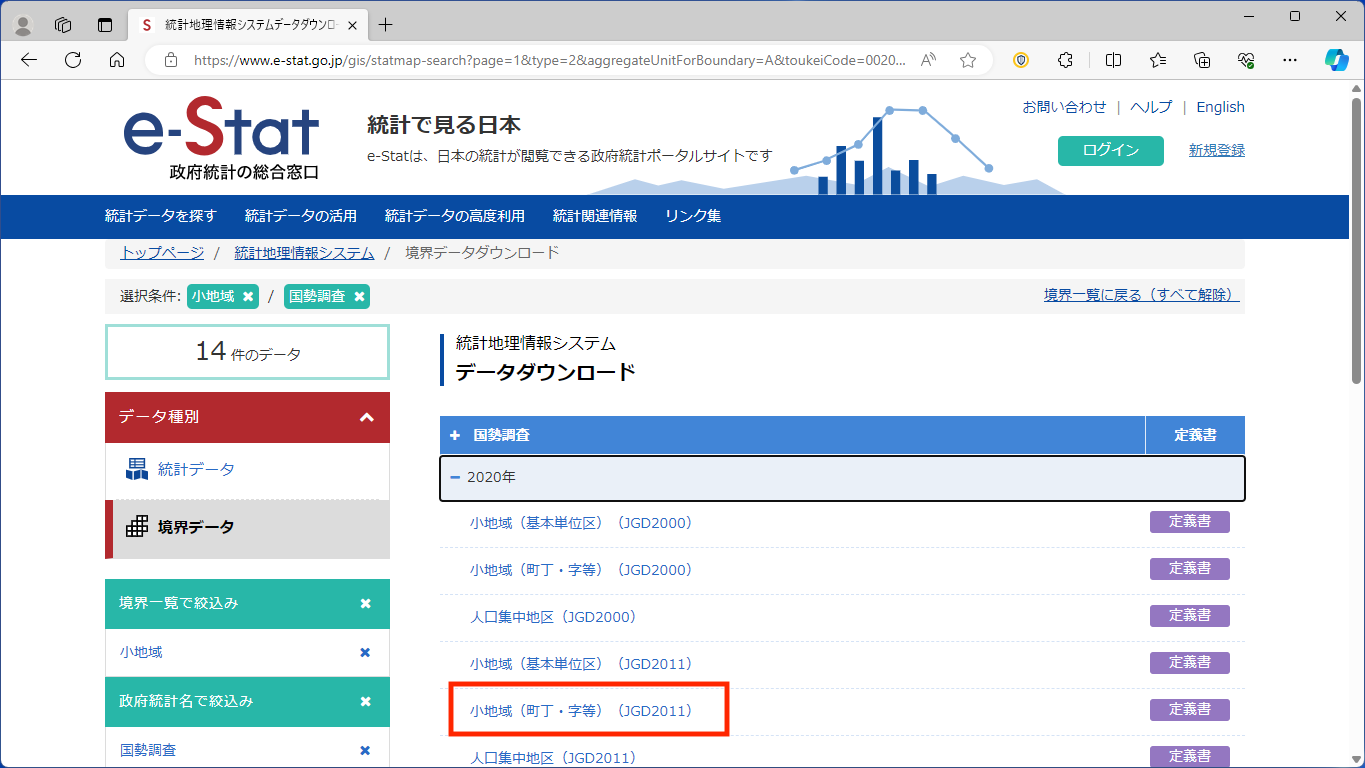
ここでは、座標系は「世界測地系緯度経度」、データ形式は「Shapefile」を選択します。
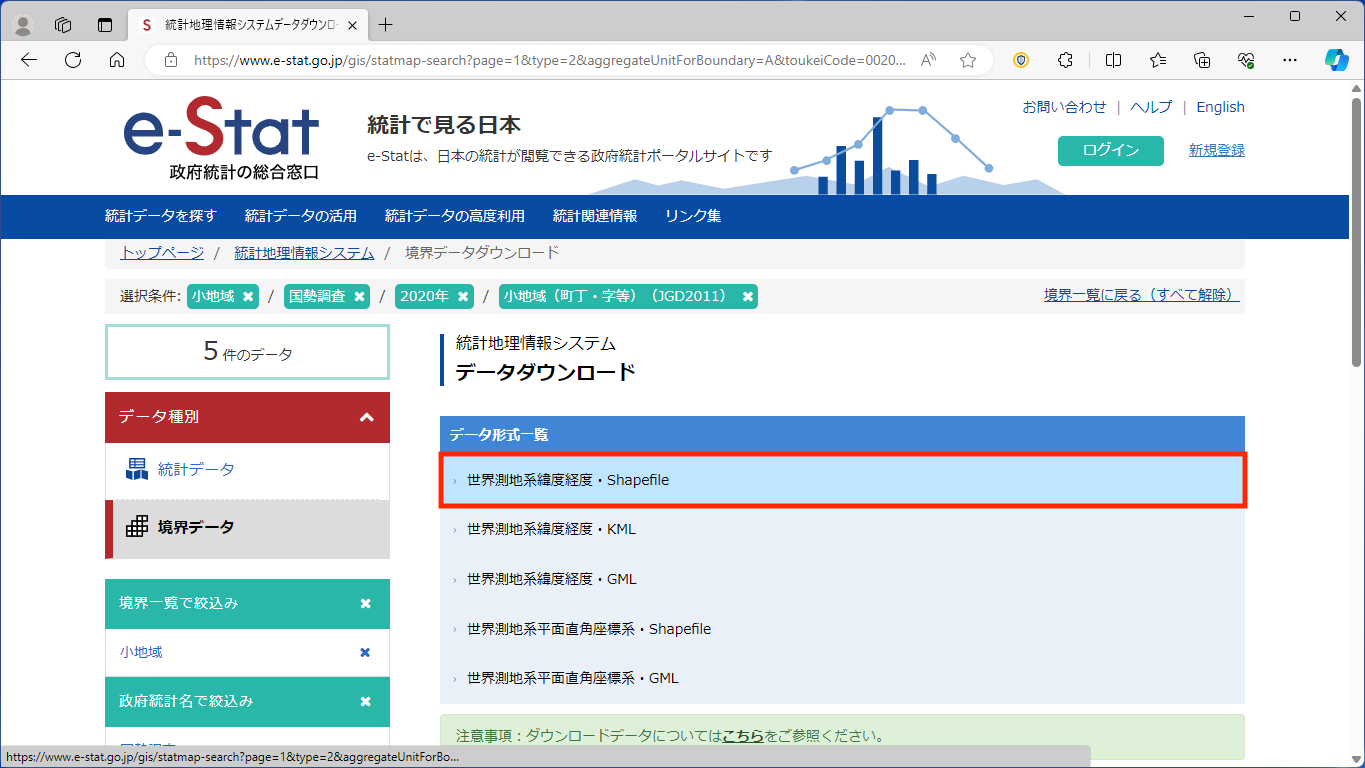
[都道府県で絞り込みはコチラ]をクリックします。
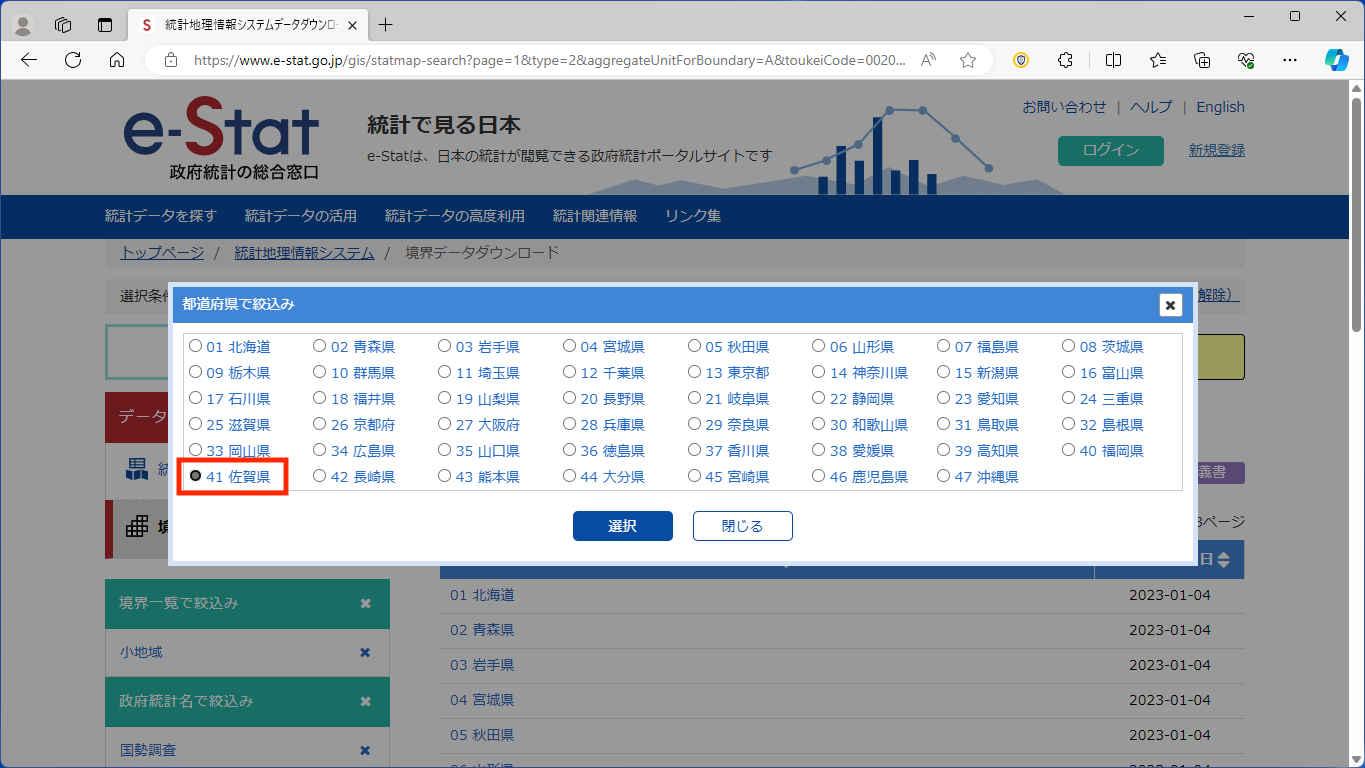
都道府県のラジオボタンが並んだウィンドウが開いたら、[佐賀県]のラジオボタンをオンにし、[選択]をクリックします。
佐賀市の行にある[世界測地系緯度経度・Shapefile]と書かれたボタンをクリックすると、データのダウンロードが始まります。
ダウンロードが完了したら、フォルダを展開し、dataフォルダに移動しましょう(ダウンロード後のファイル展開の方法などは、前回と同じなので、ここでは説明を省略します)。
小地域データの操作:人口密度の計算
それでは、ダウンロードした国勢調査の小地域データを地図に表示してみましょう。
まず、使うパッケージをロードします。
ダウンロードした小地域データを、sfパッケージのst_read関数を使って読み込みます。 読み込んだデータは、変数districtに代入することにします。
district <- st_read("data/A002005212020DDSWC41201-JGD2011/r2ka41201.shp")Reading layer `r2ka41201' from data source
`/Users/kzktmr/Documents/LectureNotes/EconomicGeography/data/A002005212020DDSWC41201-JGD2011/r2ka41201.shp'
using driver `ESRI Shapefile'
Simple feature collection with 484 features and 29 fields
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: 130.1393 ymin: 33.14109 xmax: 130.3794 ymax: 33.48151
Geodetic CRS: JGD2011mapview関数を使って、地図に表示しましょう。
mapview(district)これを見ると、佐賀市にはたくさんの小地域があることが分かります。 また、地図の中の小地域をクリックすると、たくさんのデータが格納されていることが分かります。 どのようなデータが入っているかは、定義書を見ると分かります。
定義書は、e-Statの先ほどの画面に入手するためのリンクがあります。 リンクをクリックして、定義書をダウンロードしてみましょう。
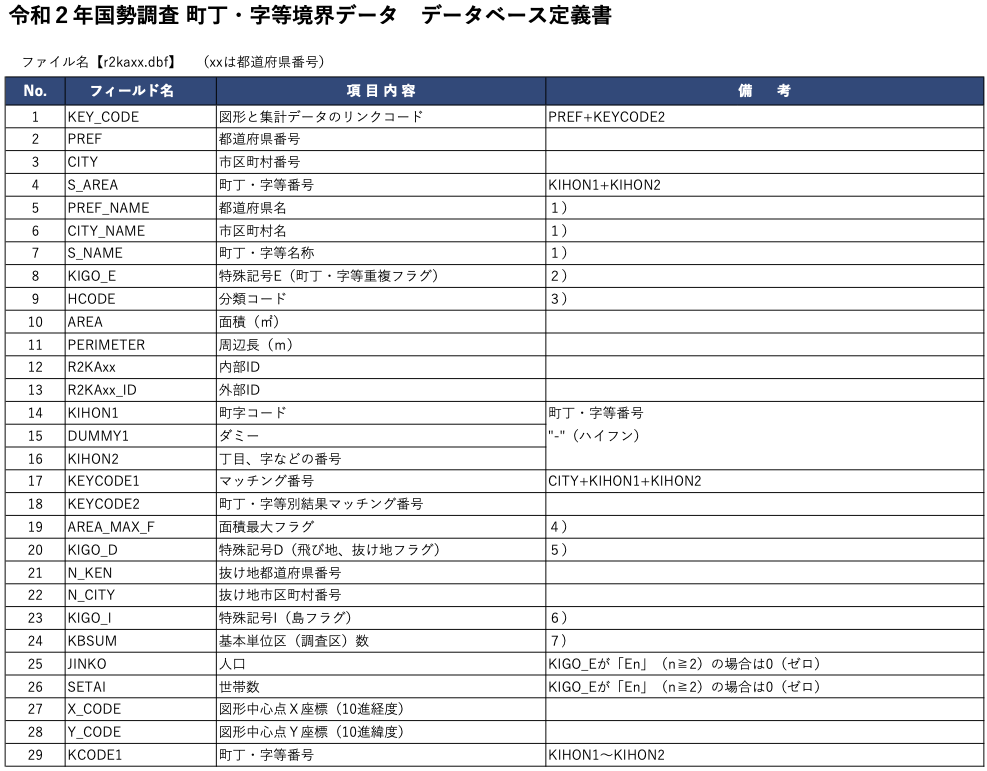
今回使った小地域データの定義書の内容は、このようになっています。 フィールド名とその説明が記述されています。 このフィールド名は、先ほどダウンロードしたデータの属性データの列名と一致しています。
dplyrパッケージのglimpse関数を使って、実際に属性データの中身を確認し、定義書の内容と照らし合わせてみましょう。
glimpse(district)Rows: 484
Columns: 30
$ KEY_CODE <chr> "41201001001", "41201001002", "41201001003", "41201002001",…
$ PREF <chr> "41", "41", "41", "41", "41", "41", "41", "41", "41", "41",…
$ CITY <chr> "201", "201", "201", "201", "201", "201", "201", "201", "20…
$ S_AREA <chr> "001001", "001002", "001003", "002001", "002002", "002003",…
$ PREF_NAME <chr> "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀…
$ CITY_NAME <chr> "佐賀市", "佐賀市", "佐賀市", "佐賀市", "佐賀市", "佐賀市", "佐賀市", "佐賀市", "佐賀…
$ S_NAME <chr> "駅前中央一丁目", "駅前中央二丁目", "駅前中央三丁目", "大財一丁目", "大財二丁目", "大財三丁目",…
$ KIGO_E <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ HCODE <int> 8101, 8101, 8101, 8101, 8101, 8101, 8101, 8101, 8101, 8101,…
$ AREA <dbl> 147281.68, 108748.65, 144423.54, 74548.31, 137859.16, 78556…
$ PERIMETER <dbl> 1528.456, 1371.930, 1875.425, 1150.161, 1900.060, 1455.806,…
$ R2KAxx <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, …
$ R2KAxx_ID <int> 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 1…
$ KIHON1 <chr> "0010", "0010", "0010", "0020", "0020", "0020", "0020", "00…
$ DUMMY1 <chr> "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-",…
$ KIHON2 <chr> "01", "02", "03", "01", "02", "03", "04", "05", "06", "01",…
$ KEYCODE1 <chr> "201001001", "201001002", "201001003", "201002001", "201002…
$ KEYCODE2 <chr> "201001001", "201001002", "201001003", "201002001", "201002…
$ AREA_MAX_F <chr> "M", "M", "M", "M", "M", "M", "M", "M", "M", "M", "M", "M",…
$ KIGO_D <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ N_KEN <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ N_CITY <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ KIGO_I <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ KBSUM <int> 16, 14, 19, 11, 10, 14, 6, 12, 12, 5, 10, 19, 9, 17, 11, 10…
$ JINKO <dbl> 583, 1081, 832, 337, 797, 626, 549, 547, 1181, 131, 558, 10…
$ SETAI <dbl> 378, 576, 432, 202, 413, 357, 307, 242, 528, 54, 259, 481, …
$ X_CODE <dbl> 130.2978, 130.2995, 130.3041, 130.3027, 130.3083, 130.3031,…
$ Y_CODE <dbl> 33.26336, 33.26637, 33.26694, 33.25728, 33.25828, 33.26060,…
$ KCODE1 <chr> "0010-01", "0010-02", "0010-03", "0020-01", "0020-02", "002…
$ geometry <POLYGON [°]> POLYGON ((130.3001 33.26372..., POLYGON ((130.2981 …一番下のgeometryが空間データ(ポリゴンデータ)です。
また、View関数を使うと、データフレームの内容を、スプレッドシートのような形でRStudioに表示して見ることもできます。
View(district)このデータを使って「人口密度による塗り分け地図」を作ってみましょう。 面積のデータ(AREA)と人口のデータ(JINKO)があるので、これらを使うと人口密度を計算できそうです。 データフレームに新たに列を追加するために、dplyrパッケージのmutate関数を使います(第2回の講義資料を参照してください)。
以下のようにして、新たに人口密度のデータ列(density)を追加します。 人口(人)を面積(㎡)で割り、10,000を掛けることで、ヘクタール(ha)当たりの人口密度にしています。
district <- mutate(district, density = JINKO / AREA * 10000)追加したdensityで地図を塗り分けてみましょう。
district <- st_transform(district, 6670)
ggplot() +
geom_sf(aes(fill = density), data = district) +
scale_fill_gradient(low = "white", high = "red")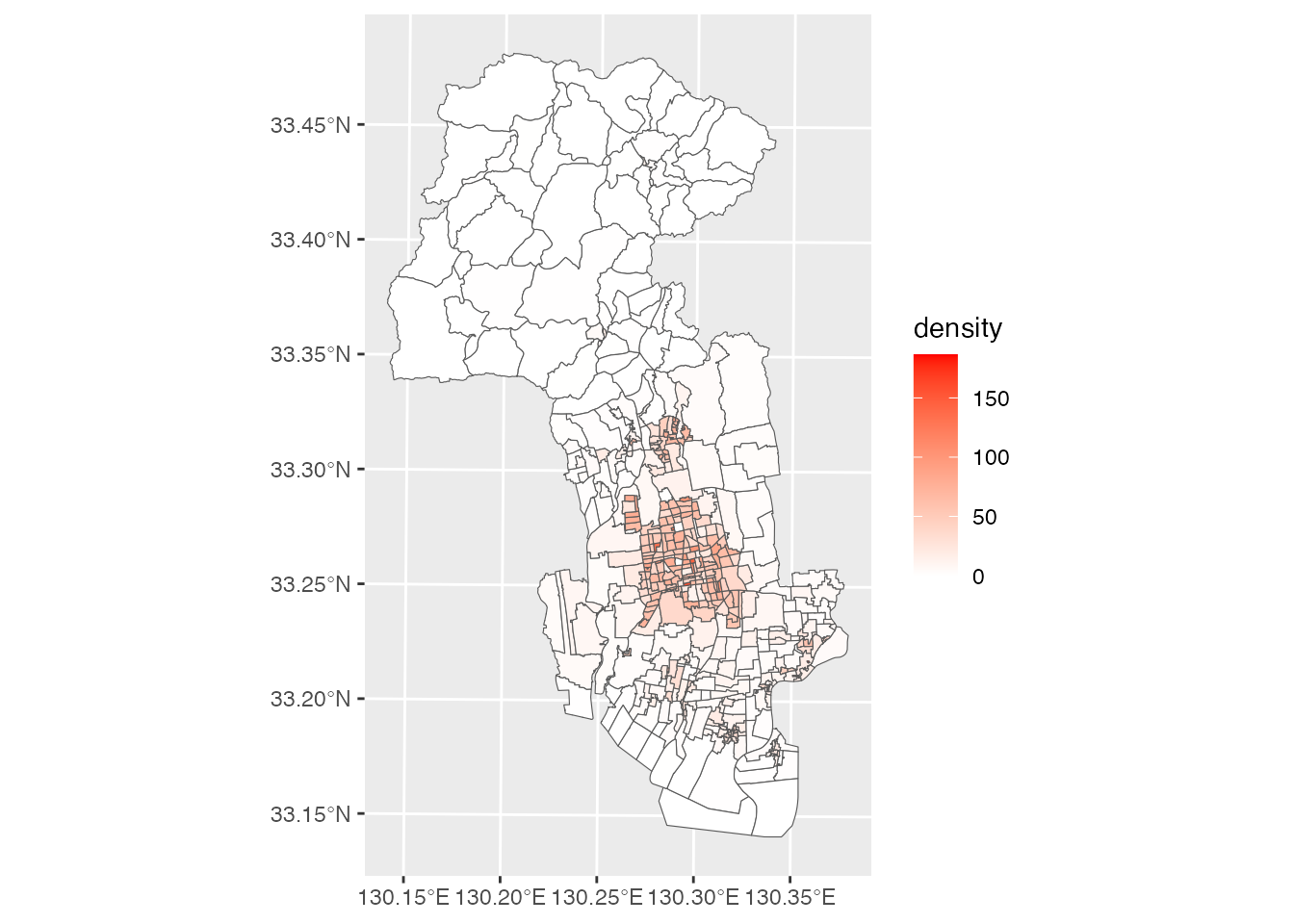
塗り分け地図の色が濃いところほど人口密度が高いことを意味します。佐賀市の中で人口密度が高い地域は、市の中心部に集まっていることが一目瞭然になりました。
パイプ演算子
これ以降の演習では、パイプ演算子|>を使います。 パイプ演算子の使い方を、以下のデータフレームdfを例に説明します。
df <- tibble(x = 1:10, y = letters[1:10])
head(df, 4)# A tibble: 4 × 2
x y
<int> <chr>
1 1 a
2 2 b
3 3 c
4 4 d データフレームを操作するときに、例えばmutate関数を使う場合なら、これまでは
df <- mutate(df, z = x %% 2)と書いていました。 これからは、これと同じ操作を、
df <- df |> mutate(z = x %% 2)と書きます。 パイプ演算子|>は、左辺の出力を右辺の関数の第1引数に渡します。 つまり、x |> f()はf(x)と同じです。 パイプ演算子を使うと、いくつもの処理を繋げて書くことができます。 「流れ作業」のように、処理結果を次々と別の関数に渡していくイメージです。
df |> mutate(z = x %% 2) |> filter(z == 1) |> head(2)# A tibble: 2 × 3
x y z
<int> <chr> <dbl>
1 1 a 1
2 3 c 1パイプ演算子は、RStudioでは、Ctrl + Shift + Mで入力できます。
2種類のパイプ演算子
Rのパイプ演算子には、代表的なものとして、%>%と|>の2つがあります。 %>%はmagrittrパッケージで定義されているもので、|>はR組み込みの(追加パッケージが必要ない)演算子です。 実は、|>よりも%>%の方が歴史が古く、ウェブ記事などを検索すると、%>%を利用した説明の方がたくさん見つかります。 両者の使い方はほとんど同じなので、この講義では、|>を利用して説明します。
RStudioでは、デフォルトではCtrl + Shift + Mによって%>%が入力されます。 これを同じキー操作で|>を入力するように変更するには、以下の設定を変更する必要があります。
RStudioの[Tools]メニューから[Global Options…]を選択します(または、キーボードでCtrl + ,を入力します)。 Optionsウィンドウが開きますので、左側のパネルで上から2つ目の[Code]を選択します。 右側のパネルにある[Use native pipe operator, |> (Require R 4.1 +)]のチェックボックスをチェックし、右下の[OK]ボタンをクリックします。
部分集合の抽出
次に、人口密度がヘクタールあたり40人を超える地域だけを抜き出して、地図に表示してみます。 データフレームの列を条件によって抽出するには、dplyrパッケージのfilter関数を使います。
did <- district |> filter(density >= 40)
ggplot() +
geom_sf(aes(fill = density), data = did) +
scale_fill_gradient(low = "yellow", high = "red")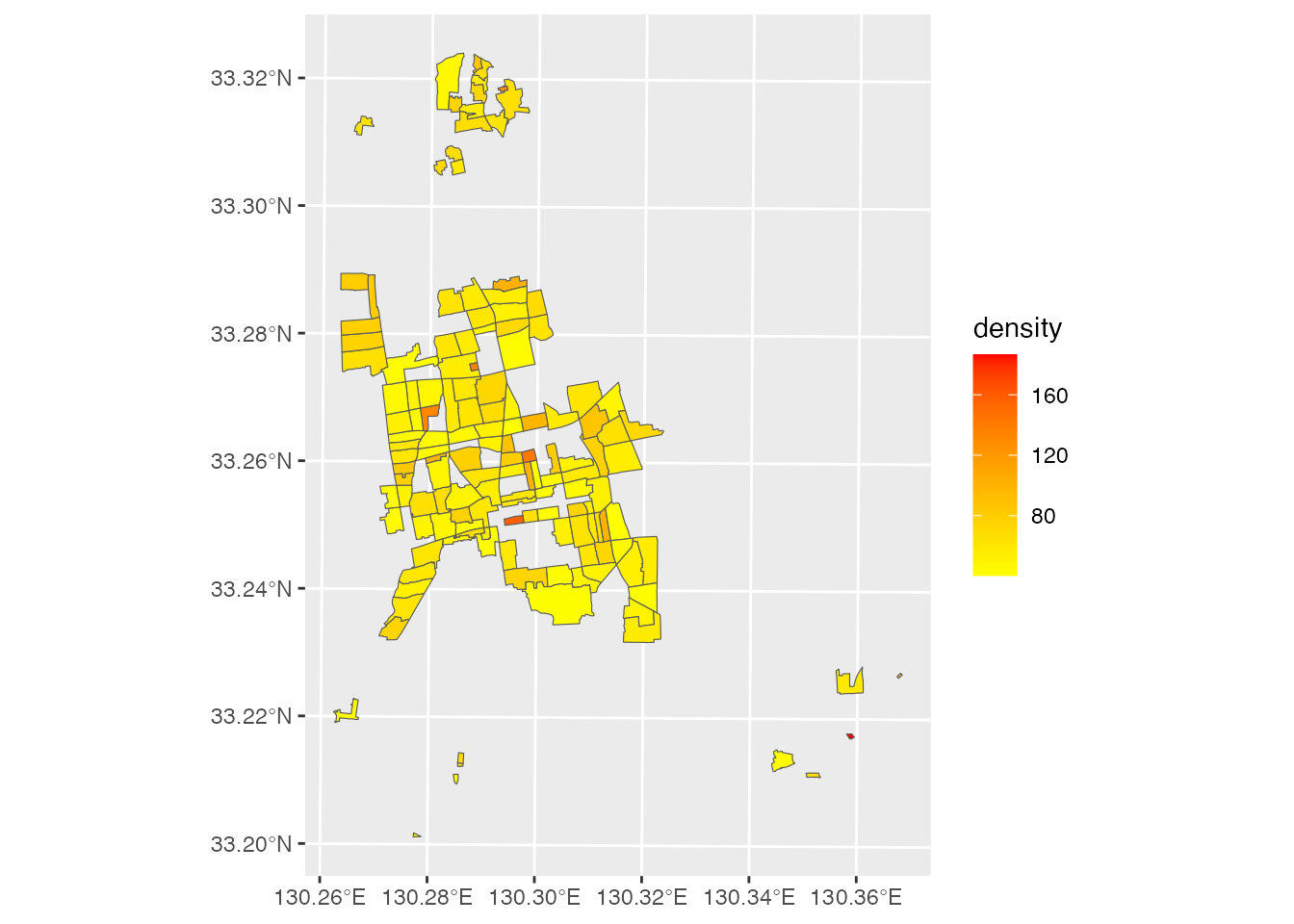
filter関数の使い方を見ると、パイプ演算子の意義がよく分かるのではないでしょうか。
属性データの結合
次の演習では、佐賀県オープンデータ「オープンデータマップ用データセット」を使って、 属性データの結合について説明します。 まず、必要なデータをダウンロードしましょう。
オープンデータマップ用データセットのダウンロード
上のリンクから、佐賀県オープンデータカタログサイトのオープンデータマップ用データセットのページを開いてください。
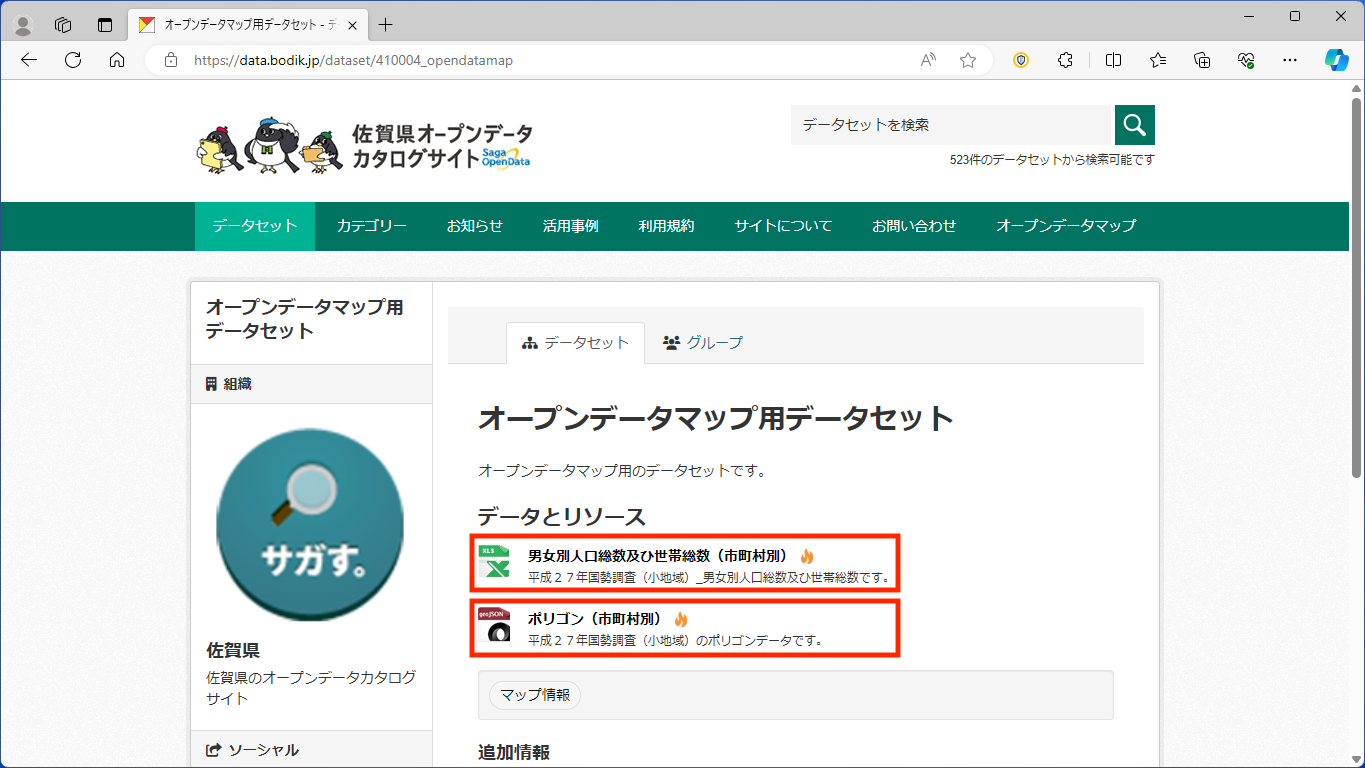
まず、[男女別人口総数及ひ世帯総数(市町村別)]をクリックし、次のページで[ダウンロード] をクリックします。
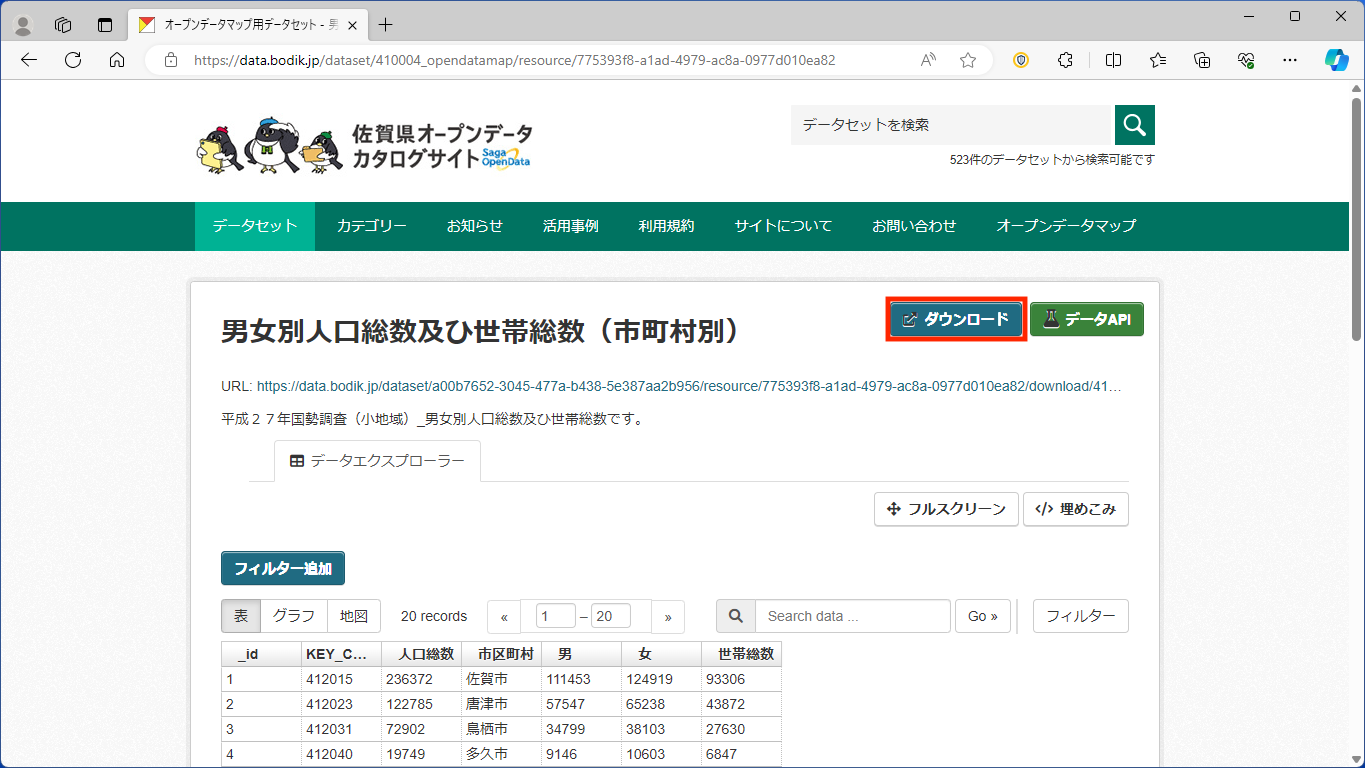
一つ前のページに戻って、今度は[ポリゴン(市町村別)]をクリックし、次のページで[ダウンロード]をクリックします(うまくいかない場合は、リンクを右クリック→[名前をつけてリンクを保存])。
ダウンロードフォルダに、とても長い名前のファイルが2つ追加されているので、それぞれ「410004saga.xlsx」と「410004saga.geojson」という名前に変更してください。 名前を修正した2つのファイルを、プロジェクト内のdataフォルダに移動しましょう。
空間データと属性データの結合
ダウンロードしたGeoJSONファイルを、sf::st_read関数で読み込みます。 変数名はsaga_mapとしておきます。
saga_map <- st_read("data/410004saga.geojson")Reading layer `410004saga' from data source
`/Users/kzktmr/Documents/LectureNotes/EconomicGeography/data/410004saga.geojson'
using driver `GeoJSON'
Simple feature collection with 20 features and 4 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 129.7368 ymin: 32.95054 xmax: 130.5424 ymax: 33.6189
Geodetic CRS: WGS 84属性データとしては、県名(KEN_NAME)、市郡名(GST_NAME)、町村名(CSS_NAME)、自治体コード(KEY_CODE)があることが分かります。
glimpse(saga_map)Rows: 20
Columns: 5
$ KEN_NAME <chr> "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県"…
$ GST_NAME <chr> "鹿島市", "唐津市", "神埼市", "杵島郡", "多久市", "東松浦郡", "三養基郡", "西松浦郡", "鳥…
$ CSS_NAME <chr> NA, NA, NA, "江北町", NA, "玄海町", "上峰町", "有田町", NA, "白石町", "吉野ヶ里町…
$ KEY_CODE <chr> "412074", "412023", "412104", "414247", "412040", "413879", "…
$ geometry <MULTIPOLYGON [°]> MULTIPOLYGON (((130.1198 33..., MULTIPOLYGON (((…次に、エクセルファイルを、read_excel関数を使って読み込みます。 その前に、library関数でreadxlパッケージをロードすることを忘れないようにしましょう。 読み込んだ内容を、変数saga_datに代入します。 変数の内容を、文字通り「チラッと見る」glimpse関数は、便利な関数です。 このファイルの中には、自治体コード(KEY_CODE)、人口総数、市区町村名、男性人口、女性人口、世帯総数のデータがあることが分かります。
saga_dat <- read_excel("data/410004saga.xlsx")
glimpse(saga_dat)Rows: 20
Columns: 6
$ KEY_CODE <chr> "412015", "412023", "412031", "412040", "412058", "412066", "…
$ 人口総数 <dbl> 236372, 122785, 72902, 19749, 55238, 49062, 29684, 44259, 273…
$ 市区町村 <chr> "佐賀市", "唐津市", "鳥栖市", "多久市", "伊万里市", "武雄市", "鹿島市", "小城市", "嬉野市…
$ ` 男` <dbl> 111453, 57547, 34799, 9146, 26395, 23178, 13920, 20823, 12667…
$ ` 女` <dbl> 124919, 65238, 38103, 10603, 28843, 25884, 15764, 23436, 1466…
$ 世帯総数 <dbl> 93306, 43872, 27630, 6847, 19698, 16932, 10124, 14769, 9214, …saga_mapとsaga_datを結合することを考えます。 両方の列にKEY_CODE(自治体コード)があるので、これをキーにして、2つのデータを結合できそうです。 このような操作には、left_join関数が使えます。 by引数で、どの列をキーにするかを指定することができます。
saga <- saga_map |> left_join(saga_dat, by = join_by(KEY_CODE))
glimpse(saga)Rows: 20
Columns: 10
$ KEN_NAME <chr> "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県"…
$ GST_NAME <chr> "鹿島市", "唐津市", "神埼市", "杵島郡", "多久市", "東松浦郡", "三養基郡", "西松浦郡", "鳥…
$ CSS_NAME <chr> NA, NA, NA, "江北町", NA, "玄海町", "上峰町", "有田町", NA, "白石町", "吉野ヶ里町…
$ KEY_CODE <chr> "412074", "412023", "412104", "414247", "412040", "413879", "…
$ 人口総数 <dbl> 29684, 122785, 31842, 9583, 19749, 5902, 9283, 20148, 72902, …
$ 市区町村 <chr> "鹿島市", "唐津市", "神埼市", "江北町", "多久市", "玄海町", "上峰町", "有田町", "鳥栖市"…
$ ` 男` <dbl> 13920, 57547, 15172, 4497, 9146, 3035, 4379, 9356, 34799, 111…
$ ` 女` <dbl> 15764, 65238, 16670, 5086, 10603, 2867, 4904, 10792, 38103, 1…
$ 世帯総数 <dbl> 10124, 43872, 10913, 3225, 6847, 1918, 3260, 6900, 27630, 725…
$ geometry <MULTIPOLYGON [°]> MULTIPOLYGON (((130.1198 33..., MULTIPOLYGON (((…
ノート
by引数に与える列を指定するには、join_by関数を使います。しかしこれは、簡略化してjoin_by関数を使わないで済ますこともできます。 その場合、下のように、列名をダブルクォーテーションで囲んだ文字列としてby引数に与えます。
saga <- saga_map |> left_join(saga_dat, by = "KEY_CODE")left_join関数を適用した新しいsaga変数を見ると、属性データとして、 2つのデータそれぞれに存在していたものが全て含まれていることが確認できます。 このようにして、すでにある空間データの属性データに、別のソースから持ってきたデータを結合することが可能です。
names(saga_map)[1] "KEN_NAME" "GST_NAME" "CSS_NAME" "KEY_CODE" "geometry"names(saga_dat)[1] "KEY_CODE" "人口総数" "市区町村" " 男" " 女" "世帯総数"names(saga) [1] "KEN_NAME" "GST_NAME" "CSS_NAME" "KEY_CODE" "人口総数" "市区町村"
[7] " 男" " 女" "世帯総数" "geometry"結合した属性データを使って、佐賀県市町の平均世帯人員(世帯あたりの平均人数)による塗り分け地図を作ってみましょう。
saga <- saga |>
mutate(family_size = round(`人口総数` / `世帯総数`, 2)) |>
st_transform(6670)
ggplot() +
geom_sf(aes(fill = family_size), data = saga) +
scale_fill_gradient(low = "lightblue", "high" = "darkblue")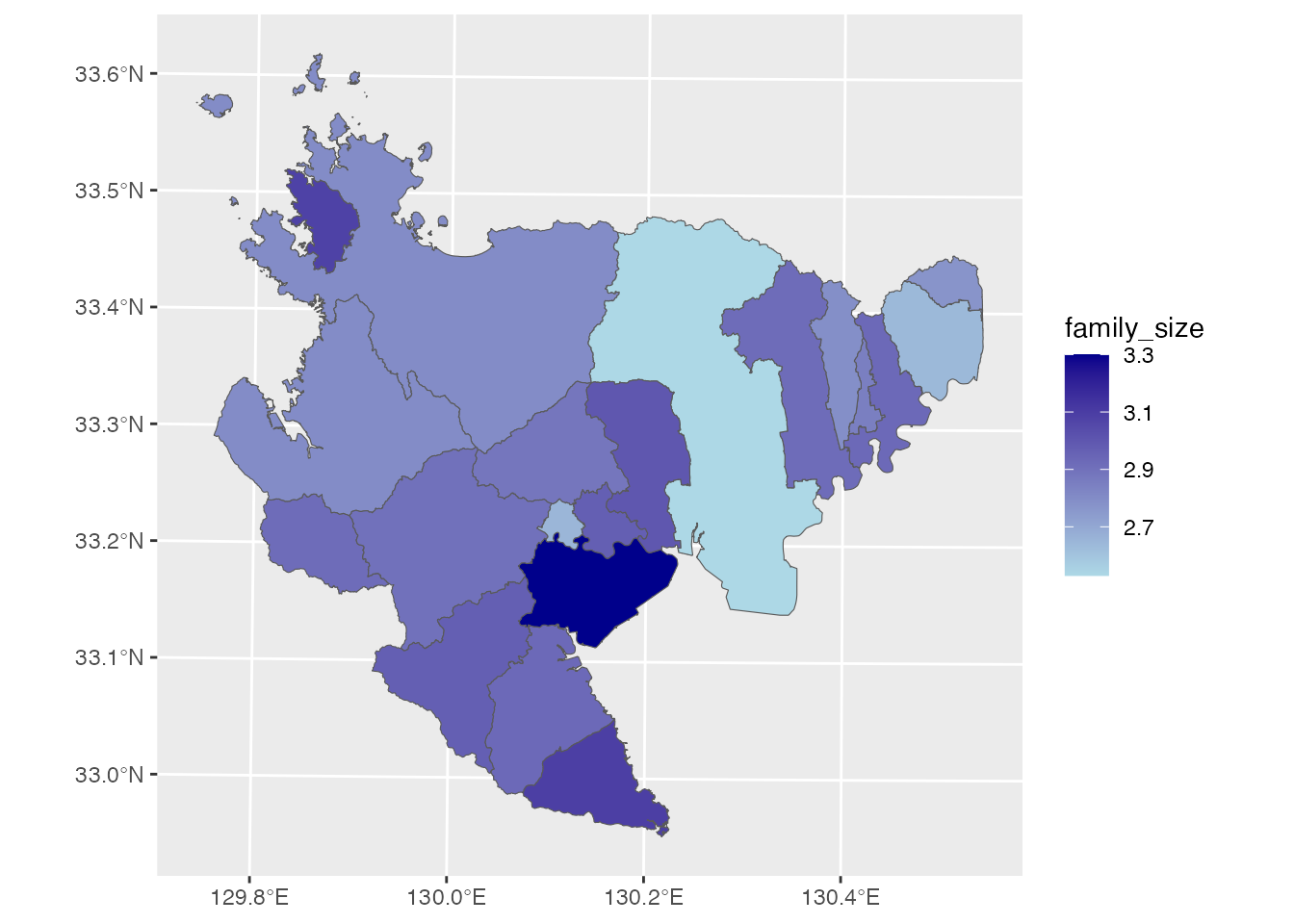
佐賀市や鳥栖市の平均世帯規模が小さいことが分かりますね。
属性データの集計
佐賀県の20市町は、下の図のように、5つのエリアに分類されるそうです。 そこで、先ほど読み込んだ人口や世帯数のデータを、エリアごとに集計してみましょう。
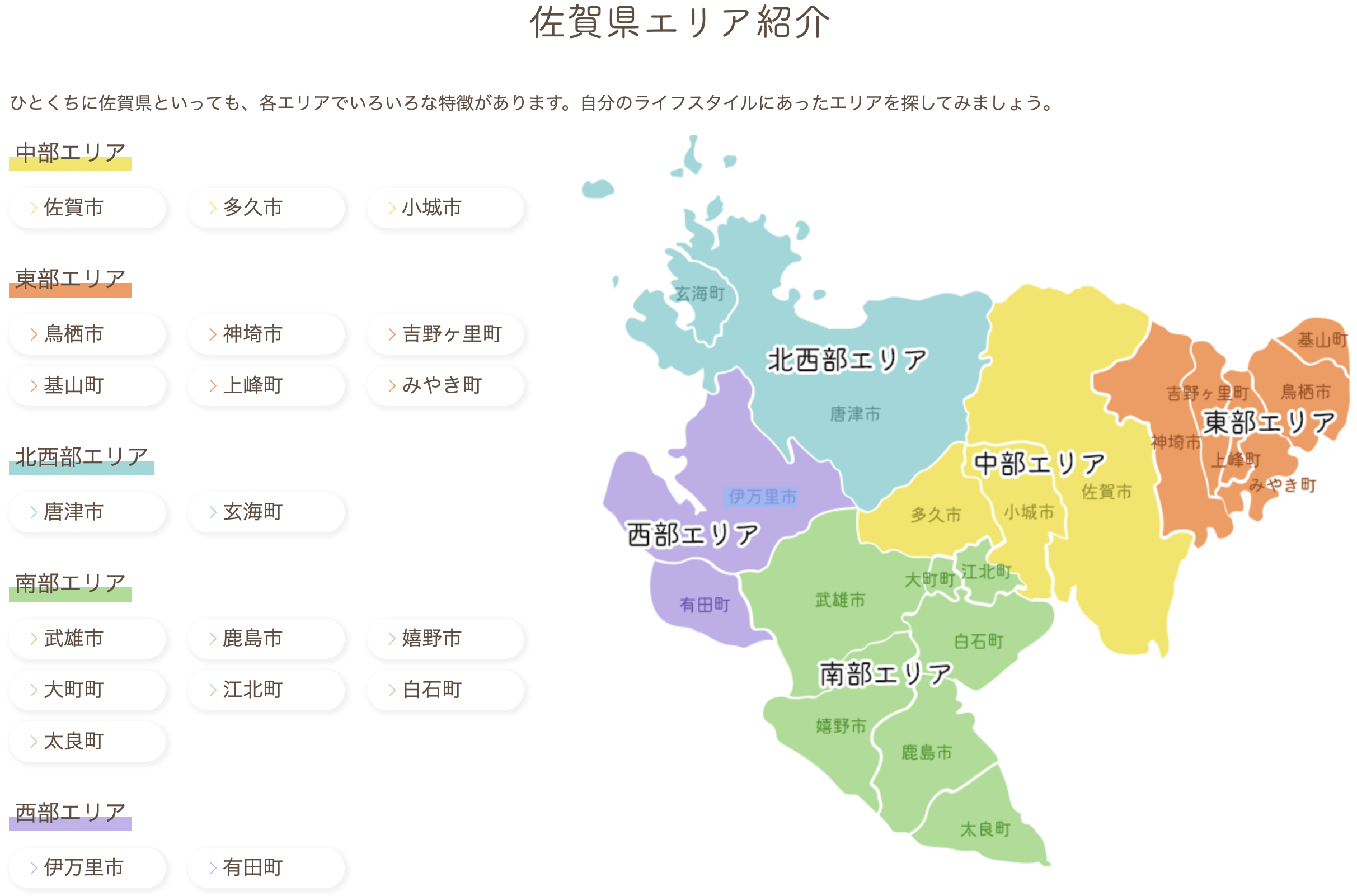
(出所)「サガスマイル」ウェブサイト
エリアごとにデータを集計するために、region.xlsxというファイルを作りましたので、以下のリンクからダウンロードして、dataフォルダに移動してください。
dataフォルダに移動できたら、read_excel関数で読み込んでください。 変数regionに代入し、その中身を確認してください。
region <- read_excel("data/region.xlsx")
glimpse(region)Rows: 20
Columns: 3
$ KEY_CODE <chr> "412015", "412023", "412031", "412040", "412058", "412066", "…
$ 市区町村 <chr> "佐賀市", "唐津市", "鳥栖市", "多久市", "伊万里市", "武雄市", "鹿島市", "小城市", "嬉野市…
$ 地区 <chr> "中部", "北西部", "東部", "中部", "西部", "南部", "南部", "中部", "南部", "東部", …regionには、自治体コード(KEY_CODE)、市区町村名、地区名のデータ列があることが分かります。 属性データを集計するために、このregionを、sagaと結合します。 結合には、left_join関数を使います。
saga <- saga |>
left_join(region, by = join_by(KEY_CODE, `市区町村`))
glimpse(saga)Rows: 20
Columns: 12
$ KEN_NAME <chr> "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐…
$ GST_NAME <chr> "鹿島市", "唐津市", "神埼市", "杵島郡", "多久市", "東松浦郡", "三養基郡", "西松浦郡",…
$ CSS_NAME <chr> NA, NA, NA, "江北町", NA, "玄海町", "上峰町", "有田町", NA, "白石町", "吉野…
$ KEY_CODE <chr> "412074", "412023", "412104", "414247", "412040", "413879"…
$ 人口総数 <dbl> 29684, 122785, 31842, 9583, 19749, 5902, 9283, 20148, 7290…
$ 市区町村 <chr> "鹿島市", "唐津市", "神埼市", "江北町", "多久市", "玄海町", "上峰町", "有田町", "鳥…
$ ` 男` <dbl> 13920, 57547, 15172, 4497, 9146, 3035, 4379, 9356, 34799, …
$ ` 女` <dbl> 15764, 65238, 16670, 5086, 10603, 2867, 4904, 10792, 38103…
$ 世帯総数 <dbl> 10124, 43872, 10913, 3225, 6847, 1918, 3260, 6900, 27630, …
$ family_size <dbl> 2.93, 2.80, 2.92, 2.97, 2.88, 3.08, 2.85, 2.92, 2.64, 3.30…
$ 地区 <chr> "南部", "北西部", "東部", "南部", "中部", "北西部", "東部", "西部", "東部", "南…
$ geometry <MULTIPOLYGON [m]> MULTIPOLYGON (((-82226.11 3..., MULTIPOLYGON …このように、by引数には、複数の列を指定することもできます。
さて、データの集計には、group_by関数とsummarise関数を使います。 まず、group_by関数を使って、データを地区ごとのグループに分けます。
saga |> group_by(`地区`)Simple feature collection with 20 features and 11 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -117268.6 ymin: -5213.545 xmax: -42584.04 ymax: 69215.3
Projected CRS: JGD2011 / Japan Plane Rectangular CS II
# A tibble: 20 × 12
# Groups: 地区 [5]
KEN_NAME GST_NAME CSS_NAME KEY_CODE 人口総数 市区町村 ` 男` ` 女` 世帯総数
<chr> <chr> <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl>
1 佐賀県 鹿島市 <NA> 412074 29684 鹿島市 13920 15764 10124
2 佐賀県 唐津市 <NA> 412023 122785 唐津市 57547 65238 43872
3 佐賀県 神埼市 <NA> 412104 31842 神埼市 15172 16670 10913
4 佐賀県 杵島郡 江北町 414247 9583 江北町 4497 5086 3225
5 佐賀県 多久市 <NA> 412040 19749 多久市 9146 10603 6847
6 佐賀県 東松浦郡 玄海町 413879 5902 玄海町 3035 2867 1918
7 佐賀県 三養基郡 上峰町 413453 9283 上峰町 4379 4904 3260
8 佐賀県 西松浦郡 有田町 414018 20148 有田町 9356 10792 6900
9 佐賀県 鳥栖市 <NA> 412031 72902 鳥栖市 34799 38103 27630
10 佐賀県 杵島郡 白石町 414255 23941 白石町 11133 12808 7253
11 佐賀県 神埼郡 吉野ヶ里町…… 413275 16411 吉野ヶ里町…… 8136 8275 5891
12 佐賀県 佐賀市 <NA> 412015 236372 佐賀市 111453 124919 93306
13 佐賀県 伊万里市 <NA> 412058 55238 伊万里市 26395 28843 19698
14 佐賀県 三養基郡 みやき町 413461 25278 みやき町 11969 13309 8638
15 佐賀県 武雄市 <NA> 412066 49062 武雄市 23178 25884 16932
16 佐賀県 杵島郡 大町町 414239 6777 大町町 3077 3700 2560
17 佐賀県 嬉野市 <NA> 412091 27336 嬉野市 12667 14669 9214
18 佐賀県 藤津郡 太良町 414417 8779 太良町 4125 4654 2838
19 佐賀県 小城市 <NA> 412082 44259 小城市 20823 23436 14769
20 佐賀県 三養基郡 基山町 413411 17501 基山町 8266 9235 6321
# ℹ 3 more variables: family_size <dbl>, 地区 <chr>,
# geometry <MULTIPOLYGON [m]>「地区」列によって、データが5つのグループに分けられたことが分かります。 このグループごとに様々な集計を行うのが、summarise関数です。 ここでは、sum関数を使って、グループごとの人口と世帯数の合計を計算してみます。
saga |> group_by(`地区`) |>
summarise(`人口総数` = sum(`人口総数`), `世帯総数` = sum(`世帯総数`))Simple feature collection with 5 features and 3 fields
Geometry type: GEOMETRY
Dimension: XY
Bounding box: xmin: -117268.6 ymin: -5213.545 xmax: -42584.04 ymax: 69215.3
Projected CRS: JGD2011 / Japan Plane Rectangular CS II
# A tibble: 5 × 4
地区 人口総数 世帯総数 geometry
<chr> <dbl> <dbl> <GEOMETRY [m]>
1 中部 300380 114922 POLYGON ((-71579.63 22245.38, -71590.73 22306.78, -7…
2 北西部 128687 45790 MULTIPOLYGON (((-110233.4 47945.4, -110231.4 47948.2…
3 南部 155162 52146 MULTIPOLYGON (((-73056.94 -4798.644, -73059.04 -4804…
4 東部 173217 62653 POLYGON ((-51225.53 30200.83, -51194.74 30123.23, -5…
5 西部 75386 26598 POLYGON ((-101765.4 18280.42, -101778.5 18274.34, -1…属性データが、地区名、人口総数、世帯総数だけになりました。 これは、グルーピングに利用した変数列と、summarise関数で計算した結果だけが残ったことを意味しています。 このように、summarise関数は、グループごとの変数群を行に持つような、新しいデータフレームを返します。 また、geometry列(ポリゴンデータ)も同時に集計されて、5つの地区を表すポリゴンが作られています。
summarise関数での集計に便利な関数
今回の例では、グルーピングによる集計をするために、合計を計算するsum関数を使用しました。 その他にも、グループごとの平均値を計算するmean関数や中央値を計算するmedian関数、 最小値を計算するmin関数や最大値を計算するmax関数、グループに含まれる要素の数を数えるn関数などが使えます。
このことを、地図で確認してみましょう。 集計した地区ごとの人口総数と世帯総数から、地区の平均世帯人員を計算し、図化します。
saga_region <- saga |> group_by(`地区`) |>
summarise(`人口総数` = sum(`人口総数`), `世帯総数` = sum(`世帯総数`)) |>
mutate(family_size = round(`人口総数` / `世帯総数`, 2))
ggplot() +
geom_sf(aes(fill = family_size), data = saga_region) +
scale_fill_gradient(low = "lightblue", high = "darkblue")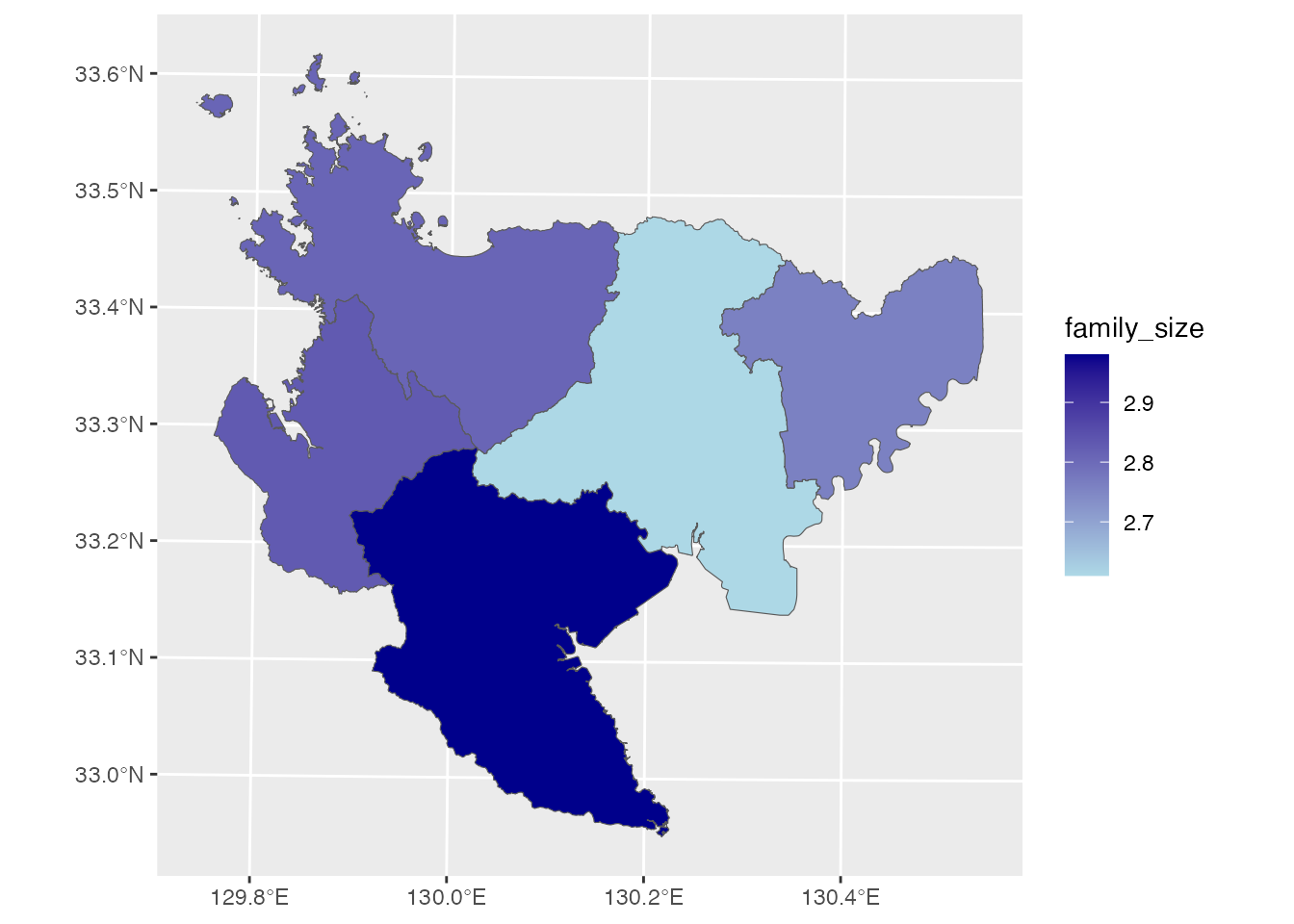
20市町のポリゴンが集計(合併)されて、5地区のポリゴンになっています。
空間データの操作
次に、空間データの簡単な操作について説明します。 ポリゴンデータの面積や重心の計算、ポイントデータ間の距離の計算をする簡単なものです。
面積計算
小地域統計の例では、属性データに面積のデータが入っていました。 しかし、使用するデータによっては、面積データが入っていないこともあり、 そのような場合には、自分でポリゴンの面積を計算する必要があります。 計算といっても、手作業で計算するわけではなく、st_area関数を使えば、簡単にポリゴンの面積が計算できます。
saga |> mutate(area = st_area(saga)) |>
select(KEY_CODE, GST_NAME, area) |> arrange(KEY_CODE)Simple feature collection with 20 features and 3 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -117268.6 ymin: -5213.545 xmax: -42584.04 ymax: 69215.3
Projected CRS: JGD2011 / Japan Plane Rectangular CS II
First 10 features:
KEY_CODE GST_NAME area geometry
1 412015 佐賀市 432891823 [m^2] MULTIPOLYGON (((-70264.64 2...
2 412023 唐津市 487160675 [m^2] MULTIPOLYGON (((-106350 451...
3 412031 鳥栖市 71386980 [m^2] MULTIPOLYGON (((-47890.53 3...
4 412040 多久市 96670142 [m^2] MULTIPOLYGON (((-76464.8 27...
5 412058 伊万里市 253940933 [m^2] MULTIPOLYGON (((-92759.15 3...
6 412066 武雄市 195555078 [m^2] MULTIPOLYGON (((-95531.54 1...
7 412074 鹿島市 111113089 [m^2] MULTIPOLYGON (((-82226.11 3...
8 412082 小城市 95164949 [m^2] MULTIPOLYGON (((-70897.76 2...
9 412091 嬉野市 126591461 [m^2] MULTIPOLYGON (((-89237.11 5...
10 412104 神埼市 124006165 [m^2] MULTIPOLYGON (((-60455.97 2...ここでは、mutate関数を使って、データフレームに新しい変数列areaを追加しています。 また、面積を計算すると、なぜか行の順番が入れ替わってしまうので、 arrange関数を使って、自治体コード順に並べ替えています。
この結果によると、佐賀市の面積が432.89㎢になりました。 しかし、佐賀市ウェブサイトを見ると、佐賀市の面積は431.82㎢となっています。近い値ではありますが、少し違いますね。 なぜこのような違いがあるのでしょうか? おそらく、国土地理院が面積計算に使っている地図と、今回利用した佐賀県オープンデータのGeoJSONとでは、そもそも地図の精度が大きく異なることが、最も大きな要因だと思います。
重心計算
ポリゴンの代表地点を求める方法はいくつかありますが、その1つがポリゴンの重心を求める方法です。 ポリゴンの重心は、幾何学的に計算することができます。 Rではsfパッケージのst_centroid関数を使うと簡単です。
saga_center <- saga |> st_centroid()Warning: st_centroid assumes attributes are constant over geometriesglimpse(saga_center)Rows: 20
Columns: 12
$ KEN_NAME <chr> "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐賀県", "佐…
$ GST_NAME <chr> "鹿島市", "唐津市", "神埼市", "杵島郡", "多久市", "東松浦郡", "三養基郡", "西松浦郡",…
$ CSS_NAME <chr> NA, NA, NA, "江北町", NA, "玄海町", "上峰町", "有田町", NA, "白石町", "吉野…
$ KEY_CODE <chr> "412074", "412023", "412104", "414247", "412040", "413879"…
$ 人口総数 <dbl> 29684, 122785, 31842, 9583, 19749, 5902, 9283, 20148, 7290…
$ 市区町村 <chr> "鹿島市", "唐津市", "神埼市", "江北町", "多久市", "玄海町", "上峰町", "有田町", "鳥…
$ ` 男` <dbl> 13920, 57547, 15172, 4497, 9146, 3035, 4379, 9356, 34799, …
$ ` 女` <dbl> 15764, 65238, 16670, 5086, 10603, 2867, 4904, 10792, 38103…
$ 世帯総数 <dbl> 10124, 43872, 10913, 3225, 6847, 1918, 3260, 6900, 27630, …
$ family_size <dbl> 2.93, 2.80, 2.92, 2.97, 2.88, 3.08, 2.85, 2.92, 2.64, 3.30…
$ 地区 <chr> "南部", "北西部", "東部", "南部", "中部", "北西部", "東部", "西部", "東部", "南…
$ geometry <POINT [m]> POINT (-84634.39 6884.832), POINT (-93157.71 46699.1…mapview(saga_center)ggplot() +
geom_sf(data = saga) +
geom_sf(data = saga_center)
距離計算
佐賀大学経済学部から、佐賀県20市町それぞれまでの距離を計算してみましょう。
その準備として、佐賀大学経済学部のポイントデータを作成します。1つの地点だけからなる 佐賀大学経済学部の緯度経度は、Googleマップから、 東経130.29217001169215度、北緯33.243532718809874度です。 これを使って、saga_univというポイントデータを作ります。 ここでは、緯度経度を2次元ベクトルとし、st_point、st_sfc、st_sfという関数を使っています。 同時にnameという属性(データ列)を追加し、CRSをWGS84(EPSGコード:4326)に設定しています。
saga_univ_coord <- c(130.29217001169215, 33.243532718809874)
saga_univ <- saga_univ_coord |> st_point() |> st_sfc() |>
st_sf(name = "佐賀大学経済学部", crs = 4326) |>
st_transform(6670)距離を計算するのは、sfパッケージのst_distance関数です。
dist <- st_distance(saga_center, saga_univ)
distUnits: [m]
[,1]
[1,] 27615.816
[2,] 33447.268
[3,] 12783.880
[4,] 12853.281
[5,] 17777.046
[6,] 47232.163
[7,] 15426.682
[8,] 40131.988
[9,] 23880.336
[10,] 16192.827
[11,] 16488.153
[12,] 9359.271
[13,] 38214.728
[14,] 16882.230
[15,] 27844.611
[16,] 16762.700
[17,] 30647.113
[18,] 30537.110
[19,] 9764.280
[20,] 28605.821このように、距離が計算されました。 単位はmですね。 しかし、後々の計算を楽にするために、単位を落として単なる数値にしておきます。
dist <- dist |> units::drop_units()さて、距離を市町重心データの属性データに追加し、距離の近い順に並び替えると、このようになります。
saga_center <- saga_center |> mutate(distance = dist)
saga_center |> arrange(distance)Simple feature collection with 20 features and 12 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: -105833.3 ymin: -246.665 xmax: -45625.43 ymax: 53455.65
Projected CRS: JGD2011 / Japan Plane Rectangular CS II
First 10 features:
KEN_NAME GST_NAME CSS_NAME KEY_CODE 人口総数 市区町村 男 女
1 佐賀県 佐賀市 <NA> 412015 236372 佐賀市 111453 124919
2 佐賀県 小城市 <NA> 412082 44259 小城市 20823 23436
3 佐賀県 神埼市 <NA> 412104 31842 神埼市 15172 16670
4 佐賀県 杵島郡 江北町 414247 9583 江北町 4497 5086
5 佐賀県 三養基郡 上峰町 413453 9283 上峰町 4379 4904
6 佐賀県 杵島郡 白石町 414255 23941 白石町 11133 12808
7 佐賀県 神埼郡 吉野ヶ里町 413275 16411 吉野ヶ里町 8136 8275
8 佐賀県 杵島郡 大町町 414239 6777 大町町 3077 3700
9 佐賀県 三養基郡 みやき町 413461 25278 みやき町 11969 13309
10 佐賀県 多久市 <NA> 412040 19749 多久市 9146 10603
世帯総数 family_size 地区 distance geometry
1 93306 2.53 中部 9359.271 POINT (-68409.17 36263.39)
2 14769 3.00 中部 9764.280 POINT (-74852.02 31265.68)
3 10913 2.92 東部 12783.880 POINT (-60356.99 38720.29)
4 3225 2.97 南部 12853.281 POINT (-78542.49 24602.03)
5 3260 2.85 東部 15426.682 POINT (-53802.75 36725.63)
6 7253 3.30 南部 16192.827 POINT (-79661.14 18598.34)
7 5891 2.79 東部 16488.153 POINT (-56164.94 40492.84)
8 2560 2.65 南部 16762.700 POINT (-82494.95 24471.79)
9 8638 2.93 東部 16882.230 POINT (-51811.93 36439.87)
10 6847 2.88 中部 17777.046 POINT (-83334.07 30997.11)佐賀大学経済学部からの距離で色分けした20市町の重心位置を地図にしてみます。
ggplot() +
geom_sf(data = saga) +
geom_sf(aes(color = distance), data = saga_center) +
geom_sf(color = "red", data = saga_univ) +
scale_color_gradient(low = "orange", "high" = "yellow")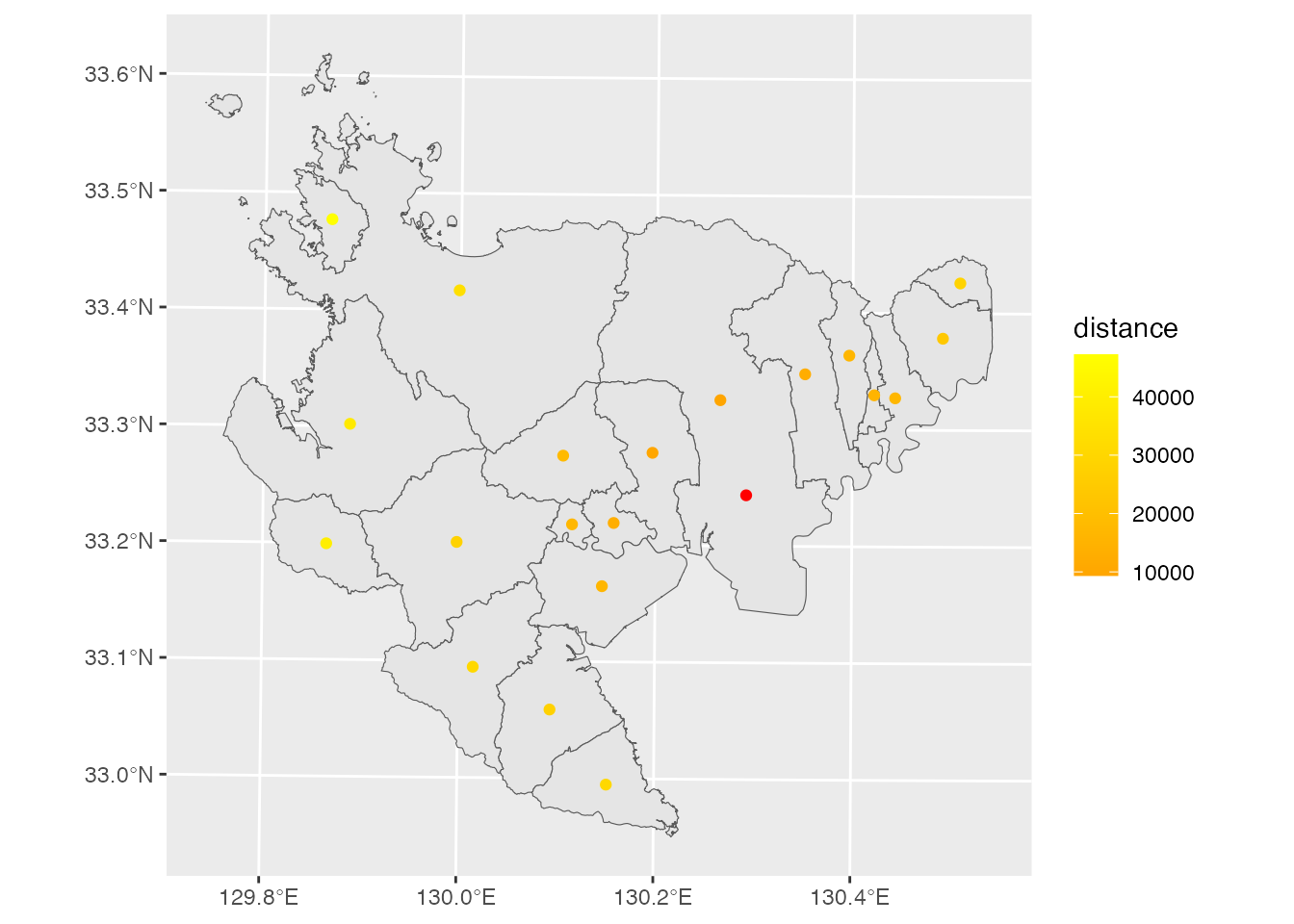
大学からの距離が近い自治体の色が濃くなっているのが分かります (佐賀市のポリゴン重心は佐賀市中心部よりも北に寄っていることも分かりますね)。