library(tidyverse)
library(readxl)
library(sf)
library(jpgrid)10: 距離分布・ボロノイ図
はじめに
今回も、これまでの講義内容の復習を兼ねて、Rを使った立地分析の演習を行います。 今日の演習では、いろいろな空間データをつかって、福岡県柳川市の小学校の統廃合について考えてみることにします。
今日の演習では以下の4つのパッケージを使用します。
小学校の再編
日本は人口減少社会に突入し、さまざまな公共施設・公共サービスの見直しが行われています。 義務教育のための施設である小中学校についても、その例外ではありません。 福岡県柳川市でも、小中学校の統廃合を進めています。
柳川市立小中学校再編計画によると、現在19校ある小学校と6校ある中学校を、統廃合によって5校の小学校と2校の中学校、そして2校の義務教育学校(小中一貫校)に再編する計画になっています。 また、新しい学校の通学区域(校区)は、現行の校区を分割せず、現在の学校の校区単位の組み合わせによって再編することとしています。
今回の演習では、柳川市の小学校の統廃合について、特に学校までの距離に着目して分析してみます。
小学校区の可視化
現在および計画されている将来の小学校区を地図に表示してみましょう。 まずはデータを国土数値情報からダウンロードします。 福岡県の小学校区データ(ポリゴン)と学校データ(ポイント)をそれぞれダウンロードしてください。
ダウンロードしたファイルを展開し、できたフォルダを今日のプロジェクトのdataフォルダに移動してください。
まず、sf::st_read関数を使って小学校区データを読み込みましょう。
district <- st_read('data/A27-21_40_GML/A27-21_40.geojson') |>
st_transform(6670)Reading layer `A27_21_40' from data source
`/Users/kzktmr/Documents/LectureNotes/data/A27-21_40_GML/A27-21_40.geojson'
using driver `GeoJSON'
Simple feature collection with 372 features and 5 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 130.3394 ymin: 32.99997 xmax: 131.1906 ymax: 33.91904
Geodetic CRS: JGD2011次いで、学校データも読み込みます。 学校データは、幼稚園から大学まで、学校教育法で規定される全ての学校のデータが含まれていますので、その中から小学校のデータだけをフィルタリングで抽出します。 ここでは、dplyr::filter関数を使って、学校分類コード(P29_003)が小学校(16001)であるデータを抜き出しています。
school <- st_read("data/P29-21_40_GML/P29-21_40.geojson") |>
filter(P29_003 == 16001) |> st_transform(6670)Reading layer `40' from data source
`/Users/kzktmr/Documents/LectureNotes/data/P29-21_40_GML/P29-21_40.geojson'
using driver `GeoJSON'
Simple feature collection with 2019 features and 7 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: 130.0358 ymin: 33.0043 xmax: 131.1884 ymax: 33.99281
Geodetic CRS: JGD2011福岡県の小学校区と小学校を地図に重ねて表示してみましょう。
ggplot() +
geom_sf(data = district) +
geom_sf(data = school) +
theme_minimal()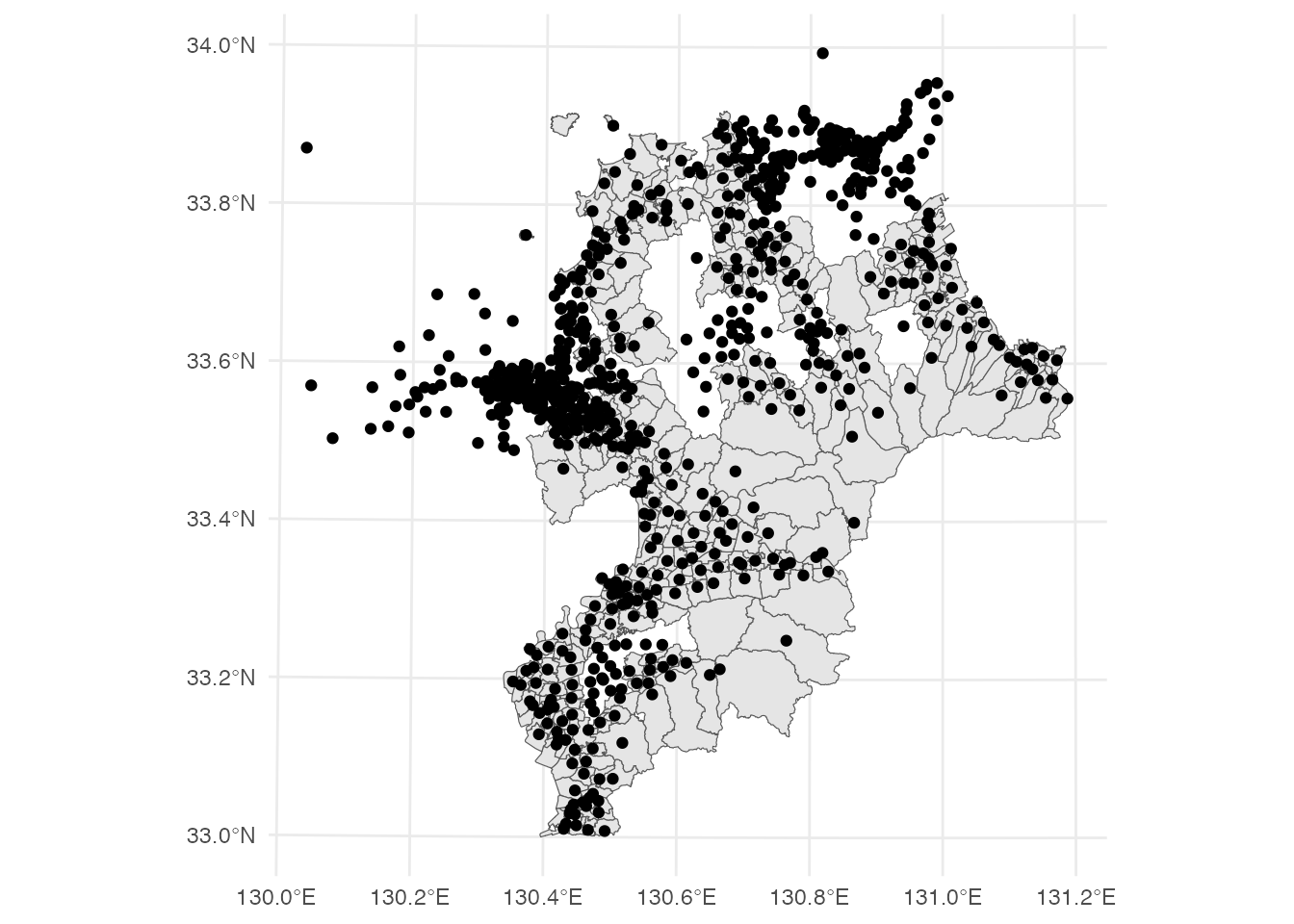
小学校区データについての注意点
図を見ると、福岡市や北九州市をはじめとして、校区データが掲載されていない地域も少なくないことがわかります。 また、小学校区データの説明には、「本データは十分な精度や正確性をもったものではなく、利用にあたっては公式な資料としては扱えない」との記載があるとおり、利用目的によってはこのデータは使えませんので、注意してください(今回の演習での分析内容では、問題なく使えます)。
それぞれのデータについて、filter関数を使って、柳川市(自治体コード:40207)のデータだけを抽出しましょう。
district <- district |> filter(A27_001 == "40207")
glimpse(district)Rows: 19
Columns: 6
$ A27_001 <chr> "40207", "40207", "40207", "40207", "40207", "40207", "40207"…
$ A27_002 <chr> "柳川市立", "柳川市立", "柳川市立", "柳川市立", "柳川市立", "…
$ A27_003 <chr> "B140220700086", "B140220700095", "B140220700068", "B14022070…
$ A27_004 <chr> "蒲池小学校", "皿垣小学校", "昭代第一小学校", "昭代第二小学校…
$ A27_005 <chr> "柳川市金納455", "柳川市大和町栄1542", "柳川市田脇810", "柳川…
$ geometry <MULTIPOLYGON [m]> MULTIPOLYGON (((-53292.8 21..., MULTIPOLYGON (((…school <- school |> filter(P29_001 == "40207")
glimpse(school)Rows: 19
Columns: 8
$ P29_001 <chr> "40207", "40207", "40207", "40207", "40207", "40207", "40207"…
$ P29_002 <chr> "B140220700013", "B140220700022", "B140220700031", "B14022070…
$ P29_003 <int> 16001, 16001, 16001, 16001, 16001, 16001, 16001, 16001, 16001…
$ P29_004 <chr> "柳河小学校", "城内小学校", "矢留小学校", "東宮永小学校", "両…
$ P29_005 <chr> "柳川市恵美須町28", "柳川市本町84", "柳川市矢留本町21", "柳川…
$ P29_006 <int> 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3
$ P29_007 <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1
$ geometry <POINT [m]> POINT (-55116.81 18868.91), POINT (-55409.05 18042.02), POINT…柳川市の小学校と小学校区を地図に重ねて表示します。
ggplot() +
geom_sf(data = district) +
geom_sf(data = school) +
theme_minimal()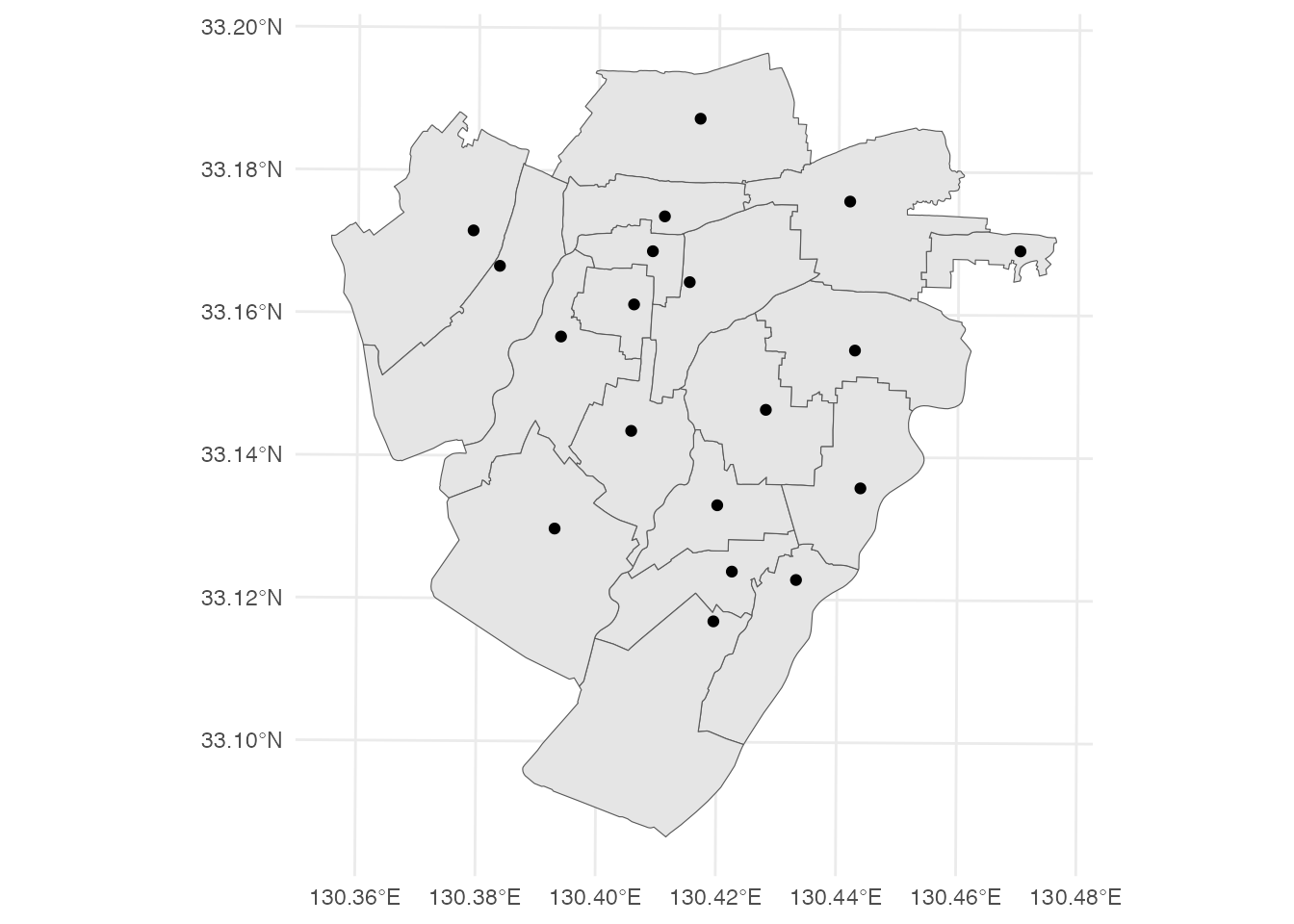
人口分布
人口分布は、5次メッシュ(250mメッシュ)を使ってみましょう。 前回と同様に、jpgirdパッケージを使ってメッシュポリゴンを準備します。
柳川市にかかるメッシュポリゴンを作成するために、柳川市域のポリゴンデータが必要です。 今回は、小学校区のポリゴンデータがあるので、これをsf::st_union関数で統合することで、 柳川市のポリゴンを作りましょう。
yngw_city <- st_union(district)
ggplot() + geom_sf(data = yngw_city) +
theme_minimal()
前回の演習と同様に、 jpgrid::geometry_to_grid関数とjpgrid::grid_as_sf関数を組み合わせて、 柳川市の250 mメッシュポリゴンを作成します。
yngw_grid <-
yngw_city |> st_transform(6668) |>
geometry_to_grid(grid_size = "250m") |> first() |>
grid_as_sf(crs = 6668) |> st_transform(6670) |>
mutate(meshcode = as.character(grid))メッシュポリゴンを地図に表示すると、次のようになります。
ggplot() + geom_sf(data = yngw_grid) +
theme_minimal()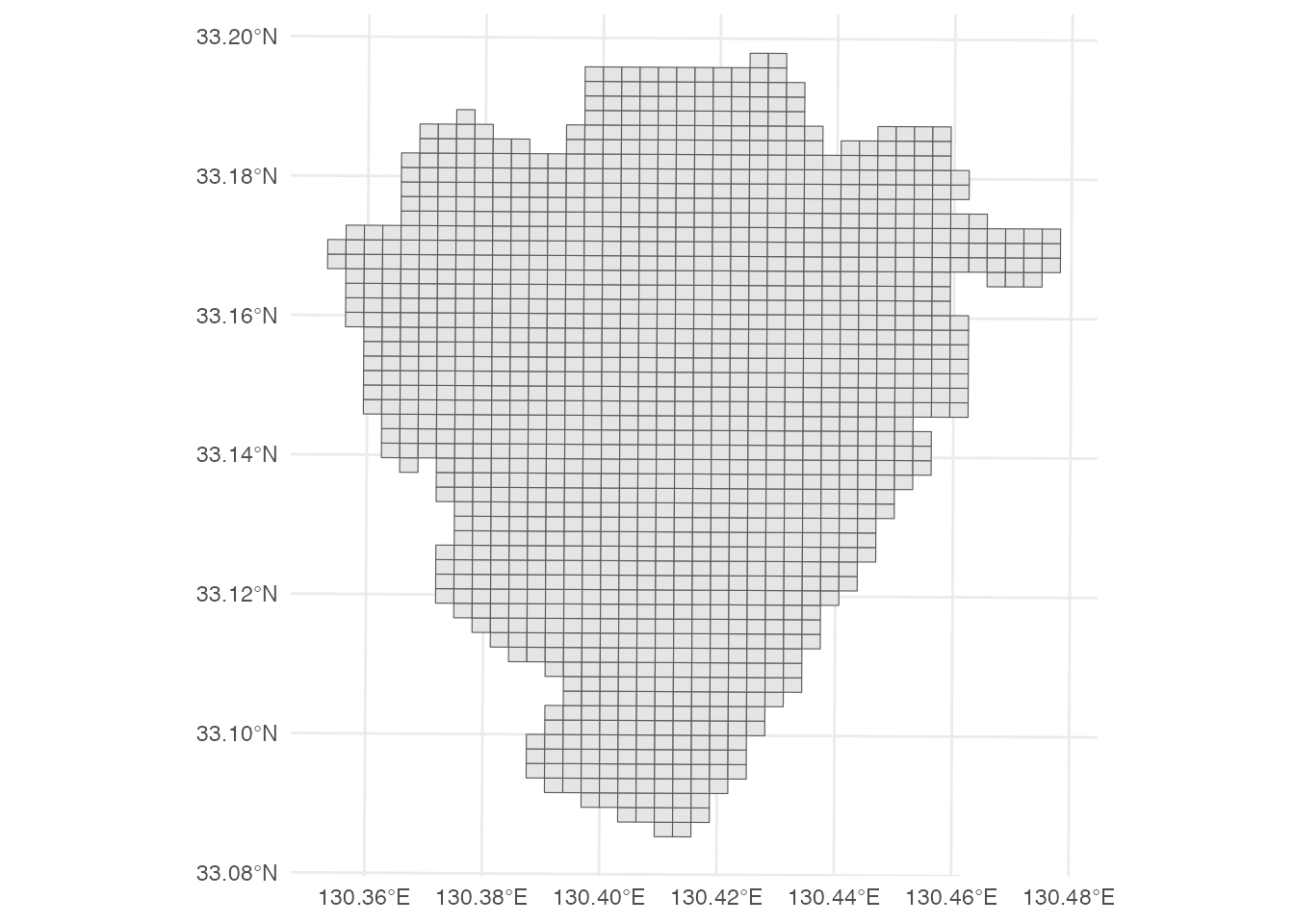
次に統計データをダウンロードするわけですが、柳川市は1次メッシュコード4930の範囲に収まっていることを確認しておきましょう。
yngw_grid |> pull(meshcode) |> str_starts('4930') |> all()[1] TRUE人口データはe-Statからダウンロードしてください。
- >統計データダウンロード
- [国勢調査]→[2020年]→[5次メッシュ(250mメッシュ)]→[人口移動、就業状態等及び従業地・通学地(JGD2011)]→[都道府県で絞込み(福岡県)]→[M 4930]
tblT001145Q4930.zipがダウンロードされると思いますので、すべて展開してください。 展開してできたフォルダの中にあるtblT001145Q4930.txtをプロジェクトのdataフォルダに移動してください。
readr::read_csv関数を使ってtblT001145Q4930.txtを読み込みます。 例によって、2回に分けて読み込むことにします。
ここでは、空白および秘匿データ(*)を欠損値として処理しています。 また、KEY_CODEをmeshcodeとして、T001145037(在学者 うち 小学校・中学校 総数)をstudentとしてそれぞれ取り出し、 さらに、meshcodeを数値型から文字列型に変更しておきます。
col_names <-
read_csv('data/tblT001145Q4930.txt', n_max = 1,
col_names = FALSE, col_types = 'c',
locale = locale(encoding = 'cp932')) |>
as.character()
population <-
read_csv('data/tblT001145Q4930.txt', skip = 2,
col_names = col_names, na = c("", "*")) |>
select(meshcode = KEY_CODE, student = T001145037) |>
mutate(meshcode = as.character(meshcode))Rows: 32215 Columns: 98
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): GASSAN
dbl (97): KEY_CODE, HTKSYORI, HTKSAKI, T001145001, T001145002, T001145003, T...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.glimpse(population)Rows: 32,215
Columns: 2
$ meshcode <chr> "4930010022", "4930010023", "4930010024", "4930010034", "4930…
$ student <dbl> NA, 4, 5, NA, 2, 5, NA, 0, 0, NA, NA, 11, 3, 0, 7, NA, 6, 1, …読み込んだ人口データを、メッシュポリゴンに結合します。
yngw_grid <- yngw_grid |>
left_join(population, by = join_by(meshcode)) 小中学校の在学者数で色を塗ったメッシュ地図を描いてみましょう。
ggplot() +
geom_sf(aes(fill = student), data = yngw_grid) +
scale_fill_distiller(direction = 1) +
theme_minimal()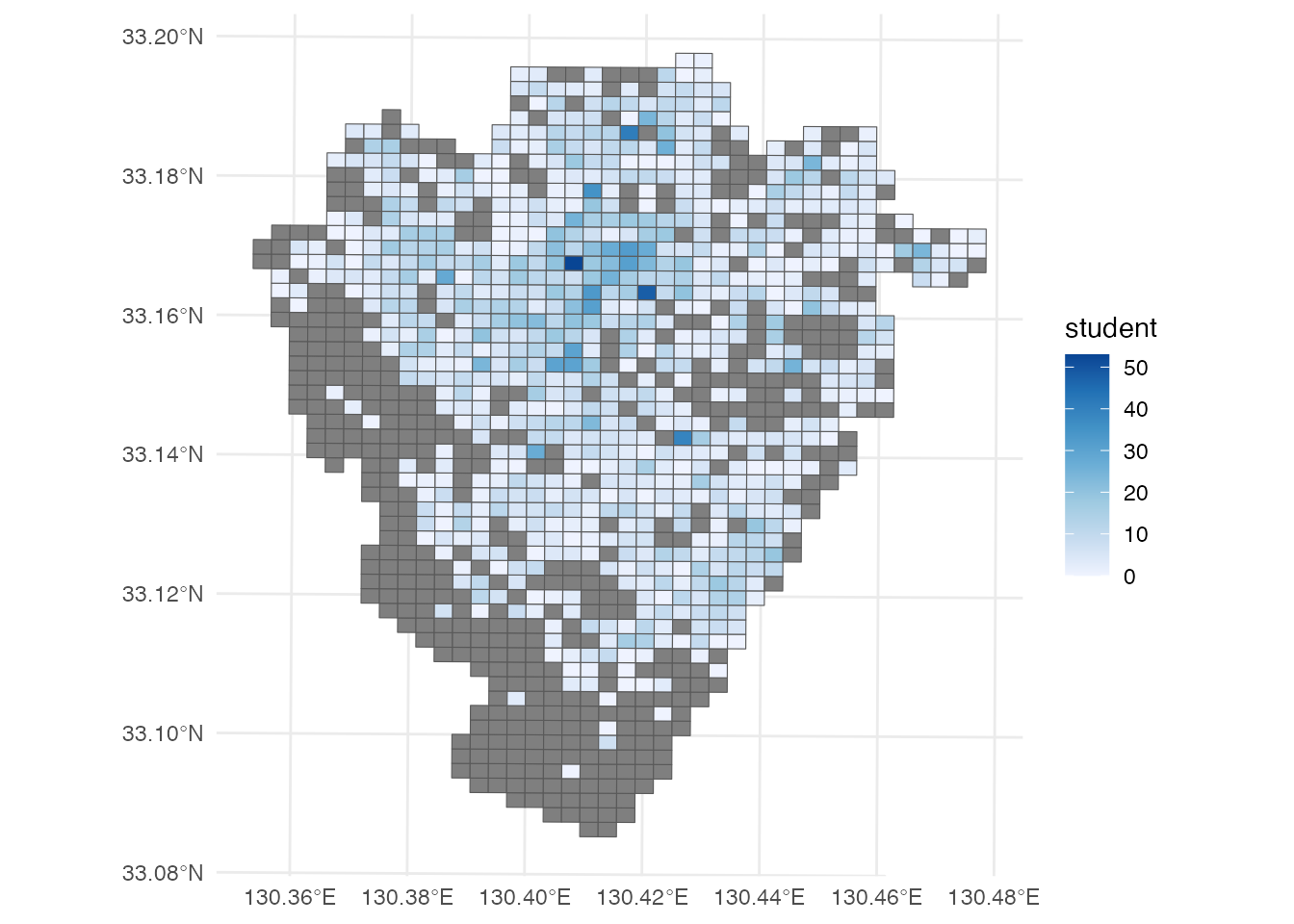
学校ごとの児童数の推計
250mメッシュの人口データを使って分析するわけですが、 このデータは、実際の小学生の人口分布とのずれがあります。 ずれの理由は、(1)人口がメッシュに集約されていることの誤差と、(2)小学生のみのデータではなく小・中学生の合計の人数を使っていることによる誤差です。
ここで、その誤差による影響を確認するために、メッシュ人口を小学校区で集計して、 実際の学校ごとの児童数と比較してみます。
実際の児童数は、 柳川市の小学校の統廃合についてExcelファイルに整理した以下のファイルから入手しましょう。 次のリンクから「yanagawa_es_reog.xlsx」をダウンロードし、dataフォルダに格納してください。
readxl::read_excel関数で読み込みます。
reog_data <- read_excel('data/yanagawa_es_reog.xlsx')「yanagawa_es_reog.xlsx」の中身は、以下のようになっています。 全部で19行のデータがあり、1列目が現在の学校名「name」、2列目が再編後の学校名「new_name」、 そして3列目が2022年度の各校の児童数「student」です。
| name | new_name | student |
|---|---|---|
| 柳河小学校 | 柳城小学校 | 194 |
| 城内小学校 | 柳城小学校 | 185 |
| 東宮永小学校 | 柳城小学校 | 181 |
| 矢留小学校 | 柳南小学校 | 189 |
| 両開小学校 | 柳南小学校 | 155 |
| 昭代第一小学校 | 昭代学校 | 212 |
| 昭代第二小学校 | 昭代学校 | 195 |
| 蒲池小学校 | 蒲池学校 | 326 |
| 皿垣小学校 | 大和小学校 | 60 |
| 有明小学校 | 大和小学校 | 71 |
| 中島小学校 | 大和小学校 | 157 |
| 六合小学校 | 大和小学校 | 119 |
| 大和小学校 | 大和小学校 | 93 |
| 豊原小学校 | 大和小学校 | 154 |
| 藤吉小学校 | 藤吉小学校 | 408 |
| 矢ヶ部小学校 | 三橋小学校 | 107 |
| 二ッ河小学校 | 三橋小学校 | 167 |
| 垂見小学校 | 三橋小学校 | 157 |
| 中山小学校 | 三橋小学校 | 54 |
さて、メッシュ人口を小学校区で集計するわけですが、そのために、まず、メッシュ(ポリゴン)データを、 代表点のポイントデータへと変換します(sf::st_centroid関数を使ってポリゴン重心を代表点にします)。 次に、校区データにポリゴン重心のポイントデータをsf::st_join関数を使って空間結合し、group_by関数とsummarise関数を使って、校区ごとにメッシュ人口を集計します。 その際に、小中学生に占める小学生の比率を2/3として推計することにし、これをestimated列として追加します。 最後に、reog_dataにある児童数を利用するために、left_joinします。
grid_pop <- yngw_grid |> st_centroid()Warning: st_centroid assumes attributes are constant over geometriesschool_pop <- district |> st_join(grid_pop) |>
group_by(A27_004) |>
summarise(estimated = sum(student, na.rm = TRUE) * (2/3)) |>
left_join(reog_data, by = join_by(A27_004 == name))メッシュデータから推計した学校児童数(estimated)と、実際の児童数(student)の散布図を書いてみます。
ggplot(school_pop) +
geom_point(aes(x = student, y = estimated)) +
geom_abline(slope = 1, intercept = 0, color = 'red') +
theme_minimal()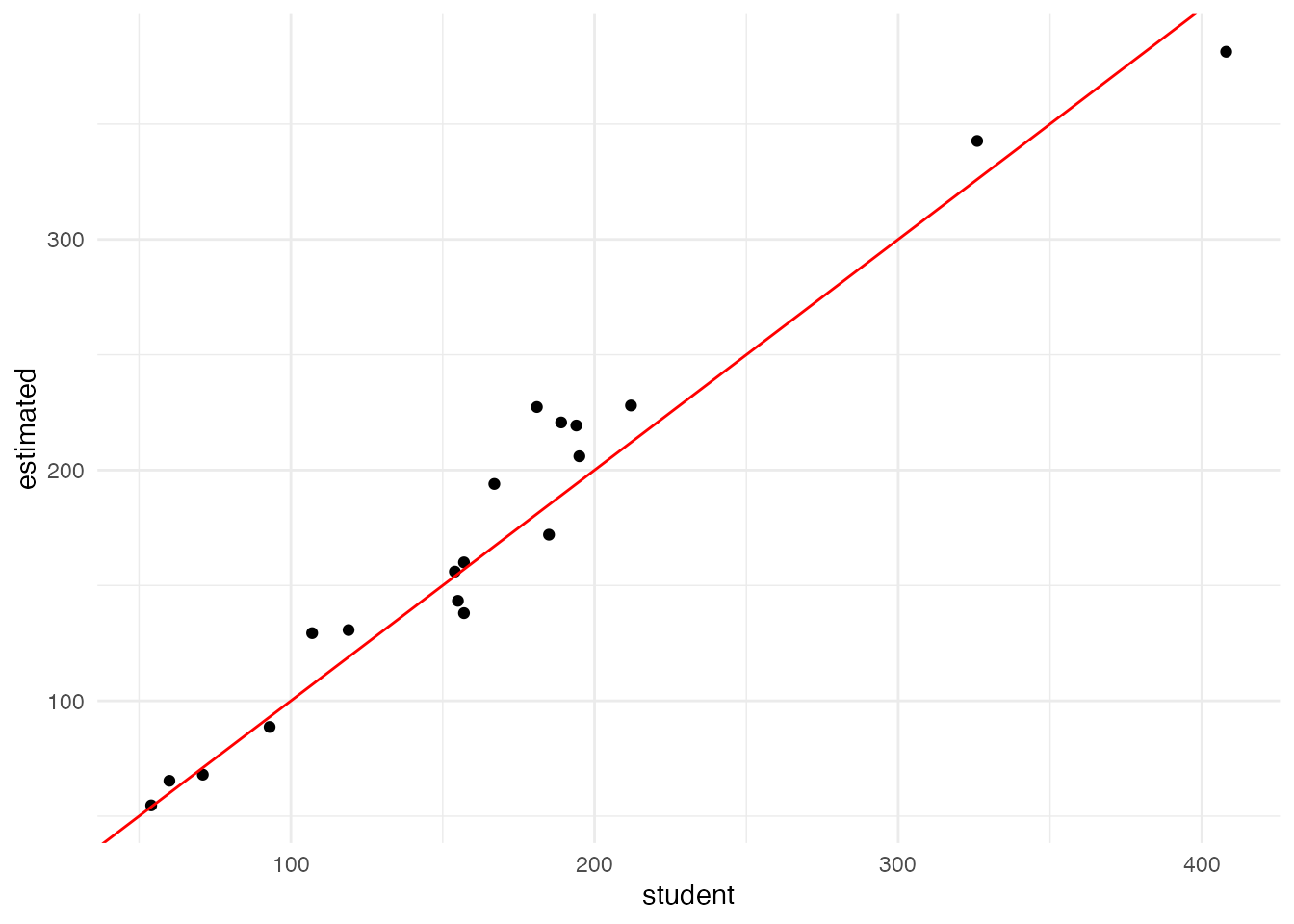
赤い線は、切片0、傾き1の直線(いわゆる45度線)です。 各学校の児童数と推計値が完全に一致すれば、プロットされた点は、この線の上にピッタリ重なります。 図を見ると、19ある小学校の点はほぼ45度線に沿っていて、 良い精度でメッシュ人口から学校ごとの児童数を推定できている、と言えそうです。
距離分布
次に、各メッシュから、校区の小学校までの距離を計測して、生徒の通学距離の分布がどのようになっているのか調べましょう。 そのためには、各メッシュがどの校区に存在するかを調べる必要があります。 この目的のためには、空間結合が使えますね。
準備として、分析対象とするメッシュを、その図形代表点が市域に含まれるものだけにしておきます。 ついでに、メッシュコードの昇順に並び替えておきます。
grid_pop <- grid_pop |>
st_filter(yngw_city) |> arrange(meshcode)
glimpse(grid_pop)Rows: 1,108
Columns: 4
$ grid <grd250> 4930524942, 4930526934, 4930526943, 4930527912, 4930527913…
$ geometry <POINT [m]> POINT (-58468.27 13689.95), POINT (-59038.95 15772.8), …
$ meshcode <chr> "4930524942", "4930526934", "4930526943", "4930527912", "4930…
$ student <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, 0, NA, NA, NA, 1, 2, NA, …次に、各メッシュついて、そのメッシュが含まれる校区の小学校の座標をジオメトリとして持つような空間データを作ります。 校区ポリゴンに、sf::st_join関数を使って、メッシュポリゴンを空間結合します。 そして、メッシュコードの昇順に並び替えます。
grid_school <- district |>
st_join(grid_pop) |>
st_drop_geometry() |>
left_join(school, by = join_by(A27_004 == P29_004)) |>
st_as_sf(crs = 6670) |> arrange(meshcode) |>
select(-starts_with('A27'))
glimpse(grid_school)Rows: 1,108
Columns: 10
$ grid <grd250> 4930524942, 4930526934, 4930526943, 4930527912, 4930527913…
$ meshcode <chr> "4930524942", "4930526934", "4930526943", "4930527912", "4930…
$ student <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, 0, NA, NA, NA, 1, 2, NA, …
$ P29_001 <chr> "40207", "40207", "40207", "40207", "40207", "40207", "40207"…
$ P29_002 <chr> "B140220700059", "B140220700077", "B140220700077", "B14022070…
$ P29_003 <int> 16001, 16001, 16001, 16001, 16001, 16001, 16001, 16001, 16001…
$ P29_005 <chr> "柳川市有明町1750", "柳川市西浜武1490", "柳川市西浜武1490", "…
$ P29_006 <int> 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3…
$ P29_007 <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ geometry <POINT [m]> POINT (-56644.28 14559.01), POINT (-57493.66 18642.29),…メッシュ代表点と学校との距離をsf::st_distanceを使って計測します。 計測した距離を、dplyr::mutate関数を使って、 grid_distというデータフレームの新しいデータ列distanceとして追加します。 その中で、studentの値がNAでない行だけを抽出しています。
grid_school_dist <- grid_pop |>
mutate(distance = st_distance(grid_pop, grid_school, by_element = TRUE) |>
units::drop_units()) |>
filter(!is.na(student))この新しいデータフレームを使って、メッシュから学校までの距離の生徒数の重みつきヒストグラムを描いてみましょう。
ggplot(grid_school_dist) +
aes(x = distance, weight = student) +
geom_histogram(boundary = 0, binwidth = 200,
color = grey(0.2), fill = grey(0.8)) +
theme_minimal()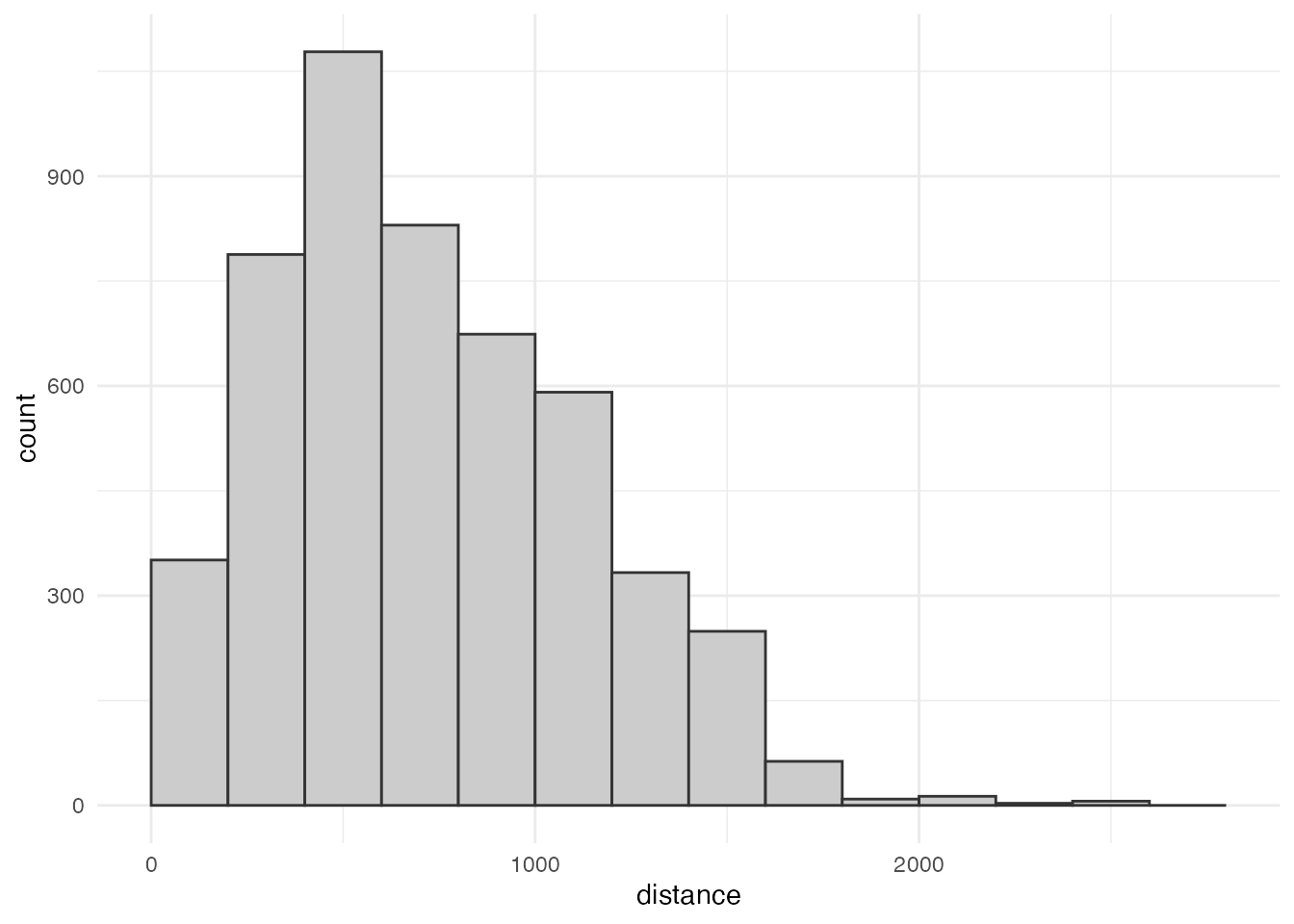
school_dist <- grid_school_dist |>
arrange(distance) |>
mutate(count = cumsum(student))
ggplot(school_dist, aes(x = distance, y = count)) +
geom_line() +
theme_minimal()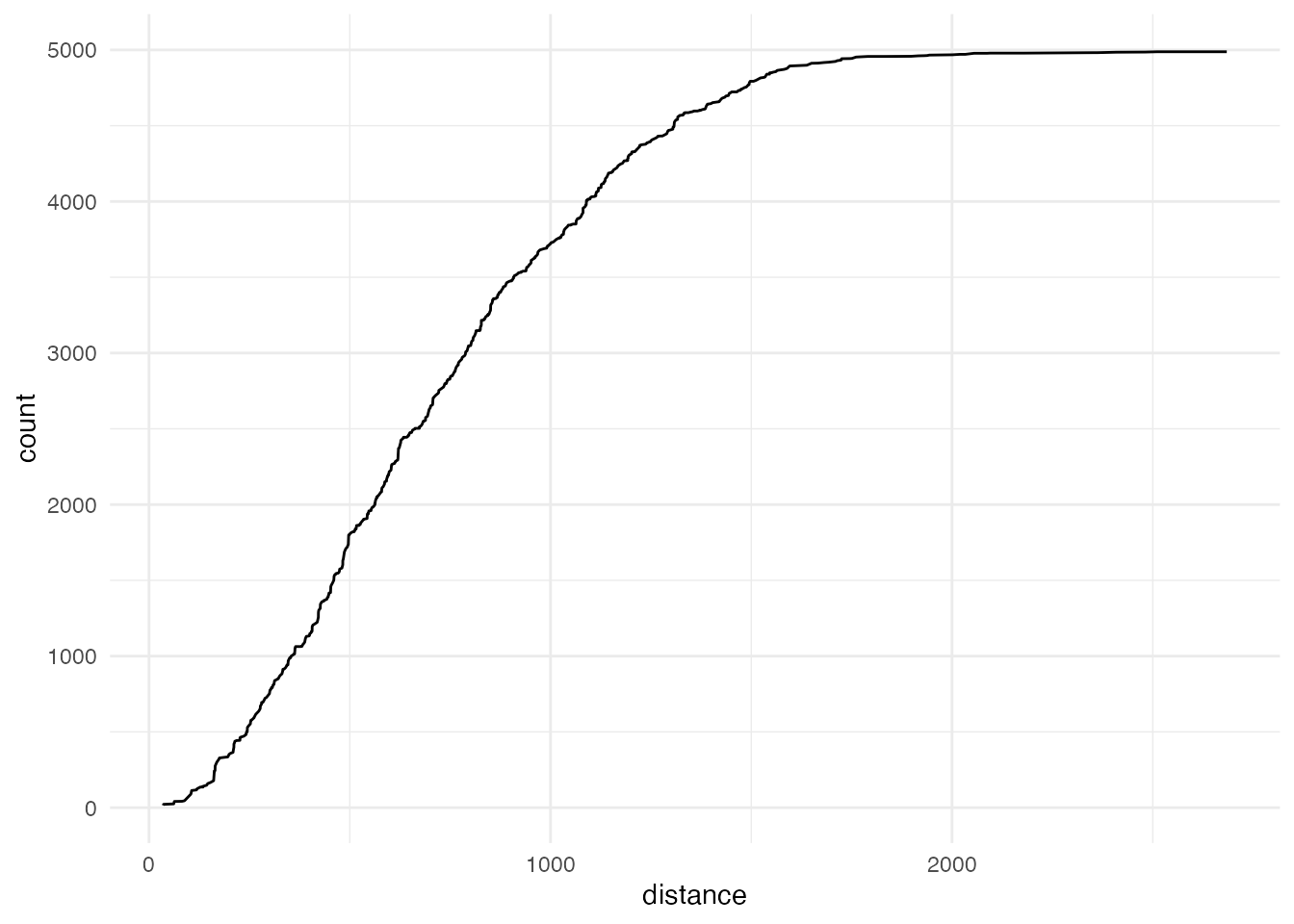
ほとんどの児童の学校までの距離は1,800 mより短く、 学校までの直線距離が2 kmを超える児童の割合は全体の0.4%程度です。
距離の平均値も計算しておきましょう。
weighted.mean(x = grid_school_dist$distance,
w = grid_school_dist$student)[1] 725.4602平均距離は約725 mという結果になりました。
ボロノイ図
空間上に同種とみなすことができる点が複数分布しているとき、 それぞれを最寄りの点とする領域として空間を分割する操作を、ボロノイ分割と呼びます。 そして、ボロノイ分割によって得られた図形全体をボロノイ図と呼びます。
この演習では、小学校を母点として、柳川市を最寄りの小学校によって空間的に分割する操作を考えます。 Rでは、sf::st_voronoi関数でボロノイ分割を実行することができます。
voronoi <- school |>
st_union() |> st_voronoi() |>
st_collection_extract(type = "POLYGON") |>
st_intersection(yngw_city) |> st_sf() |>
st_join(school)sfパッケージの関数をたくさん利用しています。 まず初めに、小学校のポイントデータであるschoolに対して、 sf::st_union関数を使って、sfc_MULTIPOINTに変換しています。 この操作によってできたオブジェクトをsf::st_voronoi関数に入力として与えると、ボロノイ図が作成されます。 この結果から、sf::st_collection_extract関数によってポリゴンを取り出し、 sf::st_sf関数でsfオブジェクトに変換します。 最後に小学校のポイントデータであるschoolを再びsf::st_joinで空間結合して、それぞれのボロノイ領域がどの小学校に対応する領域なのかがわかるようにしています。
それでは、小学校を母点とするボロノイ図を、小学校区と合わせて表示してみましょう。
ggplot() +
geom_sf(data = district) +
geom_sf(data = voronoi, fill = NA, linetype = 'dashed') +
geom_sf(data = school) +
theme_minimal()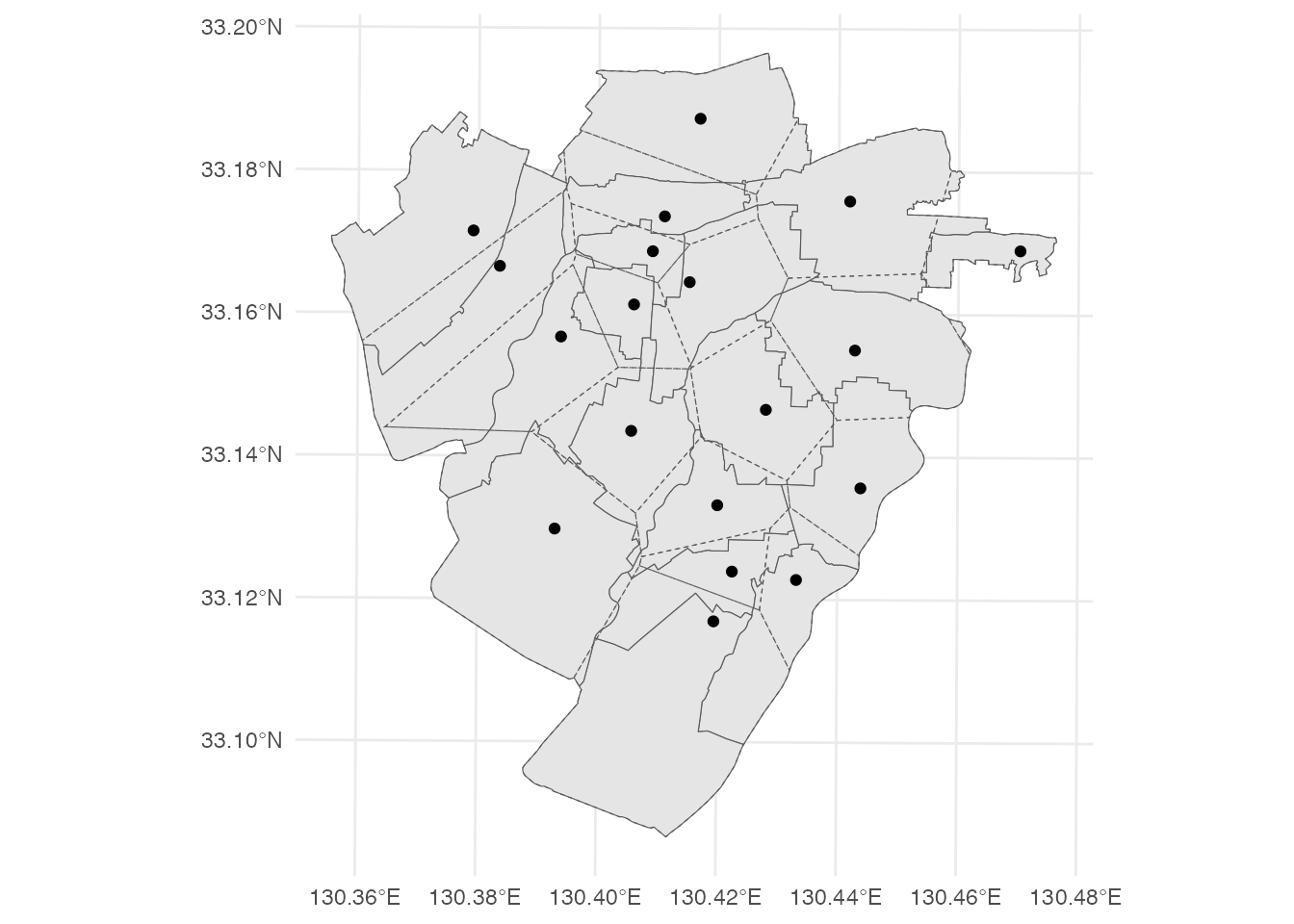
小学校区とボロノイ図は、おおよそ似た形をしていますが、細かいところを見ると、一致しているわけではありません。 両者の成り立ちを考えれば、もちろん一致することはないのですが、どの程度一致しているのかを見ることには、意味があるかもしれません。
小学校区とボロノイ図との乖離の程度見るために、sf::st_intersection関数を使って両者の交叉を求め、校区の小学校とボロノイ領域の母点の小学校が異なる領域を抽出します。
difference <-
st_intersection(district, voronoi) |>
filter(A27_004 != P29_004)Warning: attribute variables are assumed to be spatially constant throughout
all geometriesこの領域は、いわば、直線距離で見ればもっと近い小学校があるにもかかわらず、その小学校に通学することができない地域であることを意味します。 そのような地域を地図に表示してみましょう。
ggplot() +
geom_sf(data = yngw_city) +
geom_sf(data = difference, fill = 'orange') +
theme_minimal()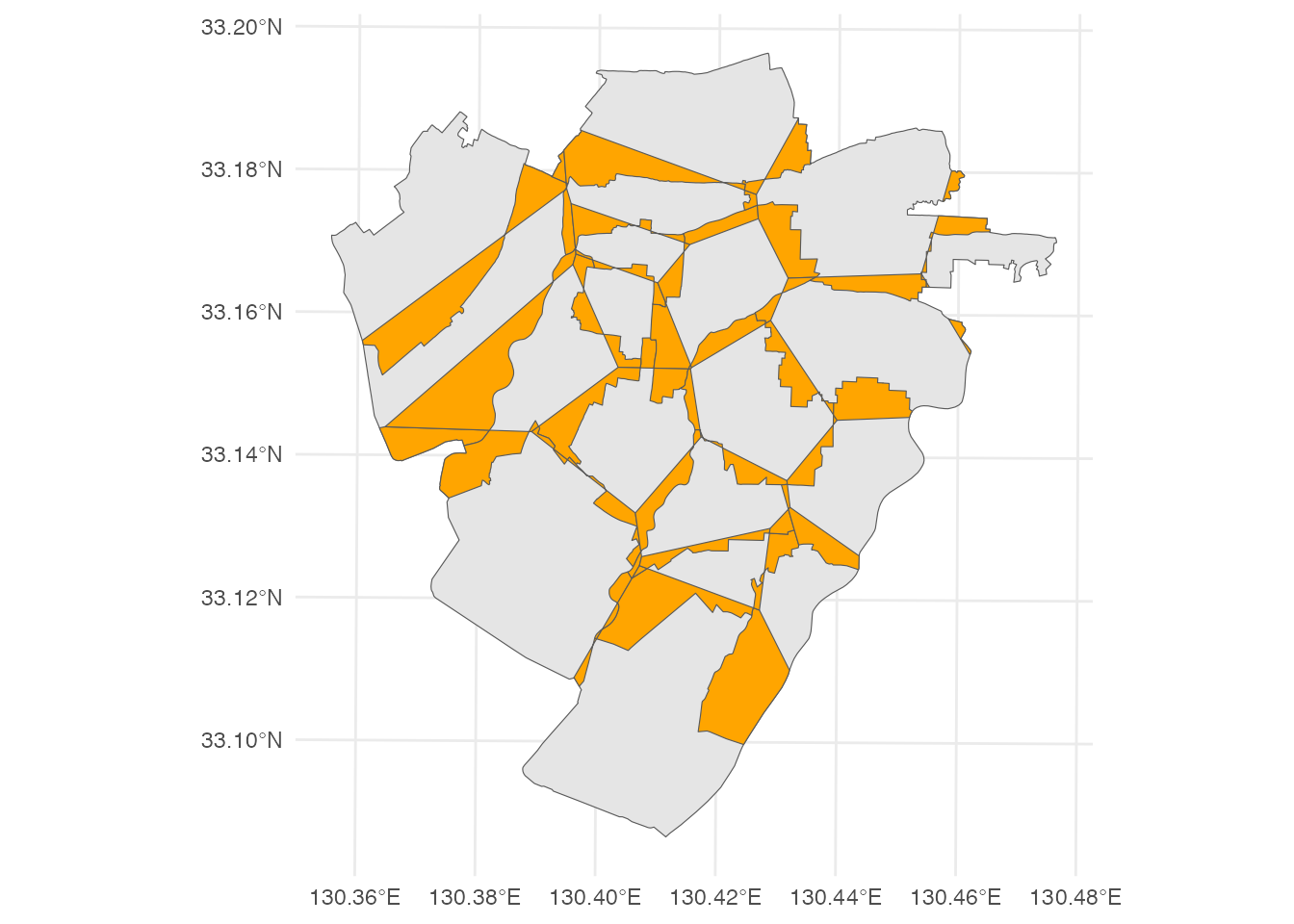
このオレンジ色で塗られた領域の、市域に対する面積比率を求めてみましょう。
sum(st_area(difference)) / st_area(yngw_city) * 10022.61376 [1]約22.6%です。思ったよりも多いな、と感じたかもしれません。
では、この「最も近い小学校に通えないことが通学距離に与える影響」を見積もってみましょう。 先ほど、小学校区のポリゴンデータを使って、学校までの距離の分布と平均を計算しました。 小学校区のポリゴンデータの代わりに、ボロノイ領域のポリゴンデータを使って、同じ計算をした上で、両者を比較すれば良さそうです。
grid_voronoi <- voronoi |>
st_join(grid_pop) |>
st_drop_geometry() |>
left_join(school) |>
st_as_sf(crs = 6670) |> arrange(meshcode)Joining with `by = join_by(P29_001, P29_002, P29_003, P29_004, P29_005,
P29_006, P29_007)`glimpse(grid_voronoi)Rows: 1,108
Columns: 11
$ P29_001 <chr> "40207", "40207", "40207", "40207", "40207", "40207", "40207"…
$ P29_002 <chr> "B140220700059", "B140220700059", "B140220700059", "B14022070…
$ P29_003 <int> 16001, 16001, 16001, 16001, 16001, 16001, 16001, 16001, 16001…
$ P29_004 <chr> "両開小学校", "両開小学校", "両開小学校", "両開小学校", "昭代…
$ P29_005 <chr> "柳川市有明町1750", "柳川市有明町1750", "柳川市有明町1750", "…
$ P29_006 <int> 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3…
$ P29_007 <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ grid <grd250> 4930524942, 4930526934, 4930526943, 4930527912, 4930527913…
$ meshcode <chr> "4930524942", "4930526934", "4930526943", "4930527912", "4930…
$ student <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, 0, NA, NA, NA, 1, 2, NA, …
$ geometry <POINT [m]> POINT (-56644.28 14559.01), POINT (-56644.28 14559.01),…ボロノイ領域内にあるメッシュについて、ボロノイ領域の母点までの距離を計算します。
grid_voronoi_dist <- grid_pop |>
mutate(distance = st_distance(grid_pop, grid_voronoi, by_element = TRUE) |>
units::drop_units()) |>
filter(!is.na(student))ボロノイ領域による距離分布を計算し、ヒストグラムにしてみます。
ggplot() + aes(x = distance, weight = student) +
geom_histogram(data = grid_voronoi_dist,
boundary = 0, binwidth = 200,
color = 'red', fill = "white") +
theme_minimal()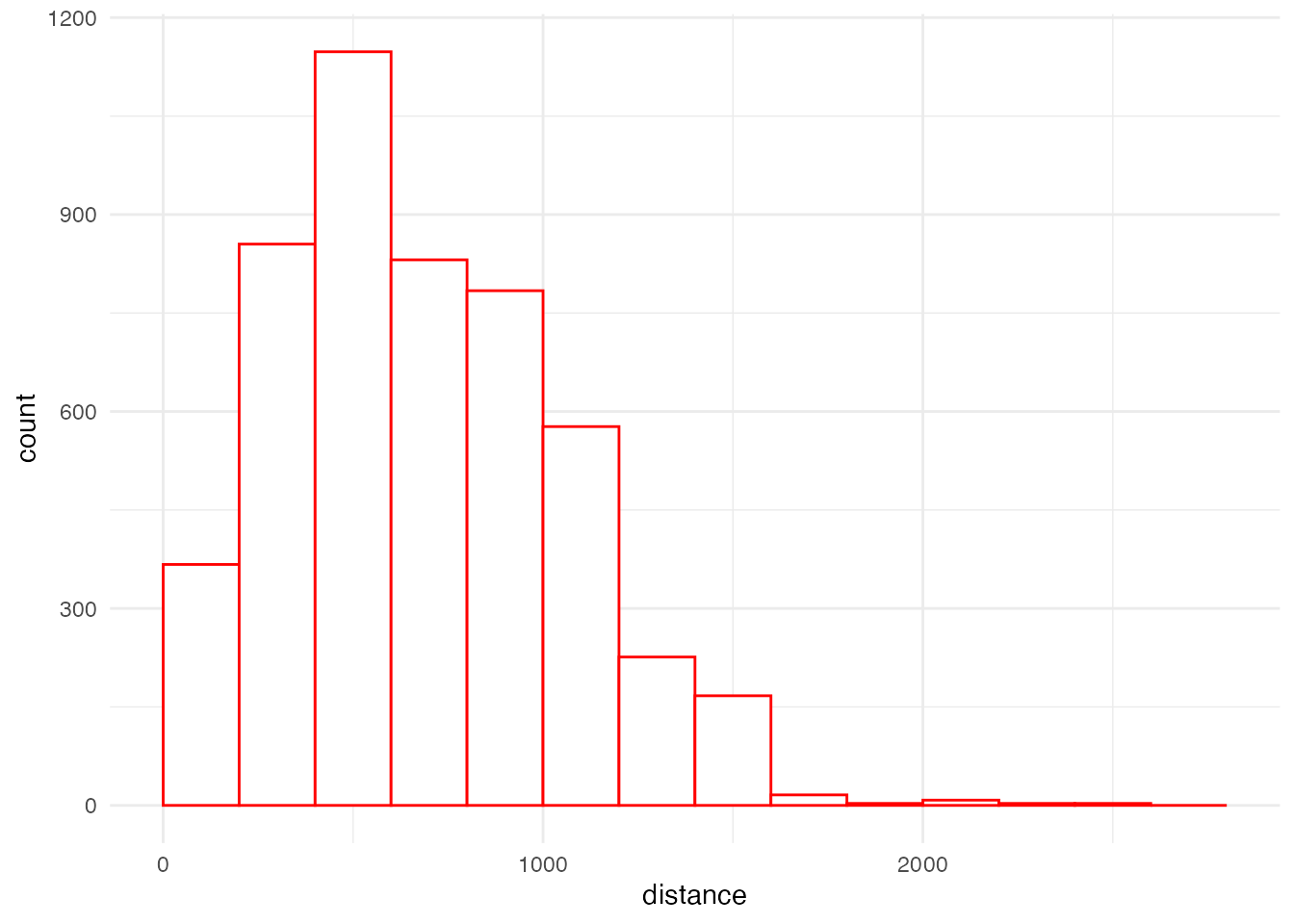
小学校区による距離分布と重ねて表示すると、こんな感じになります。
ggplot() + aes(x = distance, weight = student) +
geom_histogram(data = grid_school_dist,
boundary = 0, binwidth = 200,
color = grey(0.2), fill = grey(0.8),) +
geom_histogram(data = grid_voronoi_dist, alpha = 0.5,
boundary = 0, binwidth = 200,
color = 'red', fill = NA) +
theme_minimal()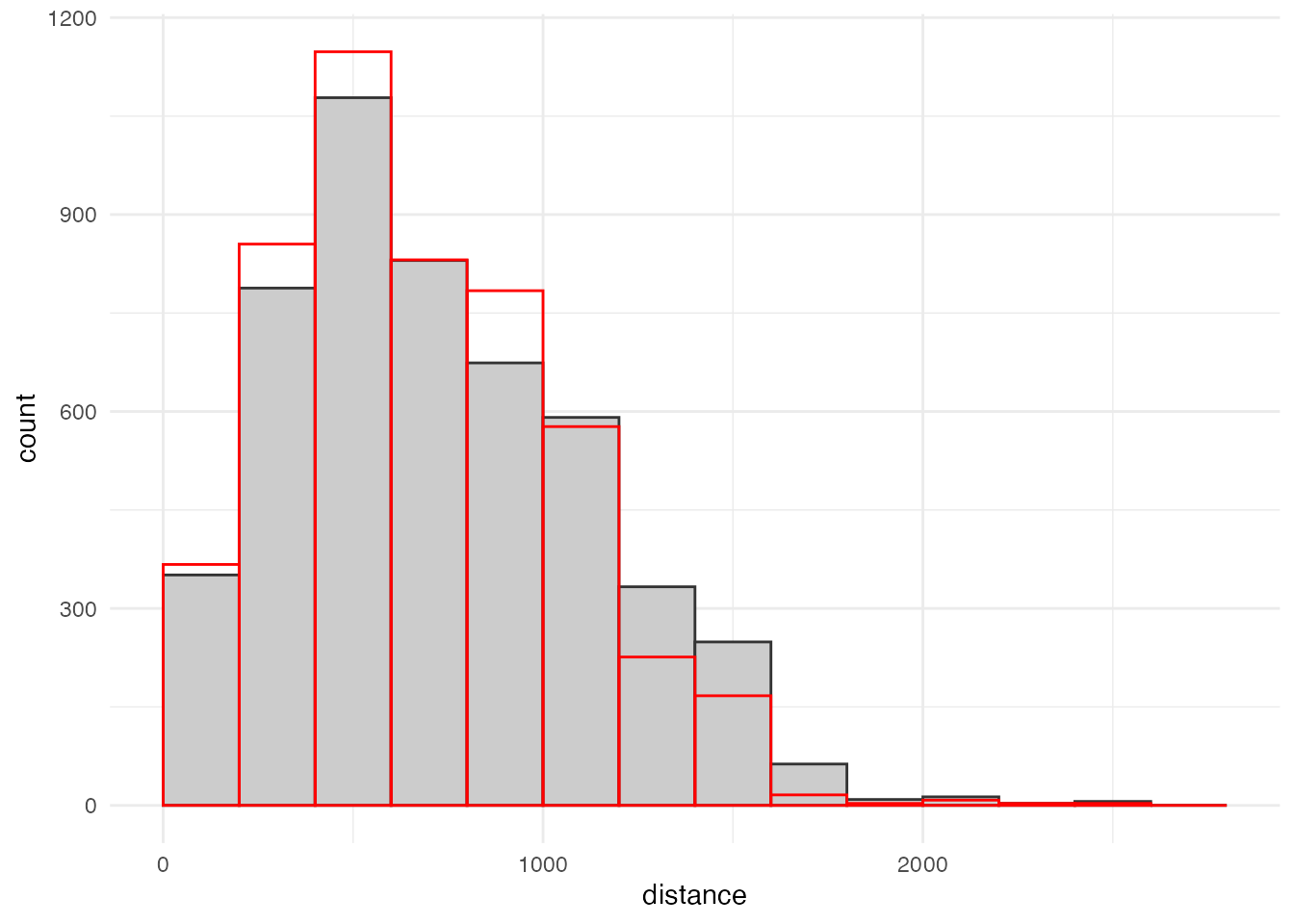
小学校からの距離が1,200〜1,800 mの人が減って、 200〜600 m、800〜1,000 mの人が増えている様子が確認できます。
累積距離分布も比較しておきましょう。
voronoi_dist <- grid_voronoi_dist |>
arrange(distance) |>
mutate(count = cumsum(student))
ggplot() + aes(x = distance, y = count) +
geom_line(data = school_dist) +
geom_line(data = voronoi_dist, color = 'red') +
theme_minimal()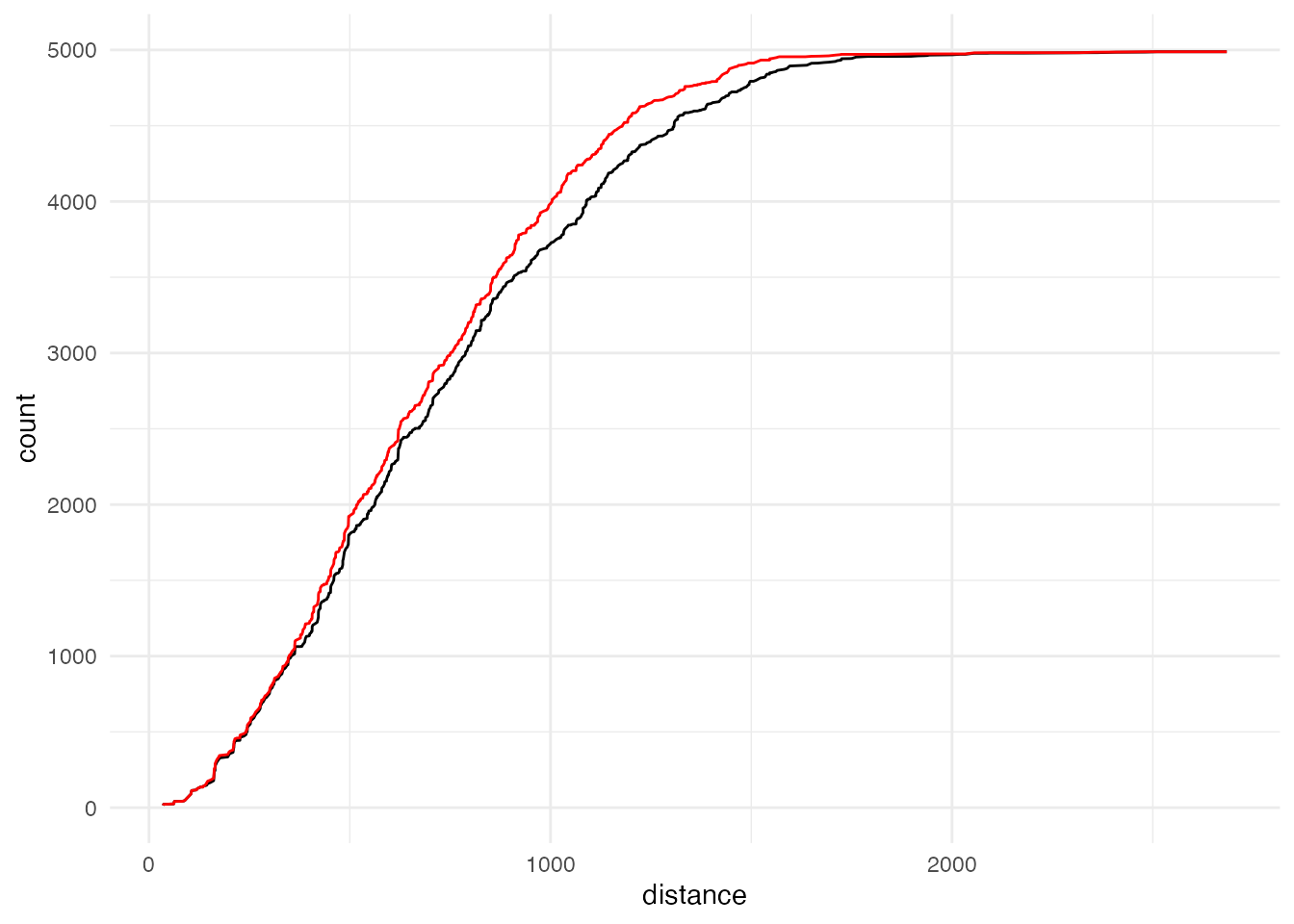
実際の小学校区による累積距離分布のほうが、ボロノイ図による分布よりも少し右側、すなわち距離が長い方向にシフトしていることがわかります。 ボロノイ図による通学距離というのは、全ての生徒が一番近い学校に通っている状態ですから、これ以上距離を短くすることはできません。 したがって、現状の人口分布と学校の立地を所与としたときには、どのような校区を考えても、赤い線よりも左に線が引かれることはありません。
平均値距離も計算しておきましょう。
weighted.mean(x = grid_voronoi_dist$distance,
w = grid_voronoi_dist$student)[1] 678.1559平均距離は約678 mという結果になりました。 全員が最も近い小学校に通うことで、 平均通学距離をおよそ6.5%短縮できる可能性がある、という結果になりました。
実際の校区設定は、通学距離だけでなく、さまざまな要素を考慮して決定されているものと思われます。 例えば、児童を受け入れる側の小学校のキャパシティもその1つでしょう。 仮に、小学校区をボロノイ領域に一致するように設定した場合、 各学校の児童数はどのようになるかを計算しておくことは有用だと思います。
voronoi_pop <- grid_voronoi |>
group_by(P29_004) |>
summarise(estimated = sum(student, na.rm = TRUE) * (2/3)) |>
right_join(reog_data, by = join_by(P29_004 == name))現在の小学校の児童数と、学区を変更した場合の推計児童数を散布図にしてみます。
ggplot(voronoi_pop) +
geom_point(aes(x = student, y = estimated)) +
geom_abline(slope = 1, intercept = 0, color = 'red') +
theme_minimal()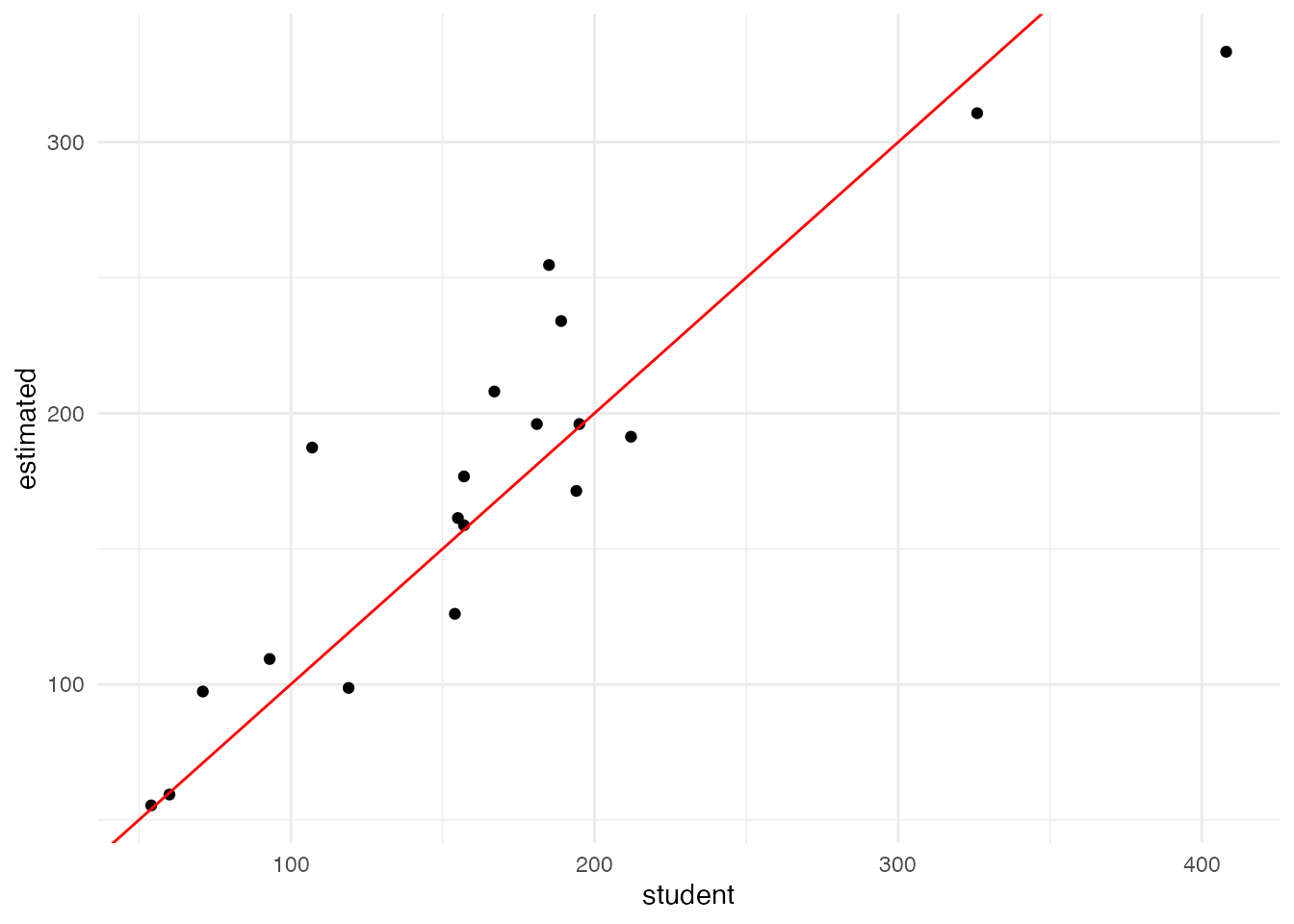
45度線上に点があれば、児童数の変化がない、ということです。 図を見ると、学校あたり数十人程度の増減があり、その影響は小さくないようです。
統廃合の影響評価
柳川市の小中学校再編計画では、 現在19校ある小学校を、5校の小学校そして2校の義務教育学校(小中一貫校)に再編する計画になっています。 現在19校ある学校を、7校に減らすわけですから、その影響とても大きいことが予想されます。 では、どのくらいの影響があるのか、通学距離に絞って、定量的に見積もってみましょう。
将来の小学校区の可視化
再編後の小学校区は、現在の小学校区の組み合わせで構成されています。 ですので、現在の小学校区のデータを組み合わせて、将来の校区のデータを作ることが可能です。
まず、現在の校区データ(district)に、学校再編の情報(reog_data)を結合します。 結合にはdplyr::left_join関数を使います。結合のキーには学校名称を使うので、 dplyr::join_by関数でそれぞれのデータフレームにおいて学校名が入っている列名を指定しています。
結合したデータにある、将来の小学校名を使って、校区データを(空間的に)集計します。 dplyr::group_by関数を使って、新しい学校名でグルーピングしたあと、dplyr::summarise関数で集計します。
new_district <- district |>
left_join(reog_data, by = join_by(A27_004 == name)) |>
group_by(new_name) |> summarise()将来の小学校の位置データも作成しましょう。 柳川市の小中学校再編計画では、将来の小中学校の位置は、現在ある小中学校の敷地を活用することになっています。
将来の小学校について、現在のどの学校の敷地を利用するかを表に整理したものを、 先ほどダウンロードしたExcelファイルの2つ目のシート(シート名:location)にしてありますので、これを読み込んで利用しましょう。
location <-
read_excel("data/yanagawa_es_reog.xlsx", sheet = "location")locationの内容は、以下のようになっています。
| new_name | location |
|---|---|
| 柳城小学校 | 城内小学校 |
| 柳南小学校 | 柳南中学校 |
| 昭代学校 | 昭代第二小学校 |
| 蒲池学校 | 蒲池小学校 |
| 大和小学校 | 大和中学校 |
| 藤吉小学校 | 藤吉小学校 |
| 三橋小学校 | 三橋中学校 |
これは、例えば、新しい「柳城小学校」は、現在の「城内小学校」の敷地を利用することを意味しています。 これを使って、国土数値情報の学校データから、柳川市の将来の小学校(ポイント)データを作成しましょう。
new_school <-
st_read("data/P29-21_40_GML/P29-21_40.geojson") |>
filter(P29_001 == "40207", P29_004 %in% location$location) |>
left_join(location, by = join_by(P29_004 == location)) |>
select(new_name, geometry)Reading layer `40' from data source
`/Users/kzktmr/Documents/LectureNotes/data/P29-21_40_GML/P29-21_40.geojson'
using driver `GeoJSON'
Simple feature collection with 2019 features and 7 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: 130.0358 ymin: 33.0043 xmax: 131.1884 ymax: 33.99281
Geodetic CRS: JGD20111行目は、sf::st_read関数で学校のGeoJSONファイルを読み込んでいます。 2行目は、filter関数を使って、柳川市の学校のうち、将来の小学校敷地として利用される学校 のデータだけを抜き出しています。 3行目は、left_join関数を使って、現在の学校名称(P29_004とlocation)をキーにして、将来の学校名称を結合しています。 4行目は、select関数を使って、将来の学校名称と位置情報(緯度経度)の列だけを残しています。
作成した将来の小学校区と将来の小学校の位置を、地図に重ねて表示します。 19あった小学校が7校に減るわけですから当たり前なんですけど、校区の規模が大きくなっています。
ggplot() +
geom_sf(data = new_district) +
geom_sf(data = new_school) +
theme_minimal()
通学距離の変化を見積もる
将来の小学校区のデータを使って、小学校の再編が通学距離に与える影響を見積もってみましょう。
作業内容としては、現在の小学校区の学校までの距離を測る作業と全く同じ方法を使って、 将来の小学校区における学校までの距離を計測します。 そして、現在と将来の通学距離の分布を比較する、という手順になります。
new_grid_school <- new_district |>
st_join(grid_pop) |> st_drop_geometry() |>
left_join(new_school, by = join_by(new_name)) |>
st_as_sf() |> st_transform(6670) |>
arrange(meshcode)各メッシュから、将来の校区の小学校までの距離を計測します。
new_grid_school_dist <- grid_pop |>
mutate(distance = st_distance(grid_pop, new_grid_school,
by_element = TRUE) |>
units::drop_units()) |>
filter(!is.na(student))距離分布のグラフを書いてみましょう。 長い距離を通学する児童が増えるので、裾が広い分布になります。
ggplot(new_grid_school_dist) +
aes(x = distance, weight = student) +
geom_histogram(alpha = 0.2, boundary = 0, binwidth = 200,
color = 'blue', fill = 'blue') +
theme_minimal()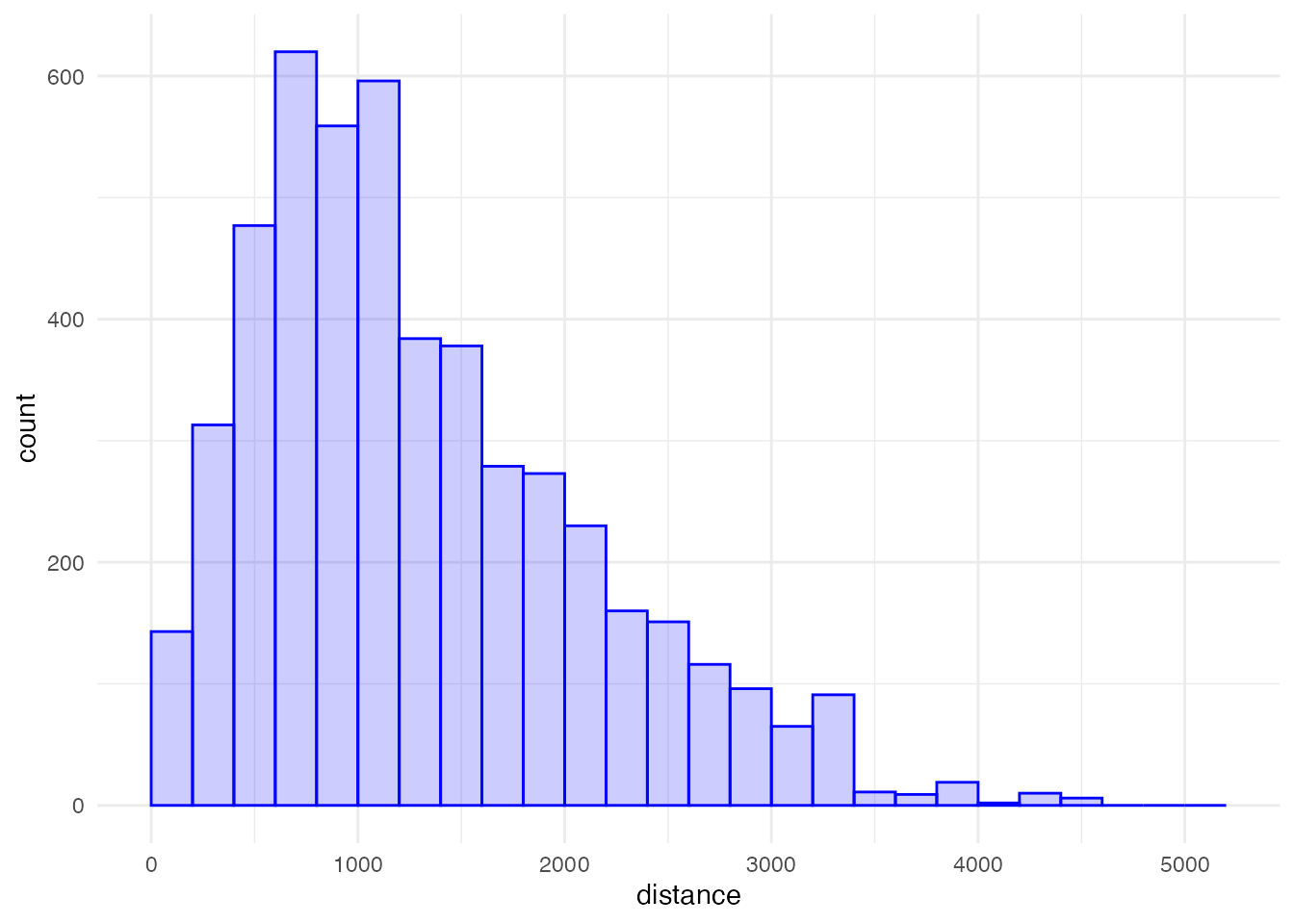
累積分布はこのようになります。 学校までの直線距離が1,000 m以下の児童は全体の40%強、2,000 mを超える児童がおよそ20%いることがわかります。 最も学校が遠い人では、その距離は5 kmを超えます。
new_school_dist <- new_grid_school_dist |>
arrange(distance) |>
mutate(count = cumsum(student))
ggplot(new_school_dist, aes(x = distance, y = count)) +
geom_line(color = "blue") +
theme_minimal()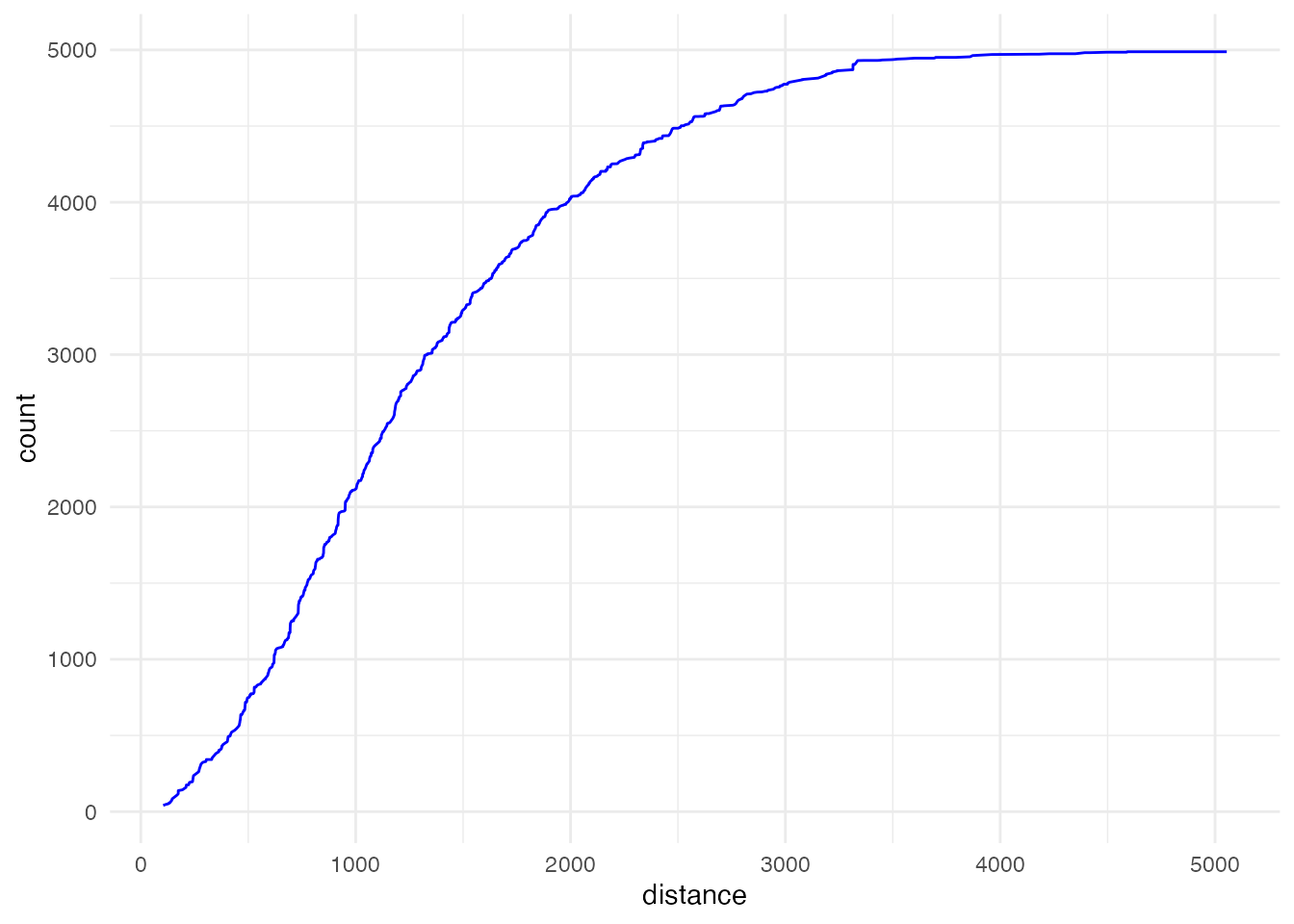
現在の学校配置における距離分布と重ねてみましょう。 グレーのグラフが現在の小学校区における距離分布、青色のグラフが将来の小学校区における距離分布です。 この図からも、小学校の統廃合によって、学校までの距離が1,000m以下の人数が大きく減り、 1,500m以上の人数が大きく増えることが確認できます。
ggplot() + aes(x = distance, weight = student) +
geom_histogram(data = grid_school_dist,
boundary = 0, binwidth = 200,
color = grey(0.2), fill = grey(0.8),) +
geom_histogram(data = new_grid_school_dist, alpha = 0.2,
boundary = 0, binwidth = 200,
color = 'blue', fill = 'blue') +
theme_minimal()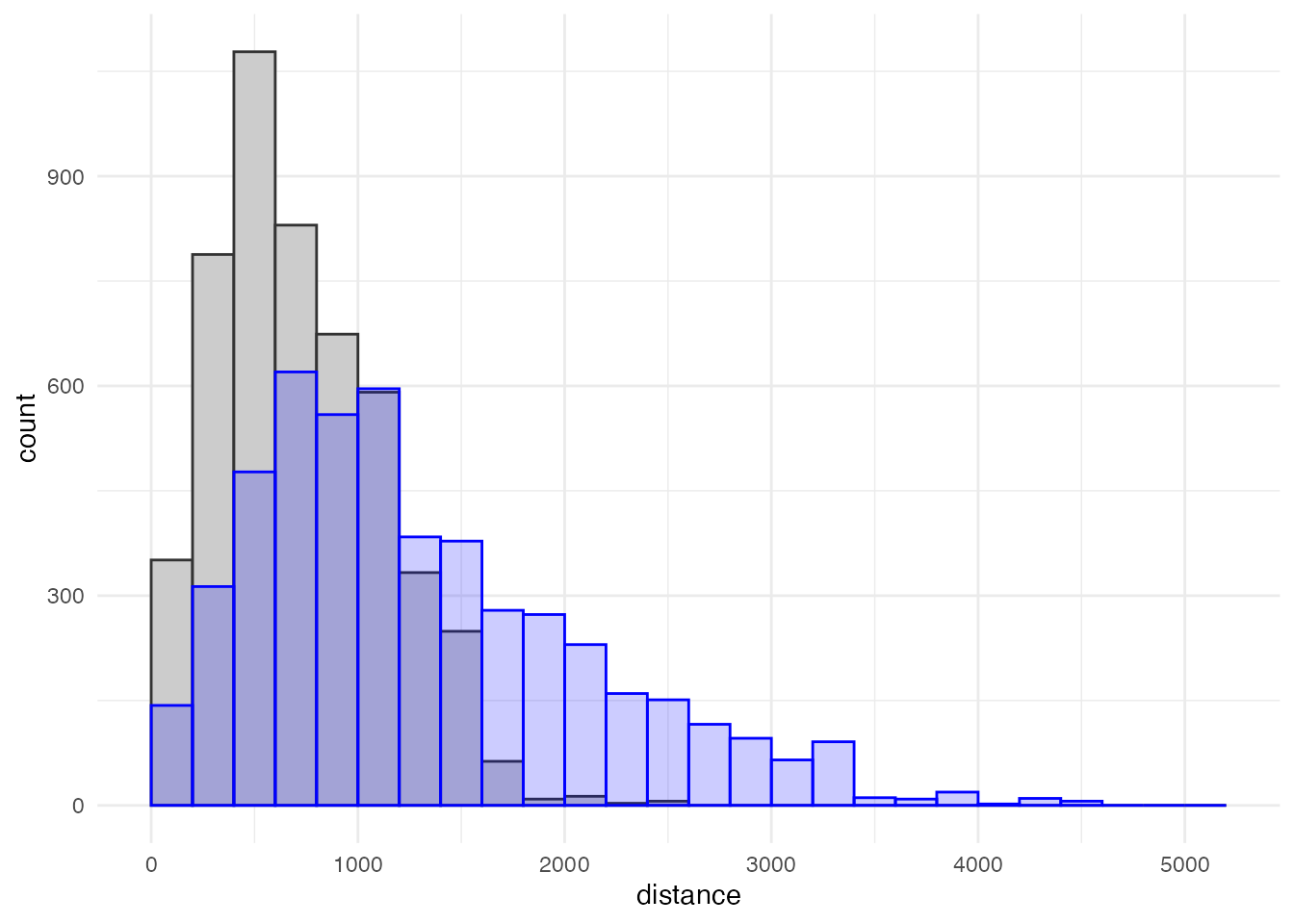
累積距離分布も比較しておきましょう。 言うまでもなく、青色の線が、将来の学校配置による分布です。 距離が伸びる方向に大きくシフトしていることがわかります。
new_school_dist <- new_school_dist |>
arrange(distance) |>
mutate(count = cumsum(student))
ggplot() + aes(x = distance, y = count) +
geom_line(data = school_dist) +
geom_line(data = voronoi_dist, color = 'red') +
geom_line(data = new_school_dist, color = 'blue') +
theme_minimal()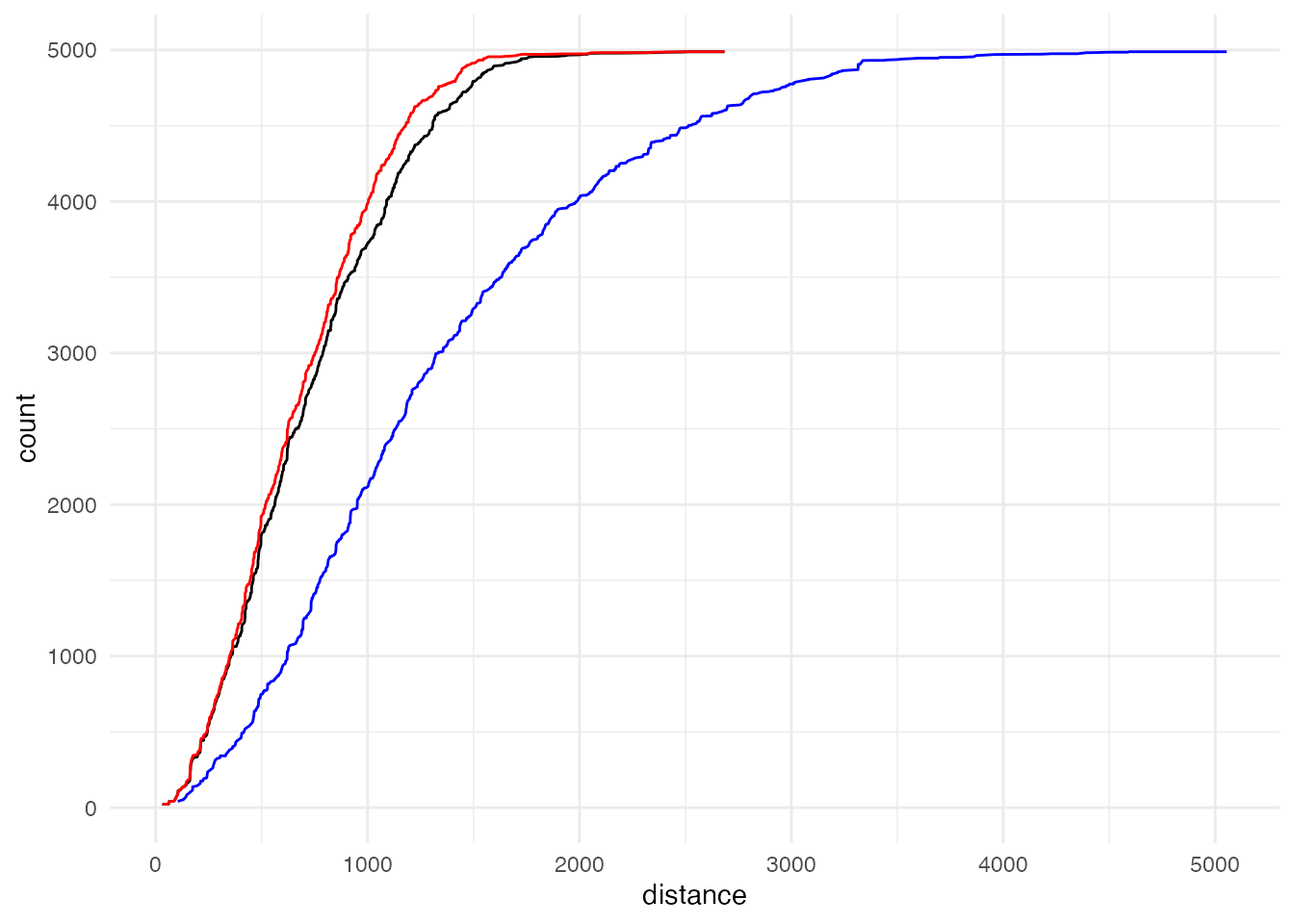
平均距離も、1311 mとなり、小学校の再編で平均的な通学距離は現在の約1.8倍になると推測されます。
weighted.mean(new_school_dist$distance, new_school_dist$student)[1] 1311.4おわりに
今回の分析例では、小学校の統廃合により、学校までの平均距離が1.8倍になるという結果になりました。 このように、空間データを使って定量的な分析を行うと、政策の影響を数字で評価できるようになります。
19校を7校に減らしたということの影響だけでなく、7校の立地場所としてどこを選ぶかや、校区をどのように設定するかの影響も大きいと思います。 また、柳川市では「通学距離が概ね2 kmを超える場合は、スクールバス等の運行を検討」するとしています。
それぞれ政策の影響を定量的に評価するには、どのような分析を行えばよいか、ぜひ皆さんも考えてみてください。